当前位置:网站首页>SQL数据库
SQL数据库
2022-04-23 14:01:00 【脱发程序员】
https://blog.csdn.net/qq_36582604/article/details/80526287 ???
MySQL下载与安装
intellij怎么导入MySQL的驱动包
SQL 常用命令行大全【高级程序员必备】
PLSQLDeveloper安装与配置
UML类图
依赖关系 与UML图
uml 类图依赖与关联的区别
1.什么是SQL
SQL(Structured Query Language)是“结构化查询语言”,它是对关系型数据库的操作语言。它可以应用到所有关系型数据库中,例如:MySQL、Oracle、SQL Server等。SQL标准有:
1986年,ANSI X3.135-1986,ISO/IEC 9075:1986,SQL-86
1989年,ANSI X3.135-1989,ISO/IEC 9075:1989,SQL-89
1992年,ANSI X3.135-1992,ISO/IEC 9075:1992,SQL-92(SQL2)
1999年,ISO/IEC 9075:1999,SQL:1999(SQL3)
2003年,ISO/IEC 9075:2003,SQL:2003
2008年,ISO/IEC 9075:2008,SQL:2008
2011年,ISO/IEC 9075:2011,SQL:2011
2016年,ISO/IEC 9075:2016,SQL:2016
这些标准就与JDK的版本一样,在新的版本中总要有一些语法的变化。不同时期的数据库对不同标准做了实现。
虽然SQL可以用在所有关系型数据库中,但很多数据库还都有标准之后的一些语法,我们可以称之为“方言”。例如MySQL中的LIMIT语句就是MySQL独有的方言,其它数据库都不支持!当然,Oracle或SQL Server都有自己的方言。
2.SQL语法要求
SQL语句可以单行或多行书写,以分号结尾;
可以用空格和缩进来来增强语句的可读性;
关键字不区别大小写,建议使用大写;
3.分类
DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;
DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据);
DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
DQL(Data Query Language):数据查询语言,用来查询记录(数据)。
4. 行查(DQL语法):
SELECT
selection_list /*要查询的列名称*/
FROM
table_list /*要查询的表名称*/
WHERE
condition /*行条件*/
GROUP BY
grouping_columns /*对结果分组*/
HAVING
condition /*分组后的行条件*/
ORDER BY
sorting_columns /*对结果分组*/
LIMIT
offset_start(0开始), row_count /*结果限定*/
执行顺序:
-
FROM 和 JOINs
FROM 或 JOIN会第一个执行,确定一个整体的数据范围. 如果要JOIN不同表,可能会生成一个临时Table来用于 下面的过程。总之第一步可以简单理解为确定一个数据源表(含临时表) -
WHERE
我们确定了数据来源 WHERE 语句就将在这个数据源中按要求进行数据筛选,并丢弃不符合要求的数据行,所有的筛选col属性 只能来自FROM圈定的表. AS别名还不能在这个阶段使用,因为可能别名是一个还没执行的表达式 -
GROUP BY
如果你用了 GROUP BY 分组,那GROUP BY 将对之前的数据进行分组,统计等,并将是结果集缩小为分组数.这意味着 其他的数据在分组后丢弃. -
HAVING
如果你用了 GROUP BY 分组, HAVING 会在分组完成后对结果集再次筛选。AS别名也不能在这个阶段使用. -
SELECT
确定结果之后,SELECT用来对结果col简单筛选或计算,决定输出什么数据. -
DISTINCT
如果数据行有重复DISTINCT 将负责排重. -
ORDER BY
在结果集确定的情况下,ORDER BY 对结果做排序。因为SELECT中的表达式已经执行完了。此时可以用AS别名. -
LIMIT / OFFSET
最后 LIMIT 和 OFFSET 从排序的结果中截取部分数据.
4.1 基础查询
select 不一定是列名,可以是函数,运算过后的
查询所有列
SELECT * FROM 表名;
查询单个或多个列,中间用逗号隔开
SELECT 列名1 [,列名2...列名n] FROM 表名;
查询不同的值,即相同的值只出现一次
SELECT DISTINCT * FROM 表名;
SELECT DISTINCT 列名1 [,列名2...列名n] FROM 表名;
列运算后查询(数量类型的列可以做加、减、乘、除运算,字符串会转化成数字,如果不能就是NULL)
SELECT 列名*1.5 FROM 表名;
SELECT 列名1+列名2 FROM 表名;
列连接后查询(此处示例用逗号隔开)
SELECT CONCAT(列名1,',', 列名2[.....]) FROM 表名;
列为空时转换查询(表达式1为null则显示表达式2)
SELECT IFNULL(表达式1, 表达式2) FROM emp;
给列起别名后查询
SELECT 列名 AS 别名 FROM 表名;
mysql中+的作用:
1、加法运算
①两个操作数都是数值型
100+1.5
②其中一个操作数为字符型
将字符型数据强制转换成数值型,如果无法转换,则直接当做0处理
'张无忌'+100===>100
③其中一个操作数为null
null+null====》null
null+100====》 null


如果查询的值为null,则查不出来,
4.2 条件查询 where子句
| Operator(关键字) | Condition(意思) | SQL Example(例子) |
|---|---|---|
| AND、OR、NOT | 组合多个条件 | Not col_name =‘DLL’ |
| =、!=、<>、<、<=、>、>= | Standard numerical operators 基础的 大于,等于等比较 | col_name != 4 |
| BETWEEN … AND … | Number is within range of two values (inclusive) 在两个数之间 | col_name BETWEEN 1.5 AND 10.5 |
| NOT BETWEEN … AND … | Number is not within range of two values (inclusive) 不在两个数之间 | col_name NOT BETWEEN 1 AND 10 |
| IS NULL | 为空 | col_name IS NULL |
| IS NOT NULL | 不为空 | col_name IS NOT NULL |
| LIKE、NOT LIKE | 可以接正则表达式,’_‘匹配一个任意字符,’%‘匹配0~N个任意字符,‘[]’匹配方括号内字符集的其中一个字符,如[ABC],ABC前可加’^'表示否定一个集合。(方括号不是所有DBMS都支持) | col_name LIKE ‘FISH%’ |
| · | test for set menbership集合成员 | · |
| IN (…) | Number exists in a list 在一个列表 | col_name IN (‘DLL’,‘DWW’) |
| NOT IN (…) | Number does not exist in a list 不在一个列表 | col_name NOT IN (1, 3, 5) |
| · | set comparison集合比较 | |
| some | 列表中任意一个 | where salary > some (select budget from department ) ; |
| all | 列表中任何一个 | where salary > all (select budget from department ) ; |
| · | test for empty sets用于相关子查询 | · |
| exists | 如果子查询里有结果,则会显示对应ID,否则不显示 | select ID from instructor where exists (select * from advisor where i_id=ID); |
| · | test for set containment用于相关子查询,例如查集合间包含关系 | · |
| not exists | 如果子查询里没有结果,则会显示对应ID,否则不显示。 例X⊆Y(s)⇔X-Y(s)=Φ⇔not exists ( X except Y(s) ) 例子Y(s)的s是student;第一个子查询是查生物系所有课,第二个组查询是循环查每一个学生选的课,然后差集如果是空,说明x里有的y也有,说明他把生物系的课全选了。 |
 |
| · | test for duplicate tuples | · |
| unique | 只有子查询结果没有重复,才显示 例子为查找2009年最多开了一次课的课程 |
 |
| not unique | 只有子查询结果有重复,才显示 |
如要匹配特殊符号就加 “\ ”转义字符或者“escape”自定义转义字符,escape后面会定义一个转移字符,例如例子中第一个下划线是通配符,第二个下划线由于escape就变成了一个单纯的下划线符号
SELECT field1, field2,...fieldN
FROM table_name
WHERE field1 LIKE '_$_' ESCAPE '$'; 等价于WHERE field1 LIKE '_\_' ;
注意
通配符%看起来像是可以匹配任何东西,但有个例外,这就是NULL。
子句WHERE prod_name like '%'不会匹配产品名称为NULL的行。
4.3 排序查询 ORDER BY子句
执行顺序:①from ②where ③select④order by
排序列表可以是单个列、多个列、表达式、函数、列数、以及以上的组合,多个表达式直接逗号隔开
升序 order by xxx asc;asc可以省略,默认升序
降序 order by xxx desc;
按列位置排序:order by 2,3即先按第二列排序,再按第三列排序
4.4 分组查询 group by子句
where后不支持加分组函数,因为where在group by前面,还没分组,所以不认识分组函数,选用having是分组后筛选,相当于having是过滤分组
#案例1:查询每个工种的员工平均工资
SELECT AVG(salary),job_id
FROM employees
GROUP BY job_id;
#案例2:查询每个领导的手下人数
SELECT COUNT(*),manager_id
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id;
#2)可以实现分组前的筛选
#案例1:查询邮箱中包含a字符的 每个部门的最高工资
SELECT MAX(salary) 最高工资,department_id
FROM employees
WHERE email LIKE ‘%a%’
GROUP BY department_id;
#案例2:查询每个领导手下有奖金的员工的平均工资
SELECT AVG(salary) 平均工资,manager_id
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY manager_id;
#3)可以实现分组后的筛选
#案例1:查询哪个部门的员工个数>5
#分析1:查询每个部门的员工个数
SELECT COUNT(*) 员工个数,department_id
FROM employees
GROUP BY department_id
#分析2:在刚才的结果基础上,筛选哪个部门的员工个数>5
SELECT COUNT(*) 员工个数,department_id
FROM employees
GROUP BY department_id
HAVING COUNT(*)>5;
#案例2:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
SELECT job_id,MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary)>12000;
#案例3:领导编号>102的 每个领导手下的最低工资大于5000的最低工资
#分析1:查询每个领导手下员工的最低工资
SELECT MIN(salary) 最低工资,manager_id
FROM employees
GROUP BY manager_id;
#分析2:筛选刚才1的结果
SELECT MIN(salary) 最低工资,manager_id
FROM employees
WHERE manager_id>102
GROUP BY manager_id
HAVING MIN(salary)>5000 ;
#4)可以实现排序
#案例:查询没有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序
#分析1:按工种分组,查询每个工种有奖金的员工的最高工资
SELECT MAX(salary) 最高工资,job_id
FROM employees
WHERE commission_pct IS NULL
GROUP BY job_id
#分析2:筛选刚才的结果,看哪个最高工资>6000
SELECT MAX(salary) 最高工资,job_id
FROM employees
WHERE commission_pct IS NULL
GROUP BY job_id
HAVING MAX(salary)>6000
#分析3:按最高工资升序
SELECT MAX(salary) 最高工资,job_id
FROM employees
WHERE commission_pct IS NULL
GROUP BY job_id
HAVING MAX(salary)>6000
ORDER BY MAX(salary) ASC;
#5)按多个字段分组
#案例:查询每个工种每个部门的最低工资,并按最低工资降序
#提示:工种和部门都一样,才是一组
工种 部门 工资
1 10 10000
1 20 2000
2 20
3 20
1 10
2 30
2 20
SELECT MIN(salary) 最低工资,job_id,department_id
FROM employees
GROUP BY job_id,department_id;
4.5 分组查询 limit子句
按导演名排重列出所有电影(只显示导演),并按导演名正序排列
SELECT distinct director FROM movies order by director;
列出按上映年份最新上线的4部电影
SELECT * FROM movies order by year desc limit 4;
按电影名字母序升序排列,列出前5部电影
SELECT * FROM movies order by title asc limit 5;
按电影名字母序升序排列,列出上一题之后的5部电影
SELECT * FROM movies order by title asc limit 5 offset 5;
如果按片长排列,John Lasseter导演导过片长第3长的电影是哪部,列出名字即可
SELECT title FROM movies where director="John Lasseter" order by length_minutes desc limit 1 offset 2
按导演名字母升序,如果导演名相同按年份降序,取前10部电影给我
SELECT * FROM movies order by director asc,year desc limit 10;
4.6 联结查询(多表查询)
注意要用where限定,不然就是m*n笛卡尔积现象
4.6.1 内连接

一)等值连接
注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定
查询员工名、工种号、工种名
SELECT e.last_name,e.job_id,j.job_title
FROM employees e,jobs j
WHERE e.job_id=j.job_id;
一般用SQL99语法 【INNER】 JOIN xx ON:
SQL92和SQL99的区别:
SQL99,使用JOIN关键字代替了之前的逗号,并且将连接条件和筛选条件进行了分离,提高阅读性!!!
SELECT last_name,department_name
FROM departments d
JOIN employees e
ON e.department_id =d.department_id;
二)非等值连接
案例1:查询员工的工资和工资级别
SELECT salary,grade_level
FROM employees e,job_grades g
WHERE salary BETWEEN g.lowest_sal AND g.highest_sal
SQL99:
SELECT COUNT(*) 个数,grade
FROM employees e
JOIN sal_grade g
ON e.salary BETWEEN g.min_salary AND g.max_salary
三)自连接
案例:查询 员工名和上级的名称
注意此处用到了同一张表,起了不同别名以引用
SELECT e.employee_id,e.last_name,m.employee_id,m.last_name
FROM employees e,employees m
WHERE e.manager_id=m.employee_id;
SQL99:
SELECT e.last_name,m.last_name
FROM employees e
JOIN employees m
ON e.manager_id=m.employee_id;
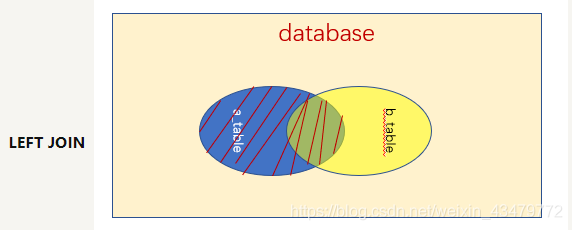
4.6.1 外连接
说明:查询结果为主表中所有的记录,如果从表有匹配项,则显示匹配项;如果从表没有匹配项,则显示null
应用场景:一般用于查询主表中有但从表没有的记录
特点:
1、外连接分主从表,两表的顺序不能任意调换
2、左连接的话,left join左边为主表
3、右连接的话,right join右边为主表


4.7 子查询
概念:
出现在其他语句的内部的select语句,称为子查询或内查询
里面嵌套其他select语句的查询语句,称为主查询或外查询
子查询不一定必须出现在select语句内部,只是出现在select语句内部的时候较多!
示例:
select first_name from employees where department_id >(
select department_id from departments
where location_id=1700
)
分类:
按子查询出现的位置进行分类:
1、select后面
要求:子查询的结果为单行单列(标量子查询)
2、from后面
要求:子查询的结果可以为多行多列
3、where或having后面 *
要求:子查询的结果必须为单列
单行子查询
多行子查询
4、exists后面
要求:子查询结果必须为单列(相关子查询)
说明:
1、子查询语句需要放在小括号内,提高代码的阅读性
2、子查询先于主查询执行,一般来讲,主查询会用到子查询的结果
3、如果子查询放在条件中,一般来讲,子查询需要放在条件的右侧
示例:where job_id>(子查询)
不能写成:where (子查询)<job_id
4、单行子查询对应的使用单行操作符:> < >= <= = <>
多行子查询对应的使用多行操作符:in 、any 、all 、not in

#二)多行子查询
/*
in:判断某字段是否在指定列表内
x in(10,30,50)
any/some:判断某字段的值是否满足其中任意一个
x>any(10,30,50)
x>min()
x=any(10,30,50)
x in(10,30,50)
all:判断某字段的值是否满足里面所有的
x >all(10,30,50)
x >max()
LIMIT用来限定查询结果的起始行,以及总行数。
#案例1:返回location_id是1400或1700的部门中的所有员工姓名
#①查询location_id是1400或1700的部门
SELECT department_id
FROM departments
WHERE location_id IN(1400,1700)
#②查询department_id = ①的姓名
SELECT last_name
FROM employees
WHERE department_id IN(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
#题目:返回其它部门中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及salary
#①查询job_id为‘IT_PROG’部门的工资
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
#②查询其他部门的工资<任意一个①的结果
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary<ANY(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
);
等价于
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary<(
SELECT MAX(salary)
FROM employees
WHERE job_id = 'IT_PROG'
);
#案例3:返回其它部门中比job_id为‘IT_PROG’部门所有工资都低的员工 的员工号、姓名、job_id 以及salary
#①查询job_id为‘IT_PROG’部门的工资
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
#②查询其他部门的工资<所有①的结果
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary<ALL(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
);
等价于
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary<(
SELECT MIN(salary)
FROM employees
WHERE job_id = 'IT_PROG'
);
#二、放在select后面
#案例;查询部门编号是50的员工个数
SELECT
(
SELECT COUNT(*)
FROM employees
WHERE department_id = 50
) 个数;
#三、放在from后面
#案例:查询每个部门的平均工资的工资级别
#①查询每个部门的平均工资
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
#②将①和sal_grade两表连接查询
SELECT dep_ag.department_id,dep_ag.ag,g.grade
FROM sal_grade g
JOIN (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) dep_ag ON dep_ag.ag BETWEEN g.min_salary AND g.max_salary;
#四、放在exists后面
#案例1 :查询有无名字叫“张三丰”的员工信息
SELECT EXISTS(
SELECT *
FROM employees
WHERE last_name = 'Abel'
) 有无Abel;
#案例2:查询没有女朋友的男神信息
USE girls;
SELECT bo.*
FROM boys bo
WHERE bo.`id` NOT IN(
SELECT boyfriend_id
FROM beauty b
)
SELECT bo.*
FROM boys bo
WHERE NOT EXISTS(
SELECT boyfriend_id
FROM beauty b
WHERE bo.id = b.boyfriend_id
);
4.8 分页查询,使用LIMIT
特点:
①起始条目索引如果不写,默认是0
②limit后面支持两个参数
参数1:显示的起始条目索引
参数2:条目数
公式:
假如要显示的页数是page,每页显示的条目数为size
select *
from employees
limit (page-1)*size,size;
page size=10
1 limit 0,10
2 limit 10,10
3 limit 20,10
4 limit 30,10
4.9 联合查询
#进阶9:联合查询
说明:当查询结果来自于多张表,但多张表之间没有关联,这个时候往往使用联合查询,也称为union查询
语法:
select 查询列表 from 表1 where 筛选条件
union
select 查询列表 from 表2 where 筛选条件
特点:
1、多条待联合的查询语句的查询列数必须一致,查询类型、字段意义最好一致
2、union实现去重查询
union all 实现全部查询,包含重复项
3、对组合查询结果排序只能使用一条ORDER BY子句,必须位于最后一条SELECT语句之后。对于结果集不存在用一种方式排序一部分,而又用另一种方式排序另一部分的情况,因此不允许使用多条ORDER BY子句。
#案例:查询所有国家的年龄>20岁的用户信息
SELECT * FROM usa WHERE uage >20 UNION
SELECT * FROM chinese WHERE age >20 ;
#案例2:查询所有国家的用户姓名和年龄
SELECT uname,uage FROM usa
UNION
SELECT age,name FROM chinese;
#案例3:union自动去重/union all 可以支持重复项
SELECT 1,‘范冰冰’
UNION ALL
SELECT 1,‘范冰冰’
UNION ALL
SELECT 1,‘范冰冰’
UNION ALL
SELECT 1,‘范冰冰’ ;
另外还有intersect(交集)和except(差集),用法一样
5 函数:
MySQL数据库提供了很多函数包括:
数学函数;
字符串函数;
日期和时间函数;
条件判断函数;流程控制函数;
系统信息函数;
加密函数;
格式化函数;
| 数学函数 | 说明 |
|---|---|
ABS(x) |
返回x的绝对值 |
CEIL(x) |
返回大于x的最小整数值 |
FLOOR(x) |
返回大于x的最大整数值 |
MOD(x,y) |
返回x/y的模 |
RAND(x) |
返回0~1的随机值 |
ROUND(x,y) |
返回参数x的四舍五入的有y位的小数的值 |
TRUNCATE(x,y) |
返回数字x截断为y位小数的结果 |
SQRT(x) |
返回x的平方根 |
POW(x,y) |
返回x的y次方 |
| 字符串函数 | 说明 |
|---|---|
| CONCAT(S1,S2,…,Sn) | 连接S1,S2,…,Sn为一个字符串 |
| CONCAT(s, S1,S2,…,Sn) | 同CONCAT(s1,s2,…)函数,但是每个字符串之间要加上s |
CHAR_LENGTH(s) |
返回字符串s的字符数 |
LENGTH(s) |
返回字符串s的字节数,和字符集有关 |
INSERT(str, index , len, instr) |
将字符串str从第index位置开始,len个字符长的子串替换为字符串instr |
UPPER(s) 或 UCASE(s) |
将字符串s的所有字母转成大写字母 |
LOWER(s) 或LCASE(s) |
将字符串s的所有字母转成小写字母 |
LEFT(s,n) |
返回字符串s最左边的n个字符 |
RIGHT(s,n) |
返回字符串s最右边的n个字符 |
LPAD(str, len, pad) |
用字符串pad对str最左边进行填充,直到str的长度为len个字符 |
RPAD(str ,len, pad) |
用字符串pad对str最右边进行填充,直到str的长度为len个字符 |
| LTRIM(s) | 去掉字符串s左侧的空格 |
| RTRIM(s) | 去掉字符串s右侧的空格 |
| TRIM(s) | 去掉字符串s开始与结尾的空格 |
| TRIM(【BOTH 】s1 FROM s) | 去掉字符串s开始与结尾的s1 |
TRIM(【LEADING】s1 FROM s) |
去掉字符串s开始处的s1 |
| TRIM(【TRAILING】s1 FROM s) | 去掉字符串s结尾处的s1 |
| REPEAT(str, n) | 返回str重复n次的结果 |
| REPLACE(str, a, b) | 用字符串b替换字符串str中所有出现的字符串a |
STRCMP(s1,s2) |
比较字符串s1,s2 |
| SUBSTRING(s,index,len) | 返回从字符串s的index位置其len个字符 |
| 日期时间函数 | 说明 |
|---|---|
CURDATE() 或 CURRENT_DATE() |
返回当前日期 |
CURTIME() 或 CURRENT_TIME() |
返回当前时间 |
NOW()、SYSDATE()、CURRENT_TIMESTAMP()、LOCALTIME()、LOCALTIMESTAMP() |
返回当前系统日期时间 |
| YEAR(date)、MONTH(date)、DAY(date)、HOUR(time)、MINUTE(time)、SECOND(time) | 返回具体的时间值 |
| WEEK(date)、WEEKOFYEAR(date) | 返回一年中的第几周 |
| DAYOFWEEK() | 返回周几,注意:周日是1,周一是2,。。。周六是7 |
| WEEKDAY(date) | 返回周几,注意,周1是0,周2是1,。。。周日是6 |
| DAYNAME(date) | 返回星期:MONDAY,TUESDAY…SUNDAY |
| MONTHNAME(date) | 返回月份:January,。。。。。 |
DATEDIFF(date1,date2) |
返回date1 - date2的日期间隔 |
| TIMEDIFF(time1, time2) | 返回time1 - time2的时间间隔 |
| DATE_ADD(datetime, INTERVALE expr type) | 返回与给定日期时间相差INTERVAL时间段的日期时间 |
DATE_FORMAT(datetime ,fmt) |
按照字符串fmt格式化日期datetime值 |
STR_TO_DATE(str, fmt) |
按照字符串fmt对str进行解析,解析为一个日期 |

select date_format('1998-07-16 00:00:00', '%Y年 %m月%d日%H小时%i分钟%s秒');
结果如下:

select str_to_date('08/09/2008', '%m/%d/%Y'); -- 2008-08-09
select str_to_date('08/09/08' , '%m/%d/%y'); -- 2008-08-09
select str_to_date('08.09.2008', '%m.%d.%Y'); -- 2008-08-09
select str_to_date('08:09:30', '%h:%i:%s'); -- 08:09:30
select str_to_date('08.09.2008 08:09:30', '%m.%d.%Y %h:%i:%s'); -- 2008-08-09 08:09:30

| 分组(聚合)函数 | 说明 |
|---|---|
| COUNT() | 统计指定列不为NULL的记录行数; |
| MAX() | 计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算; |
| MIN() | 计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算; |
| SUM() | 计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0; |
| AVG() | 计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0; |


5. DML(Data Manipulation Language)行数据操纵语言
5.1 行增 INSERT
5.1.1 单行增:
insert into 表名[(字段名1,字段名2 ,...)] values (值1,值2,...);
5.1.2 多行增:
insert into 表名(字段名1,字段名2 ,...) values
(值1,值2,...),(值1,值2,...),(值1,值2,...);
特点:
①字段和值列表一一对应,包含类型、约束等必须匹配
②数值型的值,不用单引号,非数值型的值,必须使用单引号
③字段顺序无要求
④如果插入的数据可以为空或者默认的,可以不写对应字段名和值,也可以把值写NULL\DEFAULT
5.1.3 插入检索出的数据 INSERT SELECT
INSERT INTO 表名
SELECT COLUMNS
FROM sourceTableName;
5.1.4 从一个表复制刀另一个表 SELECT INTO
SELECT COLUMNS
INTO newTableName
FROM sourceTableName
where whereExpression ;
5.2 更新和修改数据 UPDATE
单表修改语法,逗号隔开:
UPDATE 表名 SET 列名1=值1, … 列名n=值n [WHERE 条件]
多表修改语法:
UPDATE 表1 【inner】 john 表2 on 表 SET 列名1= 新值1,列名2 =新值2
【where 筛选条件】
5.3 删除数据
单表删除语法:
①DELETE FROM 表名 [WHERE 条件];
②TRUNCATE TABLE 表名;(全删,后面不能加where)
虽然TRUNCATE和DELETE都可以删除表的所有记录,但有原理不同。DELETE的效率没有TRUNCATE高!
TRUNCATE其实属性DDL语句,因为它是先DROP TABLE,再CREATE TABLE。而且TRUNCATE删除的记录是无法回滚的,但DELETE删除的记录是可以回滚的。DELETE后从断点插入数据
多表删除语法:
DELETE 表名 FROM 表1 别名1 INNER JOIN 表2 别名2 on 连接条件 where
6. DDL(Data Definition Language)数据定义语言
Data Define Language数据定义语言,用于对数据库和表的管理和操作
6.1 库的管理
6.1.1 创建数据库
CREATE DATABASE stuDB;
CREATE DATABASE IF NOT EXISTS stuDB;
6.1.2 删除数据库
DROP DATABASE stuDB;
DROP DATABASE IF EXISTS stuDB;
6.2 表的管理
6.2.1 创建表
语法:
CREATE TABLE [IF NOT EXISTS] 表名(
字段名 字段类型 【字段约束】,
字段名 字段类型 【字段约束】,
字段名 字段类型 【字段约束】,
字段名 字段类型 【字段约束】,
字段名 字段类型 【字段约束】
);
字段约束可以有多个,中间用空格隔开
字段类型:
字段类型详细看:https://www.w3school.com.cn/sql/sql_datatypes.asp
以下为Mysql:
| TEXT类型 | 说明 |
|---|---|
| CHAR(size) | 保存固定长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的长度。最多 255 个字符。 |
| VARCHAR(size) | 保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多 255 个字符。注释:如果值的长度大于 255,则被转换为 TEXT 类型。 |
| TINYTEXT | 存放最大长度为 255 个字符的字符串。 |
| TEXT | 存放最大长度为 65,535 个字符的字符串。 |
| BLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 65,535 字节的数据。 |
| MEDIUMTEXT | 存放最大长度为 16,777,215 个字符的字符串。 |
| MEDIUMBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 16,777,215 字节的数据。 |
| LONGTEXT | 存放最大长度为 4,294,967,295 个字符的字符串。 |
| LONGBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。 |
| ENUM(x,y,z,etc.) | 允许输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。 注释:这些值是按照你输入的顺序存储的。 可以按照此格式输入可能的值:ENUM(‘X’,‘Y’,‘Z’) |
| SET | 与 ENUM 类似,SET 最多只能包含 64 个列表项,不过 SET 可存储一个以上的值。 |
| NUMBER类型 | 说明 |
|---|---|
| TINYINT(size) | -128 到 127 常规。0 到 255 无符号*。在括号中规定最大位数。 |
| SMALLINT(size) | -32768 到 32767 常规。0 到 65535 无符号*。在括号中规定最大位数。 |
| MEDIUMINT(size) | -8388608 到 8388607 普通。0 to 16777215 无符号*。在括号中规定最大位数。 |
| INT(size) | -2147483648 到 2147483647 常规。0 到 4294967295 无符号*。在括号中规定最大位数。 |
| BIGINT(size) | -9223372036854775808 到 9223372036854775807 常规。0 到 18446744073709551615 无符号*。在括号中规定最大位数。 |
| FLOAT(size,d) | 带有浮动小数点的小数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DOUBLE(size,d) | 带有浮动小数点的大数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DECIMAL(size,d) | 作为字符串存储的 DOUBLE 类型,允许固定的小数点。 |
- 这些整数类型拥有额外的选项 UNSIGNED。通常,整数可以是负数或正数。如果添加 UNSIGNED 属性,那么范围将从 0 开始,而不是某个负数。
| Date类型 | 说明 |
|---|---|
| DATE() | 日期。格式:YYYY-MM-DD。注释:支持的范围是从 ‘1000-01-01’ 到 ‘9999-12-31’ |
| DATETIME() | *日期和时间的组合。格式:YYYY-MM-DD HH:MM:SS。注释:支持的范围是从 ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’ |
| TIMESTAMP() | *时间戳。TIMESTAMP 值使用 Unix 纪元(‘1970-01-01 00:00:00’ UTC) 至今的描述来存储。格式:YYYY-MM-DD HH:MM:SS。注释:支持的范围是从 ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-09 03:14:07’ UTC |
| TIME() | 时间。格式:HH:MM:SS 注释:支持的范围是从 ‘-838:59:59’ 到 ‘838:59:59’ |
| YEAR() | 2 位或 4 位格式的年。注释:4 位格式所允许的值:1901 到 2155。2 位格式所允许的值:70 到 69,表示从 1970 到 2069。 |
- 即便 DATETIME 和 TIMESTAMP 返回相同的格式,它们的工作方式很不同。在 INSERT 或 UPDATE 查询中,TIMESTAMP 自动把自身设置为当前的日期和时间。TIMESTAMP 也接受不同的格式,比如 YYYYMMDDHHMMSS、YYMMDDHHMMSS、YYYYMMDD 或 YYMMDD。
约束:
| 表级约束 | 说明 |
|---|---|
| PRIMARY KEY 主键 | 用于限制该字段值不能重复,设置为主键列的字段默认不能为空。一个表只能有一个主键,当然可以是组合主键 |
| UNIQUE 唯一 | 用于限制该字段值不能重复 |
| CHECK检查 | 用于限制该字段值必须满足指定条件。示例:CHECK(age BETWEEN 1 AND 100) |
| FOREIGN KEY 外键 | 用于限制两个表的关系,要求外键列的值必须来自于主表的关联列。要求:①主表的关联列和从表的关联列的类型必须一致,意思一样,名称无要求 ②主表的关联列要求必须是主键 |
| 列级约束 | 说明 |
|---|---|
| (NOT NULL)/NULL | 非空 |
| DEFAULT 默认 | 用于限制该字段没有显式插入值,则直接显式默认值 |
mysql里还有AUTO_INCREMENT|自增长,一般用在ID,一张表只能有一个
字段是否可以为空 一个表可以有几个
主键 × 1个
唯一 √ n个



约束名字
可以在约束的前面给这个约束起个名字,下例中只能在oracle用,mysql要在最下面另起一行定义才能起名字。例如
oracle:name varchar(2) constraint xx_name primary key
约束条件的修改
表记约束修改
| 表级约束修改 | 示例 |
|---|---|
| 添加约束 | ALTER TABLE 表名 ADD CONSTRAINT 约束名 表级约束条件; |
| 删除约束 | ALTER TABLE 表名 DROP CONSTRAINT 约束名; |
【训练1】 为emp表的mgr列增加外键约束:
ALTER TABLE emp ADD CONSTRAINT FK_3 FOREIGN KEY(mgr) REFERENCES emp(empno);
【训练2】 删除为emp表的mgr列增加的外键约束:
ALTER TABLE emp DROP CONSTRAINT FK_3;
列级约束的修改(null、default)
| 列级约束修改 | 示例 |
|---|---|
| 添加约束 | ALTER TABLE 表名 MODIFY 列名 约束条件; |
查看定义好的约束
oracle:
SELECT *
FROM user_constraints
WHERE table_name='BOOK';
mysql:
SELECT *
FROM information_schema.`TABLE_CONSTRAINTS`
WHERE table_name='BOOK';
外键约束属性
当一个从表的某个属性参照了主表的主码后,可以为该外码定义属性,当主表的主码发生变化之后,从表对应的实例会根据该属性进行变化。
以下为一个例子

| DELETE项目 | 示例 |
|---|---|
| ON DELETE CASCADE | 主表删除记录时,同步删除从表参照了该主码实例的实例 |
| ON DELETE SET NULL | 主表删除记录时,同步设置从表参照了该主码实例的实例为null |
| ON DELETE NO ACTION | 如果从表中有实例参照了该主码实例,则报错,不给删主码 |
| ON DELETE RESTRICT | 和NO ACTION一样 |
| UPDATE项目 | 示例 |
|---|---|
| ON UPDATE CASCADE | 主表修改记录时,同步修改从表参照了该主码实例的实例 |
| ON UPDATE SET NULL | 主表修改记录时,同步设置从表参照了该主码实例的实例为null |
| ON UPDATE NO ACTION | 如果从表中有实例参照了该主码实例,则报错,不给改主码 |
| ON UPDATE RESTRICT | 和NO ACTION一样 |
通过事务暂时解除约束

约束的开启和关闭
使约束条件失效:
ALTER TABLE 表名 DISABLE CONSTRANT 约束名;
使约束条件生效:
ALTER TABLE 表名 ENABLE CONSTRANT 约束名;
断言
断言的概念:是一种命名约束,它表达了数据库状态必须满足的逻辑条件
语法:
create assertion <assertion-name> check <predicate>
例子:student表里的总学分必须等于他完成的课程的学分总和
create assertion credits_earned_constraint check
(not exists (
select ID
from student
where tot_cred <> (select sum(credits)
from takes natural join course
where student.ID = takes.ID
and grade is not null
and grade <> ‘F’) ;
6.2.2 修改表
语法:
ALTER TABLE 表名 ADD|MO DIFY|CHANGE|DROP COLUMN 字段名 字段类型 【字段约束】;
| 项目 | 示例 |
|---|---|
| 添加列 | 给stus表添加classname列:ALTER TABLE stu ADD (classname varchar(100)); |
| 修改列类型 | 修改stu表的gender列类型为CHAR(2):ALTER TABLE stus MODIFY gender CHAR(2); |
| 修改列名 | 修改stu表的gender列名为sex:ALTER TABLE stus CHANGE gender sex CHAR(2); |
| 删除列 | 删除stsu表的classname列:ALTER TABLE stus DROP classname; oracle里删除单列在drop后加column,多列不用 |
| 修改表名称 | 修改stu表名称为student:ALTER TABLE stus RENAME TO student; |
修改列定义还有以下一些特点:
(1) 列的宽度可以增加或减小,在表的列没有数据或数据为NULL时才能减小宽度。
(2) 在表的列没有数据或数据为NULL时才能改变数据类型,CHAR和VARCHAR2之间可以随意转换。
(3) 只有当列的值非空时,才能增加约束条件NOT NULL。
(4) 修改列的默认值,只影响以后插入的数据。
6.2.3 删除表
DROP TABLE IF EXISTS students;
6.2.4 复制表(oracle在第一个表名后面要加as)
#仅仅复制表的结构,MySQL√,Oracle×
CREATE TABLE newTable2 LIKE major;
#复制表的结构+数据,mysql可加可不加as,oracle要加;
如果只要结构,可以加个where 1=2
CREATE TABLE newTable3 (AS) SELECT * FROM girls.beauty;
案例:复制employees表中的last_name,department_id,salary字段到新表 emp表,但不复制数据
CREATE TABLE emp (AS)
SELECT last_name,department_id,salary
FROM myemployees.`employees`
WHERE 1=2;
7. 事务属于TCL控制语言(Transaction Control Language )
7.1 事务概述
什么是事务?为什么要用事务?
一个事务是由一条或者多条sql语句构成,这一条或者多条sql语句要么全部执行成功,要么全部执行失败!
默认情况下,每条单独的sql语句就是一个单独的事务!
举例:
银行转账!张三转10000块到李四的账户,这其实需要两条SQL语句:
给张三的账户减去10000元;
给李四的账户加上10000元。
如果在第一条SQL语句执行成功后,在执行第二条SQL语句之前,程序被中断了(可能是抛出了某个异常,也可能是其他什么原因),那么李四的账户没有加上10000元,而张三却减去了10000元。这肯定是不行的!
你现在可能已经知道什么是事务了吧!事务中的多个操作,要么完全成功,要么完全失败!不可能存在成功一半的情况!也就是说给张三的账户减去10000元如果成功了,那么给李四的账户加上10000元的操作也必须是成功的;否则给张三减去10000元,以及给李四加上10000元都是失败的!
7.2事务的四大特性(ACID)
①原子性(Atomicity):事务中所有操作是不可再分割的原子单位。事务中所有操作要么全部执行成功,要么全部执行失败。
②一致性(Consistency):事务执行后,数据库状态与其它业务规则保持一致。如转账业务,无论事务执行成功与否,参与转账的两个账号余额之和应该是不变的。
③隔离性(Isolation):隔离性是指在并发操作中,不同事务之间应该隔离开来,使每个并发中的事务不会相互干扰。
④持久性(Durability):一旦事务提交成功,事务中所有的数据操作都必须被持久化到数据库中,即使提交事务后,数据库马上崩溃,在数据库重启时,也必须能保证通过某种机制恢复数据。
7.3 MySql中的事务
在默认情况下,MySQL每执行一条SQL语句,都是一个单独的事务。如果需要在一个事务中包含多条SQL语句,那么需要开启事务和结束事务。
开启事务:start transaction
结束事务:commit或rollback
在执行SQL语句之前,先执行strat transaction,这就开启了一个事务(事务的起点),然后可以去执行多条SQL语句,最后要结束事务,commit表示提交,即事务中的多条SQL语句所做出的影响会持久化到数据库中。或者rollback,表示回滚,即回滚到事务的起点,之前做的所有操作都被撤消了!
分类:
隐式事务:没有明显的开启和结束标记
比如dml语句的insert、update、delete语句本身就是一条事务
insert into stuinfo values(1,'john','男','[email protected]',12);
显式事务:具有明显的开启和结束标记
一般由多条sql语句组成,必须具有明显的开启和结束标记
演示事务
步骤:
取消隐式事务自动开启的功能
1、开启事务
2、编写事务需要的sql语句(1条或多条)
insert into stuinfo values(1,'john','男','[email protected]',12);
insert into stuinfo values(1,'john','男','[email protected]',12);
3、结束事务
SHOW VARIABLES LIKE '%auto%'
#演示事务的使用步骤
#1、取消事务自动开启
SET autocommit = 0;
#2、开启事务
START TRANSACTION;
#3、编写事务的sql语句
#将张三丰的钱-5000
UPDATE stuinfo SET balance=balance-5000 WHERE stuid = 1;
#将灭绝的钱+5000
UPDATE stuinfo SET balance=balance+5000 WHERE stuid = 2;
#4、结束事务
#提交
#commit;
#回滚,会将上一次commit和这次rollback语句之间的操作撤销
ROLLBACK;
8 视图
含义:理解成一张虚拟的表,只保存了sql逻辑,相当于封装了一个sql语句
视图和表的区别:
使用方式 占用物理空间
视图 完全相同 不占用,仅仅保存的是sql逻辑
表 完全相同 占用
视图的好处:
- 可以提高数据访问的
安全性,通过视图往往只可以访问数据库中表的特定部分,限制了用户访问表的全部行和列。 简化了对数据的查询,隐藏了查询的复杂性。视图的数据来自一个复杂的查询,用户对视图的检索却很简单。- 一个视图可以
检索多张表的数据,因此用户通过访问一个视图,可完成对多个表的访问。 - 视图是
相同数据的不同表示,通过为不同的用户创建同一个表的不同视图,使用户可分别访问同一个表的不同部分。
语法:
创建视图(from后面可以跟表名也可以是一个视图名):
CREATE VIEW 视图名
AS
sql查询语句;
例如:
create view faculty
as
select ID, name, dept_name from instructor ;
又例如:
create view departments_total_salary(dept_name, total_salary)
as
xxx
修改视图sql逻辑
方式1:
create or replace view 视图名
as
查询语句;
方式2:
alter view 视图名
as
查询语句;
删除视图;
语法:drop view 视图名,视图名,...;
查看视图结构:
DESC 视图名;
SHOW CREATE VIEW 视图名;
增删改查和普通表的一样
视图的增删改对原表的影响
对于视图的数据的增删改会导致原表进行相对应的变化,但有一些特殊情况会导致原表不会有改动。

以下为不会更新原表的情况:
- 包含以下关键字的sql语句:分组函数、distinct、group by、having、union或者union all
- 常量视图
CREATE OR REPLACE VIEW myv2
AS
SELECT 'john' NAME;
#更新
UPDATE myv2 SET NAME='lucy';
- Select中包含子查询
CREATE OR REPLACE VIEW myv3
AS
SELECT department_id,(SELECT MAX(salary) FROM employees) 最高工资
FROM departments;
#更新
SELECT * FROM myv3;
UPDATE myv3 SET 最高工资=100000;
- join
CREATE OR REPLACE VIEW myv4
AS
SELECT last_name,department_name
FROM employees e
JOIN departments d
ON e.department_id = d.department_id;
#更新
SELECT * FROM myv4;
UPDATE myv4 SET last_name = '张飞' WHERE last_name='Whalen';
INSERT INTO myv4 VALUES('陈真','xxxx');
- from一个不能更新的视图
CREATE OR REPLACE VIEW myv5
AS
SELECT * FROM myv3;
#更新
SELECT * FROM myv5;
UPDATE myv5 SET 最高工资=10000 WHERE department_id=60;
- where子句的子查询引用了from子句中的表
CREATE OR REPLACE VIEW myv6
AS
SELECT last_name,email,salary
FROM employees
WHERE employee_id IN(
SELECT manager_id
FROM employees
WHERE manager_id IS NOT NULL
);
#更新
SELECT * FROM myv6;
UPDATE myv6 SET salary=10000 WHERE last_name = 'k_ing';
实体化视图
占有实际内存空间
约束
安装过程
https://www.runoob.com/mysql/mysql-install.html
版权声明
本文为[脱发程序员]所创,转载请带上原文链接,感谢
https://blog.csdn.net/weixin_43479772/article/details/106635221
边栏推荐
- try --finally
- Record a strange bug: component copy after cache component jump
- STM32 learning record 0007 - new project (based on register version)
- [code analysis (7)] communication efficient learning of deep networks from decentralized data
- Postman reference summary
- Port occupied 1
- Using Baidu Intelligent Cloud face detection interface to achieve photo quality detection
- [code analysis (2)] communication efficient learning of deep networks from decentralized data
- 变长参数__VA_ARGS__ 和 写日志的宏定义
- Oracle告警日志alert.log和跟踪trace文件中文乱码显示
猜你喜欢
How does redis solve the problems of cache avalanche, cache breakdown and cache penetration

Jenkins construction and use
try --finally
Quartus Prime硬件实验开发(DE2-115板)实验一CPU指令运算器设计

商家案例 | 运动健康APP用户促活怎么做?做好这几点足矣
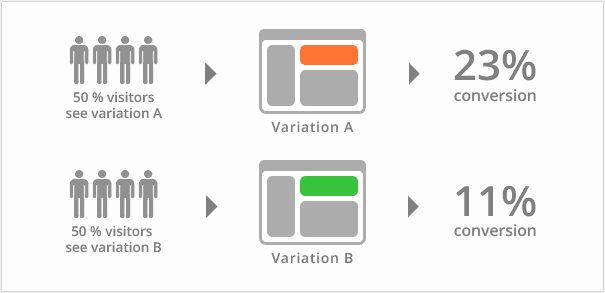
蓝绿发布、滚动发布、灰度发布,有什么区别?
【项目】小帽外卖(八)
Record a strange bug: component copy after cache component jump
Oracle alarm log alert Chinese trace and trace files

Port occupied 1
随机推荐
leetcode--357. 统计各位数字都不同的数字个数
L2-024 部落 (25 分)
Ptorch classical convolutional neural network lenet
Android: answers to the recruitment and interview of intermediate Android Development Agency in early 2019 (medium)
crontab定时任务输出产生大量邮件耗尽文件系统inode问题处理
UNIX final exam summary -- for direct Department
Strange bug of cnpm
Quartus Prime硬件实验开发(DE2-115板)实验二功能可调综合计时器设计
Chapter 15 new technologies of software engineering
JS 烧脑面试题大赏
Function executes only the once function for the first time
Force deduction brush question 101 Symmetric binary tree
关于stream流,浅记一下------
scikit-learn構建模型的萬能模板
freeCodeCamp----time_ Calculator exercise
New关键字的学习和总结
What is the difference between blue-green publishing, rolling publishing and gray publishing?
收藏博客贴
生产环境——
生成随机高质量符合高斯分布的随机数