当前位置:网站首页>【Image Classification】2022-ResMLP
【Image Classification】2022-ResMLP
2022-08-10 03:32:00 【say】
文章目录
【图像分类】2022-ResMLP
论文题目:ResMLP: Feedforward networks for image classification with data-efficient training
论文链接:https://arxiv.org/abs/2105.03404
论文代码:https://github.com/facebookresearch/deit
论文翻译:https://blog.csdn.net/u014546828/article/details/120730429
发表时间:2021年5月
引用:Touvron H, Bojanowski P, Caron M, et al. Resmlp: Feedforward networks for image classification with data-efficient training[J]. arXiv preprint arXiv:2105.03404, 2021.
引用数:87
1. 简介
1.1 摘要
研究内容:This paper proposes a multilayer perceptron-based image classification architecture ResMLP.
方法介绍:It is a simple residual network,它可以替代
(i) 一个线性层,where the image patches interact independently and identically across channels,以及
(ii)一个两层前馈网络,where each channel interacts independently between each patch.
实验结论:当使用Use massive data augmentation and selective distillationof modern training strategies when training,它在 ImageNet obtained amazing accuracy/复杂度折衷.
This paper is also trained in a self-supervised setting ResMLP 模型,to further remove priors using labeled datasets.
最后,By applying the model to machine translation,Surprisingly good results were obtained.
1.2 介绍
综上所述,The following observations are made in this paper:
• 尽管很简单,ResMLP 在仅 ImageNet-1k Striking accuracy is achieved in the training case/复杂性,without the need for normalization based on batch or channel statistics;
• These models benefit significantly from distillation methods;Compatible with self-supervised learning methods based on data augmentation,如 DINO [7];
• 在机器翻译的 WMT 基准测试中,与 seq2seq transformer 相比,seq2seq ResMLP 实现了具有竞争力的性能.
2. 网络
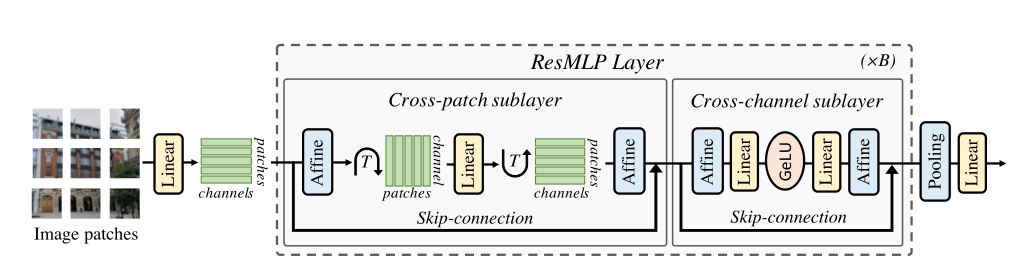
2.1 整体网络
ResMLP的网络结构如上图所示,The input to the network is also a seriespatch emmbeddings,The basics of the modelblock包括一个linear层和一个MLP,其中linear层完成patchs间的信息交互,而MLP则是各个patch的channel间的信息交互(就是原始transformer中的FFN):
以图像 patch 为输入,Project it as a linear layer,
ResMLP,以 N × N N×N N×N个不重叠的 patch composed grid as input,其中 patch The size is usually equal to 16 × 16 16×16 16×16.然后,这些 patches Independently through a linear layer,形成一组 N 2 N^2 N2d维的embeddings.
Then its representation is sequentially updated through two residual operations:
(i) 一个跨 patch 线性层,Applied independently to all channels;
(ii) A single layer across channels MLP,Independently applied to all patch .
at the end of the network,patch Represents average pooling,
and fed into a linear classifier.
It can also be understood by changing the picture
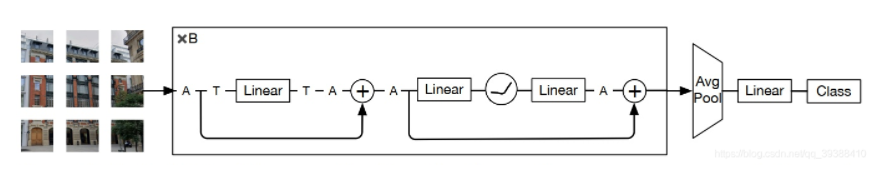
2.2 Residual Multi-Perceptron Layer .
1) Aff操作(归一化操作)
ResMLP并
没有采用LayerNorm,而是采用了一种Affine transformation来进行norm,这种normThe way doesn't need to be likeLayerNormCalculate the statistic that way for normalization,Instead, use the two learned parameters directlyα和β做线性变换:
self-attention The absence of layers makes training more stable,Allows replacing layer normalization with a simpler affine transformation,Radiation transformation as formula (1) 所示.其中 α \alpha α和 β \beta βis a learnable weight vector.This operation scales and moves the input element only.
Aff α , β ( x ) = Diag ( α ) x + β \operatorname{Aff}_{\boldsymbol{\alpha}, \boldsymbol{\beta}}(\mathbf{x})=\operatorname{Diag}(\boldsymbol{\alpha}) \mathbf{x}+\boldsymbol{\beta} Affα,β(x)=Diag(α)x+β
与其他归一化操作相比,This operation has several advantages:
- 首先,与 Layer Normalization 相比,It has no cost in inference time,Because it can be absorbed by adjacent linear layers.
- 其次,与 BatchNorm 和 Layer Normalization 相反, The operator does not depend on batch statistics.
- 与 A f f Aff AffA closer operator is Touvron et al. 引入的 LayerScale,with an additional bias term.
为方便起见,用 A f f ( X ) Aff(X) Aff(X)表示独立应用于矩阵 X 的每一列的仿射运算.
at the beginning of each residual block (“pre-normalized”) 和结束 (“后归一化”) 处应用 A f f Aff Aff算子,as a pre-normalization A f f Aff Aff取代了 LayerNorm,而不使用通道统计.这里,初始化 α = 1, β = 0.as post-normalization, A f f Aff Aff类似于LayerScale
2) 流程
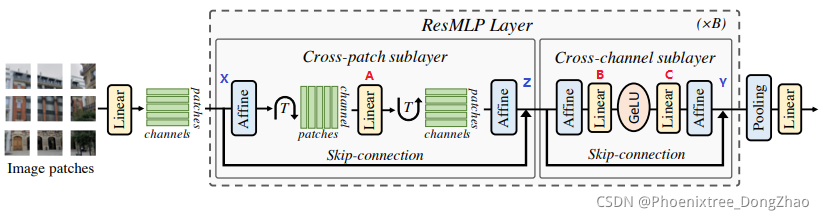
总的来说,The multilayer perceptron of this paper will be a set N 2 N^2 N2dDimensional input features are stacked in one d × N 2 d\times N^2 d×N2矩阵X中,并输出一组 N 2 N^2 N2d维输出特征,堆叠在一个矩阵Y中,Its transformation set is eg (3) 和 (4).其中 A, B 和 C is the main learnable weight matrix of this layer.
Z = X + Aff ( ( A Aff ( X ) ⊤ ) ⊤ ) Y = Z + Aff ( C GELU ( B Aff ( Z ) ) ) \begin{array}{l} \mathbf{Z}=\mathbf{X}+\operatorname{Aff}\left(\left(\mathbf{A} \operatorname{Aff}(\mathbf{X})^{\top}\right)^{\top}\right) \\ \mathbf{Y}=\mathbf{Z}+\operatorname{Aff}(\mathbf{C} \operatorname{GELU}(\mathbf{B} \operatorname{Aff}(\mathbf{Z}))) \end{array} Z=X+Aff((AAff(X)⊤)⊤)Y=Z+Aff(CGELU(BAff(Z)))
2.3 设计细节
ResMLP不像MLP-MixerUse two as wellMLP,对于token mixingParts just take onelinear层.其实ResMLPThe original intention is toself-attention替换成MLP,而self-attention后面的FFN本身就是一个MLP,这样就和Google的MLP-Mixer一样了,But in the end experiments found replacementsself-attention的MLPThe larger the dimension of the middle hidden layer, the worse the effect,Simply simplifies directly to a simple linear layer of size N × N;

2.4 总结
与 Vision Transformer 架构的差异:
ResMLP 体系结构与 ViT 模型密切相关.然而,ResMLP 与 ViT 不同,There are several simplifications:
• 无 self-attention 块:It is replaced by a linear layer with no nonlinearities,
• 无位置 embedding:Linear layers implicitly encode about embedding 位置的信息,
• 没有额外的 “class” tokens:只是在 patch embedding Use average pooling,
• 不基于 batch Normalization of statistics:Use learnable affine operators.
3. 代码
import torch
import torch.nn as nn
from functools import partial
from timm.models.vision_transformer import Mlp, PatchEmbed, _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, DropPath
__all__ = [
'resmlp_12', 'resmlp_24', 'resmlp_36', 'resmlpB_24'
]
class Affine(nn.Module):
def __init__(self, dim):
super().__init__()
self.alpha = nn.Parameter(torch.ones(dim))
self.beta = nn.Parameter(torch.zeros(dim))
def forward(self, x):
return self.alpha * x + self.beta
class layers_scale_mlp_blocks(nn.Module):
def __init__(self, dim, drop=0., drop_path=0., act_layer=nn.GELU, init_values=1e-4, num_patches=196):
super().__init__()
self.norm1 = Affine(dim)
self.attn = nn.Linear(num_patches, num_patches)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = Affine(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(4.0 * dim), act_layer=act_layer, drop=drop)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
def forward(self, x):
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x).transpose(1, 2)).transpose(1, 2))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
return x
class resmlp_models(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12, drop_rate=0.,
Patch_layer=PatchEmbed, act_layer=nn.GELU,
drop_path_rate=0.0, init_scale=1e-4):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.patch_embed = Patch_layer(
img_size=img_size, patch_size=patch_size, in_chans=int(in_chans), embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
dpr = [drop_path_rate for i in range(depth)]
self.blocks = nn.ModuleList([
layers_scale_mlp_blocks(
dim=embed_dim, drop=drop_rate, drop_path=dpr[i],
act_layer=act_layer, init_values=init_scale,
num_patches=num_patches)
for i in range(depth)])
self.norm = Affine(embed_dim)
self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
for i, blk in enumerate(self.blocks):
x = blk(x)
x = self.norm(x)
x = x.mean(dim=1).reshape(B, 1, -1)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def resmlp_12(pretrained=False, dist=False, **kwargs):
model = resmlp_models(
patch_size=16, embed_dim=384, depth=12,
Patch_layer=PatchEmbed,
init_scale=0.1, **kwargs)
model.default_cfg = _cfg()
if pretrained:
if dist:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_12_dist.pth"
else:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_12_no_dist.pth"
checkpoint = torch.hub.load_state_dict_from_url(
url=url_path,
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def resmlp_24(pretrained=False, dist=False, dino=False, **kwargs):
model = resmlp_models(
patch_size=16, embed_dim=384, depth=24,
Patch_layer=PatchEmbed,
init_scale=1e-5, **kwargs)
model.default_cfg = _cfg()
if pretrained:
if dist:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_24_dist.pth"
elif dino:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_24_dino.pth"
else:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_24_no_dist.pth"
checkpoint = torch.hub.load_state_dict_from_url(
url=url_path,
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def resmlp_36(pretrained=False, dist=False, **kwargs):
model = resmlp_models(
patch_size=16, embed_dim=384, depth=36,
Patch_layer=PatchEmbed,
init_scale=1e-6, **kwargs)
model.default_cfg = _cfg()
if pretrained:
if dist:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_36_dist.pth"
else:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlp_36_no_dist.pth"
checkpoint = torch.hub.load_state_dict_from_url(
url=url_path,
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def resmlpB_24(pretrained=False, dist=False, in_22k=False, **kwargs):
model = resmlp_models(
patch_size=8, embed_dim=768, depth=24,
Patch_layer=PatchEmbed,
init_scale=1e-6, **kwargs)
model.default_cfg = _cfg()
if pretrained:
if dist:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlpB_24_dist.pth"
elif in_22k:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlpB_24_22k.pth"
else:
url_path = "https://dl.fbaipublicfiles.com/deit/resmlpB_24_no_dist.pth"
checkpoint = torch.hub.load_state_dict_from_url(
url=url_path,
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
if __name__ == '__main__':
from thop import profile
model = resmlp_12(num_classes=1000)
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input,))
print("flops:{:.3f}G".format(flops/1e9))
print("params:{:.3f}M".format(params/1e6))
参考资料
边栏推荐
- QT模态对话框及非模态对话框学习
- Data Governance (5): Metadata Management
- Go语言JSON文件的读写操作
- [Kali Security Penetration Testing Practice Course] Chapter 7 Privilege Escalation
- Pagoda server PHP+mysql web page URL jump problem
- 【8.8】代码源 - 【不降子数组游戏】【最长上升子序列计数(Bonus)】【子串(数据加强版)】
- UXDB现在支持函数索引吗?
- GDB之指令基础参数
- Research on IC enterprises
- 中级xss绕过【xss Game】
猜你喜欢

【二叉树-中等】2265. 统计值等于子树平均值的节点数
量化交易策略介绍及应用市值中性化选股

OpenCV图像处理学习二,图像掩膜处理

数据库治理利器:动态读写分离
In automated testing, test data is separated from scripts and parameterized methods

QT中,QTableWidget 使用示例详细说明
数组(一)
![[Red Team] ATT&CK - Self-starting - Self-starting mechanism using LSA authentication package](/img/72/d3e46a820796a48b458cd2d0a18f8f.png)
[Red Team] ATT&CK - Self-starting - Self-starting mechanism using LSA authentication package
![[Kali Security Penetration Testing Practice Course] Chapter 8 Web Penetration](/img/5f/907057956658a19306da21c71185ea.png)
[Kali Security Penetration Testing Practice Course] Chapter 8 Web Penetration

月薪35K,靠八股文就能做到的事,你居然不知道
随机推荐
Data Governance (5): Metadata Management
GDB之指令基础参数
The Evolutionary History of the "Double Gun" Trojan Horse Virus
Redis - String|Hash|List|Set|Zset数据类型的基本操作和使用场景
liunx PS1 设置
Algorithm and voice dialogue direction interview question bank
基于误差状态的卡尔曼滤波ESKF
芯片加速器 Accelerator
Web mining traceability?Browser browsing history viewing tool Browsinghistoryview
2022.8.8 Exam area link (district) questions
从滑动标尺模型看企业网络安全能力评估与建设
what is eabi
[Kali Security Penetration Testing Practice Course] Chapter 7 Privilege Escalation
通关剑指 Offer——剑指 Offer II 012. 左右两边子数组的和相等
Introduction and application of quantitative trading strategies
【Kali安全渗透测试实践教程】第9章 无线网络渗透
storage of data in memory
Write a drop-down refresh component
Difference Between Data Mining and Data Warehousing
GDB command basic parameters