当前位置:网站首页>YOLOv5的Tricks | 【Trick10】从PyTorch Hub加载YOLOv5
YOLOv5的Tricks | 【Trick10】从PyTorch Hub加载YOLOv5
2022-08-10 23:48:00 【Clichong】
如有错误,恳请指出。
严格意义来说,这篇文章算不上是yolov5的一个训练技巧,而且yolov5的训练技巧在专栏之前的文章中基本已经都讲完了,之后可以会补充一些yolov5项目的其他内容。比如这篇,从 PyTorch Hub 加载YOLOv5模型,不需要克隆 https://github.com/ultralytics/yolov5
不过很多朋友(包括我),在整理之前,还不知道pytorch hub是什么,所以这里顺便介绍一些pytorch hub,然后再根据官方链接介绍如何不需要克隆就可以玩转yolov5项目。
文章目录
1. PyTorch Hub简单使用
官方介绍:Towards Reproducible Research with PyTorch Hub
可重复性是许多研究领域的基本要求,包括基于机器学习技术的研究领域。然而,许多机器学习出版物要么不可复制,要么难以复制。随着研究出版物数量的持续增长,包括现在在arXiv上托管的数万篇论文以及向会议提交的前所未有的高水平论文,研究可重复性比以往任何时候都更加重要。虽然这些出版物中的许多都附有代码和训练有素的模型,这很有帮助,但仍然留有许多步骤供用户自己弄清楚。
我们很高兴地宣布 PyTorch Hub 的可用性,这是一个简单的 API和工作流,为提高机器学习研究的可重复性提供了基本构建块。PyTorch Hub包含一个经过预训练的模型存储库,专门设计用于促进研究的可重复性并支持新的研究。它还内置了对Colab的支持,与Papers With Code集成,目前包含广泛的模型集,包括分类和分割、生成、Transformers等。
PyTorch Hub的使用简单到不能再简单,不需要下载模型,只用了一个torch.hub.load()就完成了对图像分类模型AlexNet的调用。
PyTorch Hub允许用户对已发布的模型执行以下操作:
1、查询可用的模型;
2、加载模型;
3、查询模型中可用的方法。
下面直接进行实例操作:
1.1 探索可用模型
用户可以使用torch.hub.list()这个API列出repo中所有可用的入口点。比如你想知道PyTorch Hub中有哪些可用的计算机视觉模型:
torch.hub.list('pytorch/vision')
输出:
Downloading: "https://github.com/pytorch/vision/zipball/main" to /root/.cache/torch/hub/main.zip
/root/.cache/torch/hub/pytorch_vision_main/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension:
warn(f"Failed to load image Python extension: {
e}")
['alexnet',
'convnext_base',
'convnext_large',
'convnext_small',
'convnext_tiny',
'deeplabv3_mobilenet_v3_large',
'deeplabv3_resnet101',
'deeplabv3_resnet50',
......
1.2 加载模型
现在我们知道 Hub 中有哪些模型可用,如果想加载上述的其中一个模型,只需要load一下即可
model = torch.hub.load('pytorch/vision', 'deeplabv3_resnet101', pretrained=True)
至于如何获得此模型的详细帮助信息,可以使用下面的API:
print(torch.hub.help('pytorch/vision', 'deeplabv3_resnet101'))
如果模型的发布者后续加入错误修复和性能改进,用户也可以非常简单地获取更新,确保自己用到的是最新版本:
model = torch.hub.load('pytorch/vision', 'deeplabv3_resnet101', pretrained=True, force_reload=True)
对于另外一部分用户来说,稳定性更加重要,他们有时候需要调用特定分支的代码。例如pytorch_GAN_zoo的hub分支:
model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub', 'DCGAN', pretrained=True)
1.3 查看模型的可用方法
从PyTorch Hub加载模型后,你可以用dir(model)查看模型的所有可用方法。不过这其实只是python的一个内置函数,dir内置函数 可以返回对象或者当前作用域内的属性列表
dir(model)
# 输出:
['forward'
...
'to'
'state_dict',
]
# 比如
>>> import math
>>> math
<module 'math' (built-in)>
>>> dir(math)
['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'trunc']
如果你对forward方法感兴趣,使用help(model.forward) 了解运行运行该方法所需的参数,这个help的指令其实也只是python的一个内置函数而已。对于其他库的函数同样可以使用。
help(model.forward)
1.4 其他指令
torch.hub.download_url_to_file:将给定 URL 处的对象下载到本地路径
torch.hub.download_url_to_file('https://s3.amazonaws.com/pytorch/models/resnet18-5c106cde.pth', '/tmp/temporary_file')
torch.hub.load_state_dict_from_url:在给定的 URL 处加载 Torch 序列化对象。ps:如果下载的文件是 zip 文件,则会自动解压缩。如果对象已经存在于model_dir中,则将其反序列化并返回。
state_dict = torch.hub.load_state_dict_from_url('https://s3.amazonaws.com/pytorch/models/resnet18-5c106cde.pth')
torch.hub.get_dir:获取用于存储下载模型和权重的 Torch Hub 缓存目录
torch.hub.set_dir:可选择设置用于保存下载模型和权重的 Torch Hub 目录
1.5 其他探索方式
PyTorch Hub 中可用的模型也支持Colab,并直接链接到Papers With Code,您只需单击一下即可开始使用。比如下面paper with code,找到一片文章的代码,如下所示:
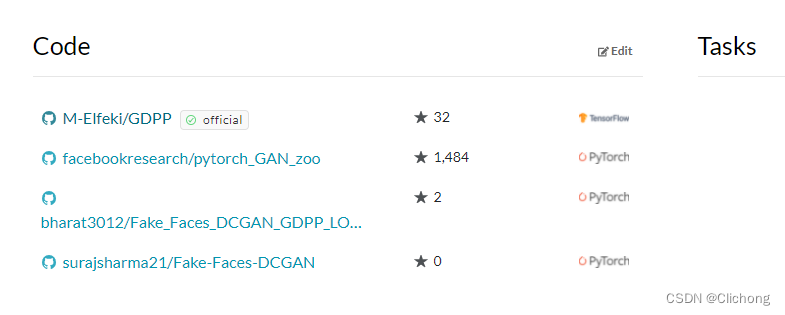
如果其支持pytorch hub操作的话,就可以直接查询其所支持的模型:
torch.hub.list('facebookresearch/pytorch_GAN_zoo')
# 输出:
Downloading: "https://github.com/facebookresearch/pytorch_GAN_zoo/zipball/main" to /root/.cache/torch/hub/main.zip
['DCGAN', 'PGAN', 'StyleGAN']
下面直接挑选 PGAN 这个模型进行人脸生成的例子:模型的输入是形状为 (N,512) 的噪声向量,其中 N 是要生成的图像数量。它可以使用函数 .buildNoiseData 来构造。该模型有一个 .test 函数,它接收噪声向量并生成图像。
import torch
import torchvision
import matplotlib.pyplot as plt
# 一行命令加载模型
model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub',
'PGAN', model_name='celebAHQ-512',
pretrained=True, useGPU=True)
# 获取生成图像
num_images = 64
noise, _ = model.buildNoiseData(num_images)
with torch.no_grad():
generated_images = model.test(noise)
# 显示并排版图像
grid = torchvision.utils.make_grid(generated_images.clamp(min=-1, max=1), nrow=8, scale_each=True, normalize=True)
plt.figure(figsize=(12, 12))
plt.imshow(grid.permute(1, 2, 0).cpu().numpy())
输出64张生成的人头图像,结果如下所示:

ps:以上代码我都是在Colab上进行的,偷了个懒,懒得专门新建一个项目了。而且是基于官方的Colab稍微更改。
2. PyTorch Hub加载YOLOv5
本想这继续在Colab中尝试调用的,但是出现报错了各种无法debug的环境,是项目本身的问题,只能远程调用服务器的环境,在jupyter notebook中测试了。
以下内容参考官方资料:https://github.com/ultralytics/yolov5/issues/36
- 简单实例
从 PyTorch Hub 加载预训练的 YOLOv5s 模型,model并传递图像进行推理。其中yolov5s是最轻最快的 YOLOv5 型号。
import torch
import os
# 设置在0卡上
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
# 1. 模型加载
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True)
model.cuda()
# print(model)
# set image
image = 'https://ultralytics.com/images/zidane.jpg'
# Inference
print('start inference image...')
results = model(image)
# 2. 推理结果处理
print(results.pandas().xyxy[0])
输出结果:
Downloading: "https://github.com/ultralytics/yolov5/archive/master.zip" to /home/fs/.cache/torch/hub/master.zip
requirements: tqdm>=4.64.0 not found and is required by YOLOv5, attempting auto-update...
requirements: 'pip install tqdm>=4.64.0' skipped (offline)
YOLOv5 2022-8-6 Python-3.9.7 torch-1.11.0+cu102 CUDA:0 (Tesla T4, 15110MiB)
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
Adding AutoShape...
start inference image...
xmin ymin xmax ymax confidence class name
0 742.974854 48.395416 1141.844482 720.000000 0.881052 0 person
1 442.007629 437.522400 496.653992 709.973572 0.675213 27 tie
2 123.024139 193.287354 715.662231 719.723877 0.665814 0 person
3 982.803162 308.417358 1027.365845 419.987000 0.260075 27 tie
在上面的操作中,yolov5的pytorch hub调用其实主要分为两个操作方面:一个是模型的加载方面,另外一个是推理结果的处理上面。
- 批量处理实例
此示例显示了PIL和OpenCV图像源的批量推理。可以打印到控制台,保存到,在支持的环境中显示到屏幕上,并以张量或pandas数据帧的形式返回。
import cv2
import torch
from PIL import Image
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Images
for f in 'zidane.jpg', 'bus.jpg':
torch.hub.download_url_to_file('https://ultralytics.com/images/' + f, f) # download 2 images
im1 = Image.open('zidane.jpg') # PIL image
im2 = cv2.imread('bus.jpg')[..., ::-1] # OpenCV image (BGR to RGB)
imgs = [im1, im2] # batch of images
# Inference
results = model(imgs, size=640) # includes NMS
# Results
results.print()
results.save() # or .show()
results.xyxy[0] # im1 predictions (tensor)
results.pandas().xyxy[0] # im1 predictions (pandas)
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
2.1 模型加载处理
- 模型设置
YOLOv5 模型包含各种推理属性,例如置信度阈值、IoU 阈值等,可以通过以下方式设置
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
model.conf = 0.25 # NMS confidence threshold
iou = 0.45 # NMS IoU threshold
agnostic = False # NMS class-agnostic
multi_label = False # NMS multiple labels per box
classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
max_det = 1000 # maximum number of detections per image
amp = False # Automatic Mixed Precision (AMP) inference
results = model(im, size=320) # custom inference size
- 设备设置
模型创建后可以转移到任何设备,在推理之前,输入图像会自动传输到正确的模型设备。
model.cpu() # CPU
model.cuda() # GPU
model.to(device) # i.e. device=torch.device(0)
# 模型也可以直接在任何device
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU
- 静默设置
模型可以静默加载 _verbose=False
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently
- 输入通道设置
要加载具有 4 个输入通道而不是默认的 3 个输入通道的预训练 YOLOv5s 模型,在这种情况下,模型将由预训练的权重组成,除了第一个输入层,它不再与预训练的输入层具有相同的形状。输入层将保持由随机权重初始化。
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
- 类别数设置
要加载具有 10 个输出类而不是默认的 80 个输出类的预训练 YOLOv5s 模型。在这种情况下,模型将由预训练的权重组成,除了输出层,它们不再与预训练的输出层具有相同的形状。输出层将保持由随机权重初始化。
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
- 强制重新加载设置
如果您在上述步骤中遇到问题,force_reload=True 通过丢弃现有缓存并强制从 PyTorch Hub 重新下载最新的 YOLOv5 版本,设置可能会有所帮助。
实践证明不添加这个参数一般都会报错,所以这里推荐直接加上。
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload`在这里插入代码片`
- 训练设置
要加载 YOLOv5 模型进行训练而不是推理,请设置 autoshape=False . 要加载具有随机初始化权重的模型(从头开始训练),请使用 pretrained=False. 在这种情况下,您必须提供自己的训练脚本。
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch
但是,如果是想自定义的训练yolov5的模型,就没有必要用pytorch hub了,因为pytorch hub的主要目的就是为了最简便的让你可以调用已经训练好的模型来进行任务的处理。
- 自定义模型设置
对于使用自己数据集而训练出来的模型,同样可以加载这些训练好的自定义模型权重。此示例使用 PyTorch Hub 加载自定义 20 类VOC训练的YOLOv5s 模型 'best.pt'。
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt') # local model
model = torch.hub.load('path/to/yolov5', 'custom', path='path/to/best.pt', source='local') # local repo
- TensorRT、ONNX 和 OpenVINO 模型
PyTorch Hub 支持对大多数 YOLOv5 导出格式进行推理,包括自定义训练模型。(这方面我暂时不了解)
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.engine') # TensorRT
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.onnx') # ONNX
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s_openvino_model/') # OpenVINO
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.torchscript') # TorchScript
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.mlmodel') # CoreML (macOS-only)
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.tflite') # TFLite
2.2 推理结果处理
- 推理设置
可以自定义图像的推理大小
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
results = model(im, size=320) # custom inference size
- 截图推理设置
要在桌面屏幕上运行推理
import torch
from PIL import ImageGrab
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Image
im = ImageGrab.grab() # take a screenshot
# Inference
results = model(im)
- 裁剪结果设置
结果可以返回并保存为检测作物
results = model(im) # inference
crops = results.crop(save=True) # cropped detections dictionary
在对应的 run/detect/run 目录下,就会保留对于的被裁减无的图像,这里以人图像为例。
裁剪人物1:

裁剪人物2:

- 表格(pandas)结果设置
结果可以作为 Pandas DataFrames返回
results = model(im) # inference
out = results.pandas().xyxy[0] # Pandas DataFrame
print(out)
结果输出:
xmin ymin xmax ymax confidence class name
0 742.974854 48.395416 1141.844482 720.000000 0.881052 0 person
1 442.007629 437.522400 496.653992 709.973572 0.675213 27 tie
2 123.024139 193.287354 715.662231 719.723877 0.665814 0 person
3 982.803162 308.417358 1027.365845 419.987000 0.260075 27 tie
- 排序(sort)结果设置
结果可以按列排序,即从左到右(x轴)排序车牌数字检测
results = model(im) # inference
out = results.pandas().xyxy[0].sort_values('xmin') # sorted left-right
print(out)
结果输出:
xmin ymin xmax ymax confidence class name
2 123.024139 193.287354 715.662231 719.723877 0.665814 0 person
1 442.007629 437.522400 496.653992 709.973572 0.675213 27 tie
0 742.974854 48.395416 1141.844482 720.000000 0.881052 0 person
3 982.803162 308.417358 1027.365845 419.987000 0.260075 27 tie
- JSON结果设置
.pandas() 使用该 .to_json() 方法转换为数据帧后,可以以 JSON 格式返回结果。可以使用orient参数修改 JSON 格式。
results = model(im) # inference
out = results.pandas().xyxy[0].to_json(orient="records") # JSON img1 predictions
print(out)
结果输出:
[
{
"xmin":749.5,"ymin":43.5,"xmax":1148.0,"ymax":704.5,"confidence":0.8740234375,"class":0,"name":"person"},
{
"xmin":433.5,"ymin":433.5,"xmax":517.5,"ymax":714.5,"confidence":0.6879882812,"class":27,"name":"tie"},
{
"xmin":115.25,"ymin":195.75,"xmax":1096.0,"ymax":708.0,"confidence":0.6254882812,"class":0,"name":"person"},
{
"xmin":986.0,"ymin":304.0,"xmax":1028.0,"ymax":420.0,"confidence":0.2873535156,"class":27,"name":"tie"}
]
参考资料:
1. PyTorch Hub发布!一行代码调用所有模型:torch.hub
边栏推荐
- 7. yaml
- 高校就业管理系统设计与实现
- 【C语言】数据储存详解
- 14. Thymeleaf
- Lens filter---about day and night dual-pass filter
- Jvm.分析工具(jconsole,jvisualvm,arthas,jprofiler,mat)
- How to recover deleted files from the recycle bin, two methods of recovering files from the recycle bin
- Web-based meal ordering system in epidemic quarantine area
- call,apply,bind指定函数的this指向详解,功能细节,严格和非严格模式下设定this指向
- 只会懒汉式和饿汉式 你还不懂单例模式!
猜你喜欢

In 22 years, the salary of programmers nationwide in January was released, only to know that there are so many with annual salary of more than 400,000?

Why do programming languages have the concept of variable types?

iNFTnews | Web3时代,用户将拥有数据自主权
Excel English automatic translation into Chinese tutorial
【C语言】数据储存详解
[C language] Detailed explanation of data storage
特殊类与类型转换
Design and implementation of flower online sales management system
SQL injection base - order by injection, limit, wide byte
Based on the SSM to reach the phone sales mall system
随机推荐
App的回归测试,有什么高效的测试方法?
给肯德基打工的调料商,年赚两亿
How to determine how many bases a number is?
promise详解
基于Web的疫情隔离区订餐系统
深度学习 Transformer架构解析
[C language articles] Expression evaluation (implicit type conversion, arithmetic conversion)
App regression testing, what are the efficient testing methods?
Talking about jsfuck coding
推进牛仔服装的高质量发展
软件测试证书(1)—— 软件评测师
分布式.性能优化
Deep Learning Transformer Architecture Analysis
C language% (%d,%c...)
Software protection scenario of NOR FLASH flash memory chip ID application
【C语言篇】表达式求值(隐式类型转换,算术转换)
Web APIs BOM- 操作浏览器之综合案例
excel英文自动翻译成中文教程
定时器,同步API和异步API,文件系统模块,文件流
工程师如何对待开源