当前位置:网站首页>Milvus 2.0 質量保障系統詳解
Milvus 2.0 質量保障系統詳解
2022-04-23 16:55:00 【Zilliz Planet】
編者按:本文詳細介紹了 Milvus 2.0 質量保障系統的工作流程、執行細節,以及提高效率的優化方案。
質量保障總體介紹
測試內容的關注點
開發團隊與質量保障團隊如何協同
Issue 的管理流程
發布標准
測試模塊介紹
總體介紹
單元測試
功能測試
部署測試
可靠性測試
穩定性和性能測試
提效方法和工具
Github Action
性能測試
質量保障總體介紹

架構設計圖對於質量保障同樣重要,只有充分了解被測對象,才能制定出更合理和高效的測試方案。Milvus 2.0 是一個雲原生、分布式的架構,主要的入口通過 SDK 進入,內部有很多分層的邏輯。因而對於用戶來說,SDK 這一端是非常值得關注的一部分,對 Milvus 測試時,首先會對 SDK 這一端進行功能測試,並通過 SDK 去發現 Milvus 內部可能存在的問題。同時 Milvus 也是一個數據庫,因此關於數據庫的各種系統測試也會涉及到。
雲原生、分布式的架構,既會給測試帶來好處,也會引入各種挑戰。好處在於,區別於傳統的本地部署運行,在 k8s 集群中部署和運行能盡可能保證軟件在開發和測試時環境一致。挑戰則是分布式的系統變得複雜,引入了更多的不確定性,測試工作量和難度的增加。例如微服務化後服務數量增加、機器的節點會變多,中間階段越多,出錯的可能性越大,測試時就需要考慮各個情况。
測試內容的關注點
根據產品的性質、用戶的需求,Milvus 測試的內容與優先級如下圖所示。

首先在功能(Function)上,關注接口能否與設計的預期符合。
其次在部署(Deployment)上,關注 standalone 或者 cluster 模式下重啟和昇級是否能成功。
第三在性能(Performance)上,因為是流批一體的實時分析數據庫,所以對於速度會更重視,會更關注插入、建立索引、查詢的性能。
第四在穩定性(Stability)上,關注 Milvus 在正常的負載下的正常運行時間,預期目標是 5 - 10天。
第五在可靠性(Reliability)上,關注錯誤發生時 Milvus 的錶現,以及錯誤消除是否還能正常工作。
第六是配置問題(Configuration),需要驗證每個開放出來的配置項能否正常工作,變更能否生效。
最後是兼容性問題(Compatibility),主要是體現在硬件上和軟件配置上。
由圖可知,功能和部署是放在最高等級的,性能、穩定性、可靠性放在第二等級,最後將配置和兼容性放在第三的比特置。不過,這個等級重要性也是相對而言的。
開發團隊與質量保障團隊如何協同
一般用戶會認為質量保證的任務是僅僅分配給質量保證團隊的,但是軟件開發過程中,質量需要多方團隊合作以得到保障。

最開始的階段由開發設計文檔,質量保障團隊根據設計文檔寫測試計劃。這兩個文檔需要測試和開發共同參與以减少理解誤差。發布前會制定這一版本的目標,包括性能、穩定性、bug 數需要收斂到什麼程度等。在開發過程中,開發側重於編碼功能的實現,功能完成之後質量保障團隊會進行測試和驗證。這兩個階段會輪巡很多遍,質量保障團隊和開發團隊需要每天保持信息同步。此外,除了本身功能的開發驗證,開源的產品還會收到很多來自於社區的問題,也會根據優先級進行解决。
在最後階段,如果產品達到了發布標准,團隊就會選定一個時間節點,發布一個新的鏡像。在發布前需要准備一個 release tag 和 release note,關注這個版本實現了什麼功能,修複了什麼 issue,後期質量保障團隊也會針對這個版本出一個測試報告。
Issue 的管理流程

質量保障團隊更多地關注於產品開發中的 issue。Issue 的作者除了質量保障團隊的成員,還有大量的外部用戶,因此需要規範每個 issue 的填寫信息。每個 issue 都有一個模板,要求作者提供一些信息,例如當前使用的版本,機器配置信息,然後你的預期是什麼?實際的返回結果是什麼?如何去複現這個 issue,然後質量團隊和開發團隊會繼續去跟進。
在創建這個 issue 之後,首先會 assign 給質量保障團隊的負責人,然後負責人會對這個 issue 進行一些狀態流轉。如果 issue 成立且有足够多的信息,後續會有若幹種狀態,如:是否解决了;是否能複現;是否與之前有重複;出現概率大小;優先級大小。如果確認存在缺陷,開發團隊會提交 PR,關聯上這個 issue,進行修改。在得到驗證後,這個 issue 會被關閉,如果之後發現依然存在問題,還可以 reopen。此外,為了提高 issue 的管理效率,還會引入標簽和機器人,用於對 issue 分類和狀態流轉。
發布標准

能否發布主要指當前這個版本能否達到預期要求。例如上圖是一個大致的情况,RC6 到 RC7,RC8 和 GA 的標准。隨著版本的推進,對 Milvus 的質量提出更高的要求:
- 從原先 50M 的數量級,逐漸演進到 1B 的數量級
- 在穩定性的任務運行中,由單任務變成混合任務,時長逐漸由小時級變成天級
- 對於代碼而言,也在逐漸提高它的代碼覆蓋率
- ……
- 此外,隨著版本的更替,也會加入其他的測試項。例如在 RC7 的時候,提出了要有一個兼容項,昇級的時候要有兼容;在 GA 的時候,引入更多關於混沌工程的測試
測試模塊介紹
第二部分是關於每個測試模塊的一些具體細節。
總體介紹
業界有寫代碼就是寫 bug 的戲謔,從下圖可以看到,85%的 bug 是由 coding 階段引入的。

從測試的角度來看,代碼編寫到版本發布這個過程中,依次可以通過 Unit Test / Functional Test / System Test 去發現 bug;但是隨著階段的推移,修複 bug 的成本也會遞增,所以往往傾向於早發現早修複。不過,每個階段的測試有自己的側重點,不可能只通過一種測試手段就發現所有的 bug。

開發從編寫代碼到代碼合並到主分支這個階段分別會從 UT、code coverage 和 code review 去保障代碼質量,這幾項也體現在 CI 中 。在提交 PR 到代碼合並的過程中,需要通過靜態代碼檢查、單元測試、代碼覆蓋率標准以及 reviewer 的代碼審核。
在合並代碼時,同樣需要通過集成測試。為了保證整個 CI 的時間不會太長,在這個集成測試裏面,主要運行 L0 和 L1 這些具有高優先級標簽的 case。通過所有檢查後,就可以到 milvusdb/milvus-dev 倉庫中發布這個 PR 構建的鏡像。在鏡像發布之後,會設置定時任務對最新的鏡像進行前文提到的多種測試:全量的原有功能測試,新特性的功能測試,部署測試,性能測試,穩定性測試,混沌測試等。
單元測試
單元測試可以在盡可能早的階段發現軟件存在的 bug,同時也可以為代碼重構提供驗證標准。在 Milvus 的 PR 准入標准中,設定了代碼的單元測試 80% 覆蓋率目標。

https://app.codecov.io/gh/milvus-io/milvus/
功能測試
對 Milvus 的功能測試,主要是通過 pymilvus 這個 SDK 作為切入點。
功能測試主要關注於接口能否按照預期工作。
- 輸入正常的參數或采用正常的操作時,SDK 是否能返回預期的結果
- 當參數或操作是异常的時候,SDK 是否能 handle 住這些錯誤,同時能够返回一些合理的錯誤信息
下圖是當前的功能測試框架,整體而言是基於目前主流的測試框架 pytest,並對 pymilvus 進行了一次封裝,提供了接口自動化測試能力。

采用上述測試框架, 而不是直接用 pymilvus 原生的接口,是因為在測試過程中需要提取出一些公共方法,複用一些常用的函數。同時也會封裝一個 check 的模塊,能更方便地去校驗一些預期和真實值。
當前 tests/python_client/testcases 目錄下的功能測試用例已經有 2700+,基本上覆蓋了 pymilvus 的所有接口,且包含正面用例和反面用例。功能測試作為 Milvus 的基本功能保障,通過自動化和持續集成,嚴格把控每一個提交的 PR 質量。
部署測試
部署測試中,支持 Milvus 部署形態有 standalone 和 cluster ,部署的方式有 docker 或者 helm。部署完成之後,需要對系統執行 restart 和 upgrade 的操作。
重啟測試,主要是驗證數據的持久化,即重啟前的數據在重啟後能否繼續使用;昇級測試,主要是驗證數據的兼容性,防止在不知情的情况下引入了不兼容的數據格式。
重啟測試和昇級測試可以統一為如下的測試流程:

如果是重啟測試,兩次部署使用相同鏡像;如果是昇級測試,第一次部署使用舊版本鏡像,第二次部署使用新版本鏡像。第二次部署時,無論是重啟還是昇級,均會保留第一次部署後的測試數據( Volumes 文件夾或者 PVC )。在 Run first test 這個步驟中,會創建多個 collection,並對每個 collection 執行不同的操作,使其處於不同的狀態,例如:
- create collection
- create collection --> insert data
- create collection --> insert data -->load
- create collection --> insert data -->flush
- create collection --> insert data -->flush -->load
- create collection --> insert data -->flush --> create index
- create collection --> insert data -->flush --> create index --> load
- ......
在 Run second test 這個步驟中會進行兩種驗證:
- 之前創建的 collection 各種功能依然可用
- 可以創建新的 collection,同樣各種功能依然可用
可靠性測試
當前針對雲原生,分布式產品的可靠性,大部分的公司都會通過混沌工程的方法進行測試。混沌工程旨在將故障扼殺在繈褓之中,也就是在故障造成中斷之前將它們識別出來。通過主動制造故障,測試系統在各種壓力下的行為,識別並修複故障問題,避免造成嚴重後果。
在執行 chaos test 時,選擇了 Chaos Mesh 作為故障注入工具。Chaos Mesh 是 PingCAP 公司在測試 TiDB 可靠性的過程中孵化出來的,非常適合用於雲原生分布式數據庫的可靠性測試。
在故障類型中,實現了以下幾種故障類型:
- 首先就是 pod kill,測試範圍是所有的組件,模擬節點宕機的情况
- 其次 pod failure,主要是關注於 work node 的多副本情况下,有一個 pod 不能工作,整個系統還能正常運作
- 第三個是 memory stress ,側重內存和 CPU 的壓力,主要注入到 work node 的節點
- 最後一個 network partition ,即 pod 與 pod 之間的一個通信隔離。Milvus 是一個存儲計算分離,工作節點和協調節點分離的多層架構,不同組件之間的通信非常多,需要通過 network partition 測試它們之間的相互依賴關系
通過建構一套框架,較為自動化地實現 Chaos Test。

流程:
- 通過讀取部署配置,初始化一個 Milvus 集群
- 集群狀態 ready 後,首先會運行一個 e2e 測試,驗證 Milvus 的功能可用
- 運行 hello_milvus.py,主要用於驗證數據的可持久化,會在故障注入前創建一個 hello_milvus 的 collection,進行數據插入,flush,create index,load,search,query。注意,不會將 collection release 和 drop
- 創建一個監測對象,該對象主要是開啟 6 個線程,分別不斷執行 create,insert,flush,index,search,query 操作
checkers = {
Op.create: CreateChecker(),
Op.insert: InsertFlushChecker(),
Op.flush: InsertFlushChecker(flush=True),
Op.index: IndexChecker(),
Op.search: SearchChecker(),
Op.query: QueryChecker()
}- 故障注入前進行第一次斷言:所有操作預期成功
- 注入故障:解析定義故障的 yaml 文件,通過 Chaos Mesh,向 Milvus 系統中注入故障,例如使 query node 每 5s 被 kill 一次
- 故障注入期間進行第二次斷言:判斷針對故障期間的 Milvus 執行的各個操作返回的結果與預期是否一致
- 删除故障:通過 Chaos Mesh 删除之前注入的故障
- 故障删除,Milvus 恢複服務後(所有 pod 都 ready ),進行第三次斷言:所有操作預期成功
- 運行一個 e2e 測試,驗證 Milvus 的功能可用,因為第三次斷言,有些操作會在 chaos 注入期間被阻塞,即使故障消除後,依然被阻塞,導致第三次斷言不能如預期一樣全部成功。因此增加這個步驟輔助第三次斷言的判斷,並暫時將這次 e2e 測試作為 Milus 是否恢複的標准
- 運行 hello_milvus.py,加載之前創建的 collection,並對該 collection 執行一系列操作,判斷故障前的數據在故障恢複後,是否依然可用
- 日志收集
穩定性和性能測試
穩定性測試
穩定性測試的目的:
- Milvus 可以在正常水平的壓力負載下,平穩運行設定的時長
- 在運行過程中,系統使用的資源保持平穩,Milvus 的服務正常
主要考慮兩種負載場景:
- 讀密集:search 請求 90%,insert 請求 5%, 其他 5%。這種場景主要是離線場景,數據導入之後,基本不更新,主要提供查詢服務
- 寫密集: insert 請求 50%,search 請求 40%,其他 10%。這種場景主要是在線場景,需要提供邊插入邊查詢的服務
檢查項:
- 內存使用量平滑
- CPU 使用量平滑
- IO 延時平滑
- Milvus 的 pod 狀態正常
- Milvus 服務響應時間平滑
性能測試
性能測試的目的:
- 對 Milvus 各個接口進行性能摸底
- 通過性能對比,找到接口最佳的參數配置
- 作為性能基准,防止之後的版本出現性能下降
- 找到性能瓶頸點,為性能調優提供參考
主要考慮的性能場景:
- 數據插入性能
- 性能指標:吞吐量
- 變量:每批次插入向量數,......
- 索引構建性能
- 性能指標:索引構建時間
- 變量:索引類型,index node 數量,......
- 向量查詢性能
- 性能指標:響應時間,每秒查詢向量數,每秒請求數,召回率
- 變量:nq,topK,數據集規模大小,數據集類型,索引類型,query node 數量,部署模式,......
- ......
測試框架和流程

- 解析並更新配置,定義指標
- server-configmap 對應的是 Milvus 單機或者集群的配置
- client-configmap 對應的是測試用例配置
- 配置服務端和客戶端
- 數據准備
- 客戶端與服務端之間的請求交互
- 指標數據的上報與展示
提效方法和工具
由前文可知,測試中很多步驟流程是相同的,主要是修改 Milvus server 端的配置,client 端的配置,接口的傳入參數。在多項配置下,通過排列組合,需要執行很多次實驗才能比較全面地覆蓋各種測試場景,因此代碼複用、流程複用、測試效率就是非常重要的問題。

- 對原有方法進行一個 api_request 的裝飾器封裝,設置成類似於一個 API gateway,統一去接收所有的 API 請求,發送給 Milvus 然後統一接收響應,再返回給 client。 這樣更容易去捕捉一些日志信息,比如傳的參數、返回的結果。同時返回的結果可以通過 checker 模塊去校驗,便於將所有的檢查方法定義在同一個 checker 模塊
- 設置默認參數,將多個必要的初始化步驟封裝成一個函數,原先需要大量代碼實現的功能就可以通過一個接口實現。這種設定能够减少大量冗餘重複的代碼,使每個測試用例更簡單清晰
- 每個測試用例都是關聯獨有的 collection 進行測試,保證了測試用例之間的數據隔離性。在每個測試用例的的執行起始步驟,創建新的 collection 用於測試,在測試結束後也會删除對應的 collection
- 因為每個測試用例都是互相獨立的,在執行測試用例的時候,可以通過 pytest 的插件
pytest -xdist並發執行,提高執行效率
Github Action
GitHub Action 的優點:
- 與 GitHub 深度集成,原生的 CI/CD 工具
- 統一配置的機器環境,同時預裝了豐富的常用軟件開發工具
- 支持多種操作系統和版本:Ubuntu, Mac 和 Windows-server
- 擁有豐富的插件市場,提供了各種開箱即用的功能
- 通過 matrxi 進行排列組合,複用同一套測試流程,支持並發的 job,從而提高效率
部署測試和可靠性測試都需要獨立隔離的環境,非常適合在 GitHub Action 上進行小規模數據量的測試。通過每日定時運行,測試最新的 master 鏡像,起到日常巡檢的功能。

性能測試工具

- Argo workflow:通過創建 workflow,實現任務的調度,將各個流程串聯起來。從右圖可以看出,通過 Argo 可以實現多個任務同時運行
- Kubernetes Dashboard:可視化 server-configmap 和 client-configmap
- NAS:掛載常用的 ann-benchmark 數據集
- InfluxDB 和 MongoDB: 保存性能指標結果
- Grafana:服務端資源指標監控,客戶端性能指標監控
- Redash: 性能圖錶展示
完整版視頻講解請戳:
Deep dive#7 Milvus 2.0 質量保障系統詳解_嗶哩嗶哩_bilibili
如果你在使用的過程中,對 Milvus 有任何改進或建議,歡迎在 GitHub 或者各種官方渠道和我們保持聯系~
Zilliz 以重新定義數據科學為願景,致力於打造一家全球領先的開源技術創新公司,並通過開源和雲原生解决方案為企業解鎖非結構化數據的隱藏價值。
Zilliz 構建了 Milvus 向量數據庫,以加快下一代數據平臺的發展。Milvus 數據庫是 LF AI & Data 基金會的畢業項目,能够管理大量非結構化數據集,在新藥發現、推薦系統、聊天機器人等方面具有廣泛的應用。

版权声明
本文为[Zilliz Planet]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231654325045.html
边栏推荐
- SQL: How to parse Microsoft Transact-SQL Statements in C# and to match the column aliases of a view
- 昆腾全双工数字无线收发芯片KT1605/KT1606/KT1607/KT1608适用对讲机方案
- Change the password after installing MySQL in Linux
- ACL 2022 | dialogved: a pre trained implicit variable encoding decoding model for dialogue reply generation
- Interface document yaml
- File upload and download of robot framework
- Encapsulating the logging module
- Nodejs reads the local JSON file through require. Unexpected token / in JSON at position appears
- Deeply understand the relevant knowledge of 3D model (modeling, material mapping, UV, normal), and the difference between displacement mapping, bump mapping and normal mapping
- 伪分布安装spark
猜你喜欢

如何建立 TikTok用户信任并拉动粉丝增长
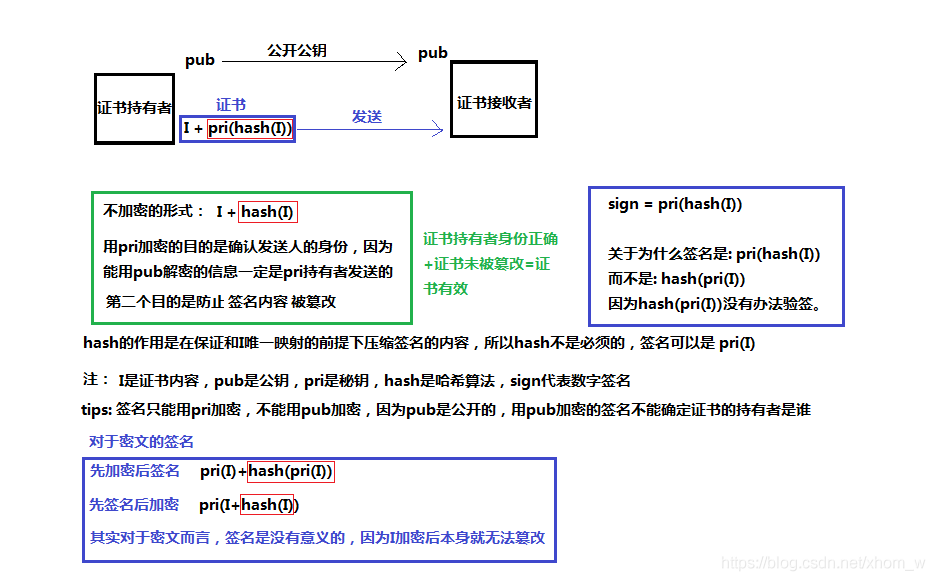
On the security of key passing and digital signature

众昂矿业:萤石浮选工艺
Nifi fast installation and file synchronization
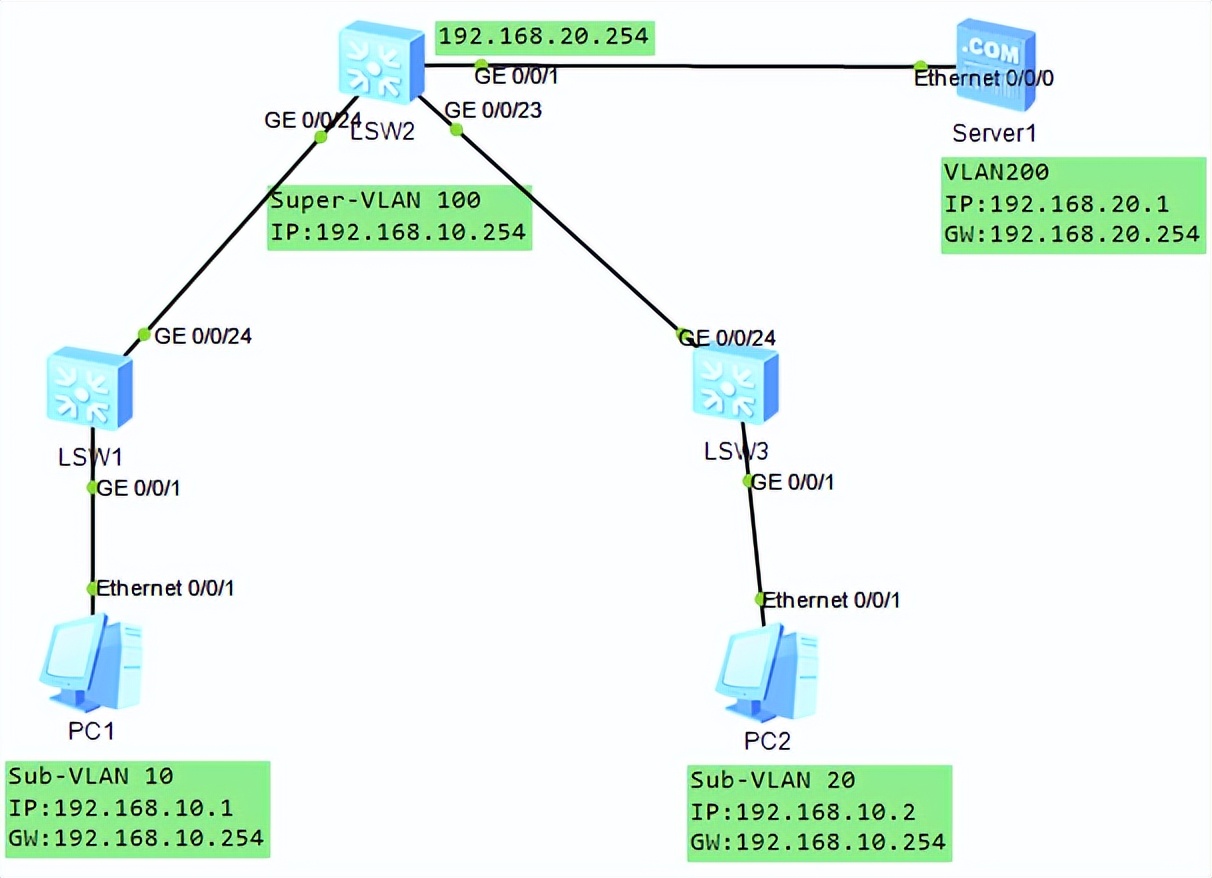
VLAN高级技术,VLAN聚合,超级Super VLAN ,Sub VLAN

批量制造测试数据的思路,附源码

英语 | Day15、16 x 句句真研每日一句(从句断开、修饰)

How to choose the wireless gooseneck anchor microphone and handheld microphone scheme
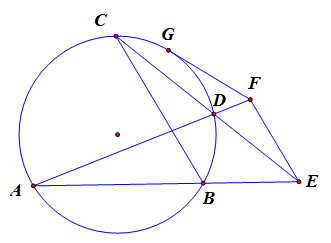
1959年高考数学真题
Feign report 400 processing
随机推荐
Disk management and file system
Deepinv20 installation MariaDB
Introduction to new functions of camtasia2022 software
深入了解3D模型相关知识(建模、材质贴图、UV、法线),置换贴图、凹凸贴图与法线贴图的区别
Server log analysis tool (identify, extract, merge, and count exception information)
Flask如何在内存中缓存数据?
Solution of garbled code on idea console
Kunteng full duplex digital wireless transceiver chip kt1605 / kt1606 / kt1607 / kt1608 is suitable for interphone scheme
PHP efficiently reads large files and processes data
杂文 谈谈古典的《拆掉思维里的墙》
聊一聊浏览器缓存控制
How vscode compares the similarities and differences between two files
文件操作详解(2)
An essay on the classical "tear down the wall in thinking"
Construction of promtail + Loki + grafana log monitoring system
Getting started with JDBC
ACL 2022 | DialogVED:用于对话回复生成的预训练隐变量编码-解码模型
Real time operation of vim editor
Regular filtering of Intranet addresses and segments
Tencent resolves the address according to the IP address