当前位置:网站首页>ACL 2022 | dialogved: a pre trained implicit variable encoding decoding model for dialogue reply generation
ACL 2022 | dialogved: a pre trained implicit variable encoding decoding model for dialogue reply generation
2022-04-23 16:41:00 【PaperWeekly】

author | Hanscal
Research direction | Knowledge map 、 Dialogue system

Paper title :
DialogVED: A Pre-trained Latent Variable Encoder-Decoder Model for Dialog Response Generation
Thesis link :
https://openreview.net/forum?id=WuVA5LBX5zf
This is the data intelligence and Social Computing Laboratory of Fudan University (Fudan DISC) stay ACL 2022 The work of a dialogue pre training . This paper focuses on the important research topic of how to generate relevance and diversified responses in the open domain , In this paper, a new Dialogue pre training framework DialogVED, It introduces continuous implicit variables into the enhanced encoder - Decoder frame , To improve the relevance and diversity of generated responses .
It is well known that there is one or more questions in the generated dialogue , That is, a single conversation context can follow multiple reasonable responses . The existing work introduces latent variables to simulate this problem . lately ,PLATO Discrete implicit variables are introduced into the pre training dialogue model , It also shows significant performance improvement in multiple downstream response generation tasks . In addition to discrete latent variables , Continuous latent variables are also commonly used to model one to many mappings in dialogue systems , However, the potential of combining continuous implicit variables with large-scale language pre training is rarely explored .

Optimize content
In this paper , The author proposes a method to introduce continuous hidden variables into the encoder - Model of decoder framework DialogVED, And optimize the following 4 A training goal for pre training :1) Mask language model loss , To enhance the encoder's understanding of the context ,2) have n-gram The response to the loss generates a loss , To improve the planning ability of the decoder , 3)Kullback-Leibler Divergence loss , To minimize the difference between a posteriori distribution and a priori distribution of hidden variables , as well as 4) Word bag loss to reduce a posteriori distribution collapse . Besides , The effects of absolute and relative position coding on the performance of the model are also discussed .

Model structure
DialogVED from Encoder 、 Decoder and implicit variables form , The encoder determines the distribution of the hidden space , Hidden variables are sampled from the hidden space , The encoder and the implicit variable jointly guide the decoder , The overall framework is shown in the figure below , Four in the yellow box task Is what needs to be optimized :
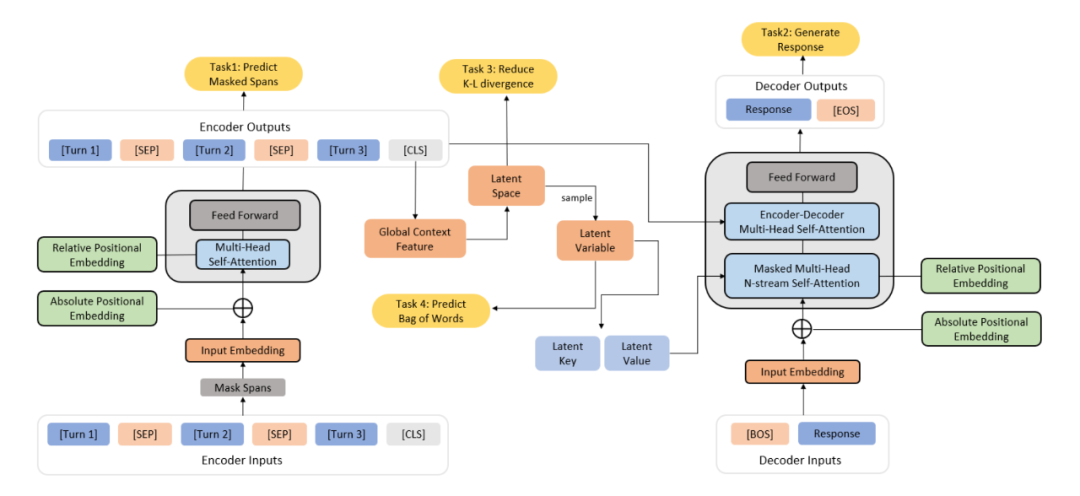
▲ DialogVED Pre training and fine tuning framework

Encoder
Use multiple layers Transformer Encoder to encode conversation context , In order to improve the understanding ability and noise robustness of the encoder , Use span masking The way of randomly masking part of the context . In the process, a simple method is used to cover span:1) Randomly select... In context n individual token, Expressed as S ;2) For each token , Expand it to a fixed length of m The text of span;3) In order 、 Mask all selected marks after de duplication and boundary check token. and BERT similar , Controls the masked in the context token Account for about 15%, And use covered token The encoded implicit state representation predicts itself . Only in the pre training stage , Conduct span-making Mask context operations , The loss function is :
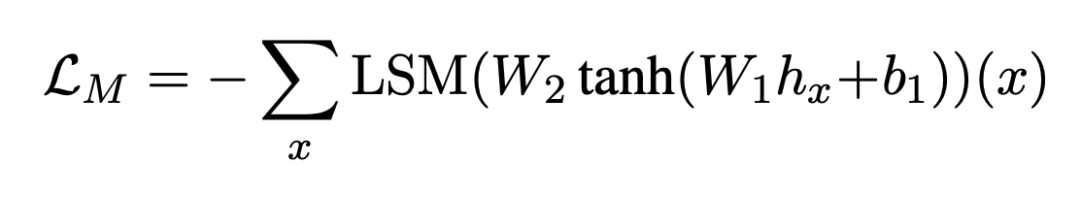
▲ The cross entropy loss function predicted by shielding words
LSM yes log softmax function .

Hidden variables
Intuitively , The introduction of implicit variables can provide a hierarchical generation method , The high-level semantic variable is determined by using the high-level semantic , It is then decoded to generate sentence level syntactic and lexical details . Similar to the variational self encoder , Mainly minimize the following two loss items : Reconstruction losses ( Or negative log likelihood ) and K-L Regularization term :
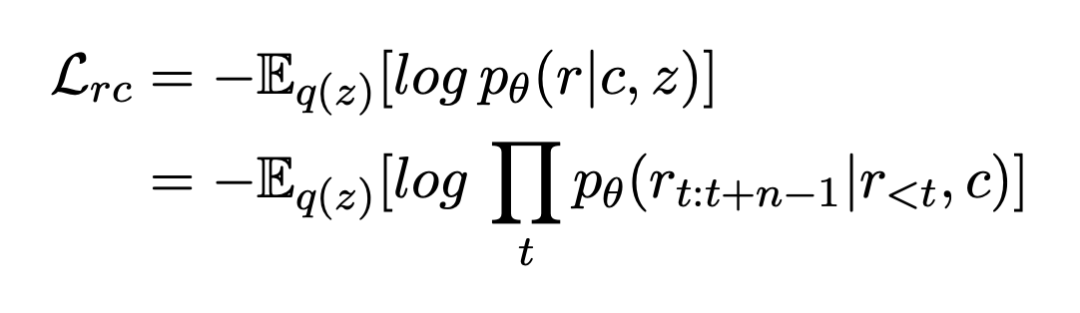
▲ Rebuild the loss function
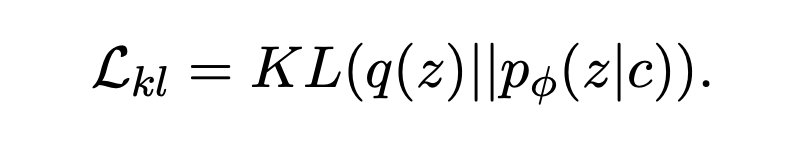
▲ KL Regularization term
Because in the process of training ,KL The loss will drop rapidly to 0(KL Disappearance or posterior collapse ), The implicit variable space loses its expressive ability , So this paper introduces two methods to improve KL When divergence disappears , One is Free Bits, stay KL Introduce... Into the loss Hinge loss normal form , That is, add a constant to the loss function λ, The other is Bag-of-words predicting, The loss function introduced by hindering the model to predict words with autoregressive paradigm .
stay Free Bits in , In order to allow more information to be encoded into implicit variables , Give Way KL Each dimension of the term is “ Reserve a little space ”. say concretely , If this one-dimensional KL It's too small , Don't optimize it , Wait until it increases beyond a threshold before optimizing .
stay Bag-of-words Predicting in , Let the implicit variable predict the words in the response in a non autoregressive way , That is to encourage implicit variables to contain the returned vocabulary information as much as possible . This method can be seen as increasing the weight of reconstruction loss , Let the model pay more attention to the optimization and reconstruction of loss items .
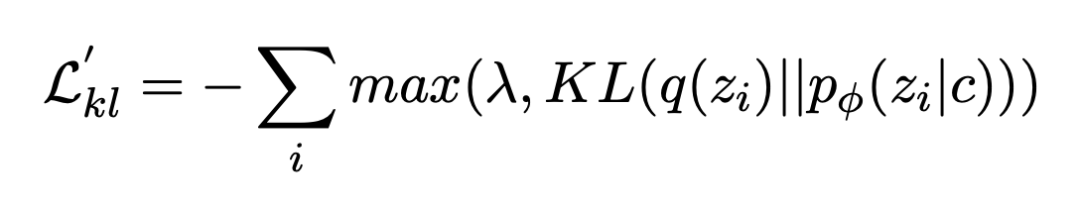
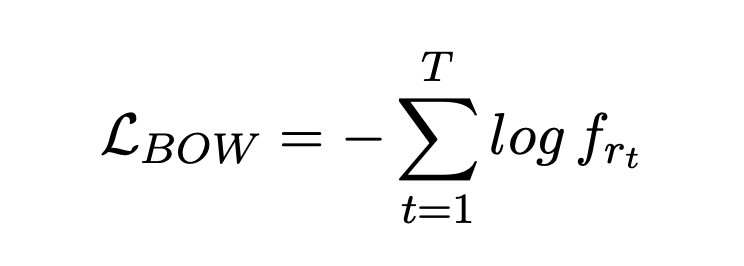
▲ The first is Free Bits Loss, The second is Bag-of-words Loss
The author adds a special classification mark at the beginning of the context [CLS], The corresponding implicit state representation is used to represent the global conversation context . It is assumed that the posterior distribution of the hidden vector is normal , And use MLP Layers will [CLS] The corresponding corresponding states are mapped to the mean and logarithmic variance of the hidden space , By sampling the normal distribution , You can get the corresponding implicit variable , Then input the implicit variable into the decoder .
Here you can see , The loss function consists of 4 Item composition :1) Cover language loss at encoder end ;2) Based on future predictions n-ngram Response generation loss ;3) A priori distribution and a posteriori distribution of hidden variables K-L Divergence loss ;4) The word bag predicts the loss .

decoder
The future prediction strategy is used in the decoder , And each time step predicts only the next token Different , Forecast the future at the same time n A future token. say concretely , The original Seq2Seq The model aims to optimize the conditional likelihood function , The optimization goal of the future prediction strategy will be , among Represents the next consecutive n A future token. In the future n-gram Predicting losses can clearly encourage models to plan for the future token forecast , And prevent over fitting of strong local correlation .
meanwhile , In the decoder ProphetNet Proposed in n-stream Self attention mechanism .n-stream The mechanism of self attention is main stream( Main stream ) In addition to n An extra self focus predicting stream( Flow prediction ), These prediction streams are used to predict n A continuous future token.Main stream and predicting stream Readers are advised to read ProphetNet [2].
Last , In order to connect the implicit variable and the decoder , Similar measures have been taken OPTIMUS [3] Proposed in Memory Scheme, That is, the implicit variable is mapped to an additional memory vector , This is an additional key value pair .memory vector It is equivalent to adding a virtual device during decoding token Participate in main stream The calculation of self attention , and predicting stream Through and with main stream Interaction is affected by memory vector Implicit influence . In this way, the implicit variable can pass through memory vector Guide the generation of each step of the decoder .

summary
This article is summarized as follows :1) A pre training dialogue model is proposed , It incorporates continuous implicit variables into the enhanced encoder - Decoder pre training framework ;2) Explored the size of implicit variables 、 Different decoding strategies 、 The impact of rounds and role location coding on the performance of the model ;3) Experiments show that , The model achieves good performance in multiple downstream tasks , Better relevance and diversity in response generation .

reference
[1] DialogVED: A Pre-trained Latent Variable Encoder-Decoder Model for Dialog Response Generation
[2] Prophetnet: Predicting future n-gram for sequence-to-sequence pre-training
[3] Optimus: Organizing sentences via pre-trained modeling of a latent space

Give Welfare !
Exclusive customization In alchemy /Fine-Tuning
Super mouse pad
limited 200 Share
Code scanning reply 「 Mouse pad 」
Participate and receive... Free of charge now

Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

版权声明
本文为[PaperWeekly]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231638535882.html
边栏推荐
- Dlib of face recognition framework
- Differences between MySQL BTREE index and hash index
- PyMySQL
- Detailed explanation of UWA pipeline function | visual configuration automatic test
- 文件操作详解(2)
- 昆腾全双工数字无线收发芯片KT1605/KT1606/KT1607/KT1608适用对讲机方案
- MySQL personal learning summary
- Report FCRA test question set and answers (11 wrong questions)
- ESXi封装网卡驱动
- Findstr is not an internal or external command workaround
猜你喜欢
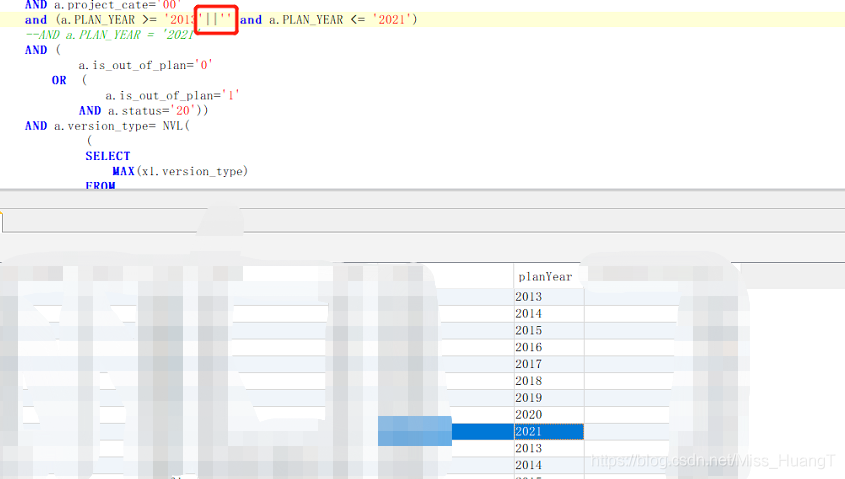
Query the data from 2013 to 2021, and only query the data from 2020. The solution to this problem is carried out

TypeError: set_figure_params() got an unexpected keyword argument ‘figsize‘
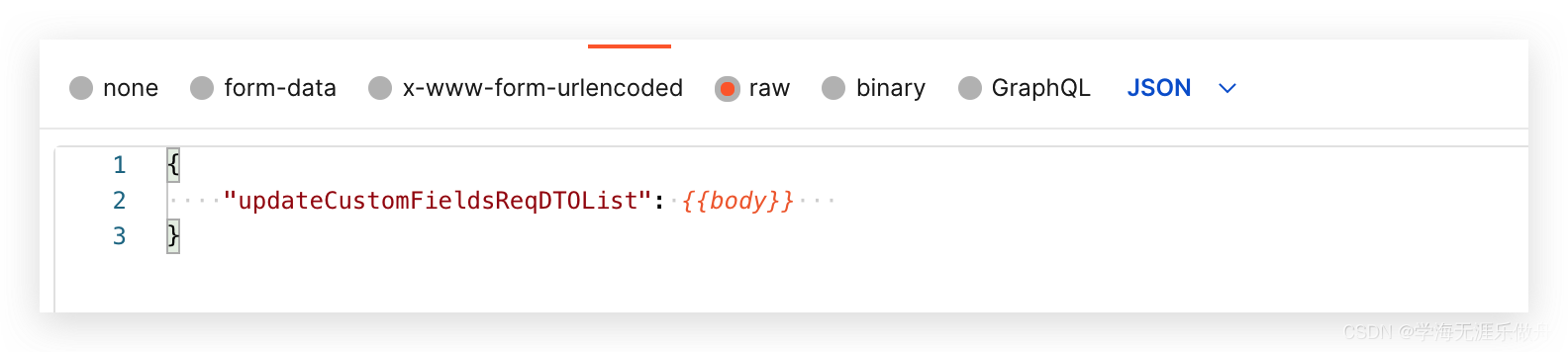
Postman batch production body information (realize batch modification of data)
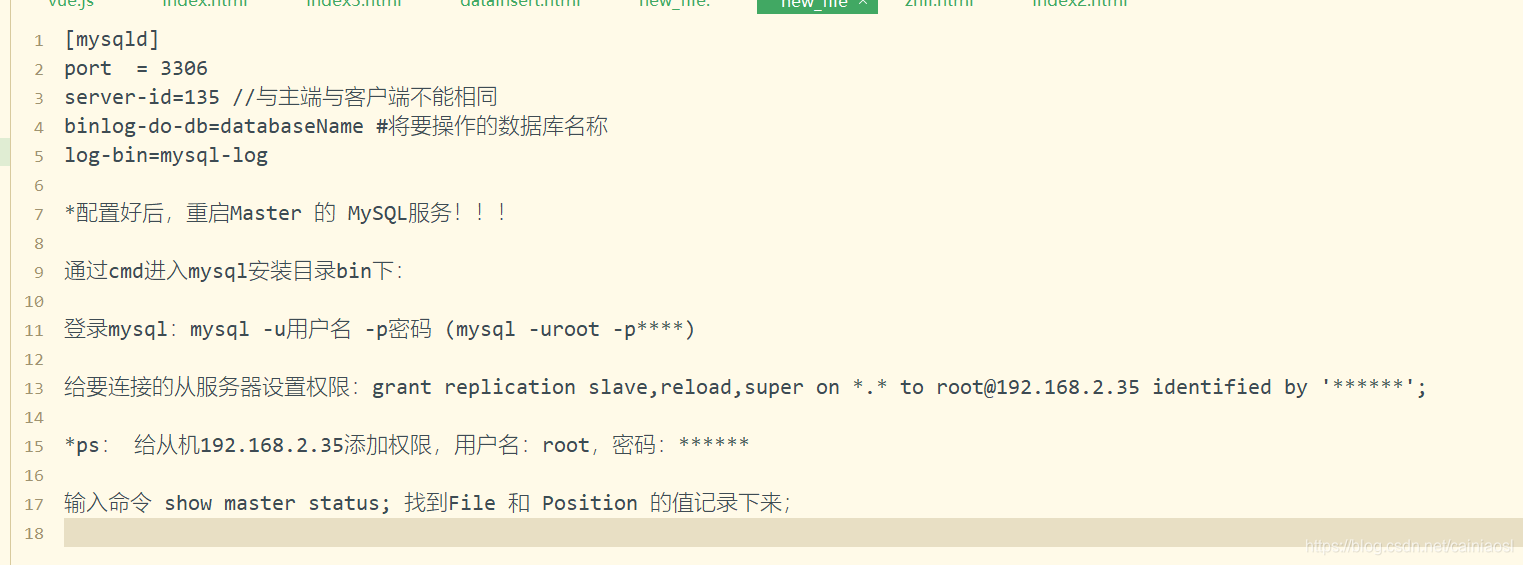
MySQL master-slave synchronization pit avoidance version tutorial
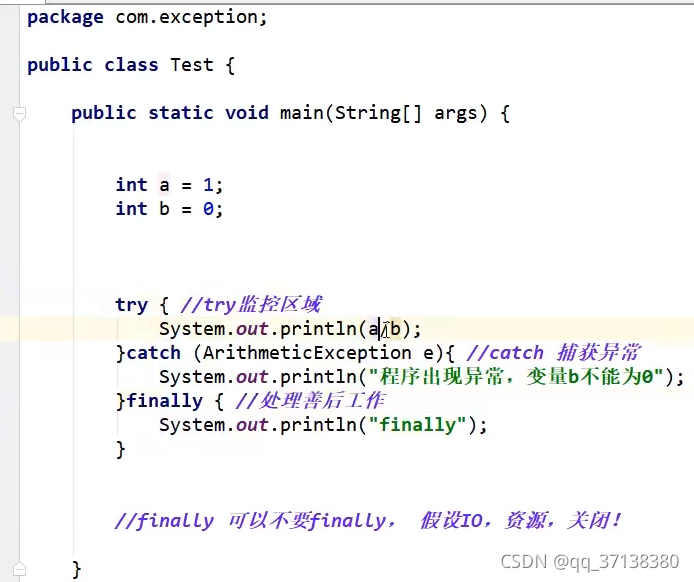
Day 10 abnormal mechanism

Hyperbdr cloud disaster recovery v3 Release of version 3.0 | upgrade of disaster recovery function and optimization of resource group management function
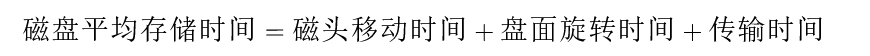
计组 | 【七 输入/输出系统】知识点与例题
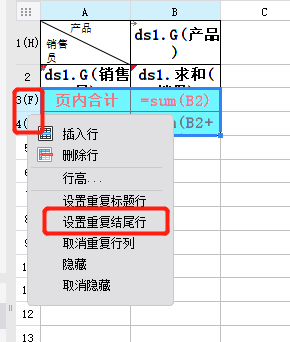
The first line and the last two lines are frozen when paging
Creation of RAID disk array and RAID5

Force buckle-746 Climb stairs with minimum cost
随机推荐
Dlib of face recognition framework
5分钟NLP:Text-To-Text Transfer Transformer (T5)统一的文本到文本任务模型
Introduction to how to set up LAN
LVM and disk quota
Use itextpdf to intercept the page to page of PDF document and divide it into pieces
JSP learning 3
深入了解3D模型相关知识(建模、材质贴图、UV、法线),置换贴图、凹凸贴图与法线贴图的区别
Detailed explanation of gzip and gunzip decompression parameters
Questions about disaster recovery? Click here
Selenium IDE and XPath installation of chrome plug-in
深度学习100例 | 第41天-卷积神经网络(CNN):UrbanSound8K音频分类(语音识别)
On the value, breaking and harvest of NFT project
MySQL master-slave synchronization pit avoidance version tutorial
STM32__03—初识定时器
About background image gradient()!
True math problems in 1959 college entrance examination
Gartner publie une étude sur les nouvelles technologies: un aperçu du métacosme
RecyclerView advanced use - to realize drag and drop function of imitation Alipay menu edit page
Change the icon size of PLSQL toolbar
VMware Workstation cannot connect to the virtual machine. The system cannot find the specified file