当前位置:网站首页>Shell编程之正则表达式
Shell编程之正则表达式
2022-08-09 07:54:00 【眼下一颗柠檬】
文章目录
一、正则表达式
1.正则表达式的定义
正则表达式又称正规表达式、常规表达式。在代码中常简写为regex、regexp或RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说,是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配一个或多个字符串。
正则表达式一般用于脚本编程与文本编辑器中。
2.正则表达式的分类
正则表达式的字符串表达方法根据不同的严谨程度与功能与功能分为基本正则表达式与扩展正则表达式。基础正则表达式式正则表达式最基础的部分。在Linux系统中常见的文件处理工具中的grep与sed支持基础正则表达式,而egrep与awk支持扩展正则表达式。
二、grep和元字符
1.grep
| 常用选项 | 功能 |
|---|---|
| -n | 列出所匹配的文本行,并显示行号 |
| -i | 匹配时忽略字符大小写 |
| -v | 反向匹配,匹配的字符串与搜索的不相符 |
| -w | 精确匹配。匹配整个单词、一个字符 |
| -o | 只显示匹配的部分 |
| -c | 显示匹配内容的行数 |
| -E | 开启扩展的正则表达式 |
| –color=auto | 可以将找到的关键词部分加上颜色的显示 |
2.元字符
| 元字符 | 功能 |
|---|---|
| ^ | 匹配输入字符串的开始为止。除非在方括号表达式中使用,表示不办函该字符集合。要匹配"^ “字符本身,需要转义”\ ^" |
| $ | 匹配输入字符串的结尾位置。如果设置了RegExp对象的Multiline属性,则"$"也匹配’\n’或’r’ |
| . | ".“代表除”\n\s"之外的任何单个字符 |
| \ | 反斜杠,又叫转义字符,去除其后紧跟的元字符或通配符的特殊意义 |
| * | 匹配前面的子表达式零次或多次。要匹配"*"字符,要进行\转义 |
| [ ] | 字符集合,匹配所包含的任意的一个字符 |
| [^] | 复制字符集。匹配未包含在[ ]内的任意一个字符 |
| [n1-n2] | 字符范围。匹配指定范围内的任意一个字符。例如[a-z]可以匹配到a到z范围内的任意一个小写字母字符 |
| {n} | n是一个非负整数,匹配确定的n次,例如“o{2}”不能匹配“Bob”中的“o”,但是能匹配到“food”中的“oo” |
| {n,} | n是一个非负整数,至少(最少)匹配n次。例如,“o{2,}”不能匹配"Bob"中的“o”,但是能匹配“fooooood”中的所有o。“o{1.}”等于“o+” |
| {n,m} | n和m均为非负整数,其中n<=m,最少匹配n次,最多匹配m次 |
三、正则匹配
准备一个名为test.txt的文件演示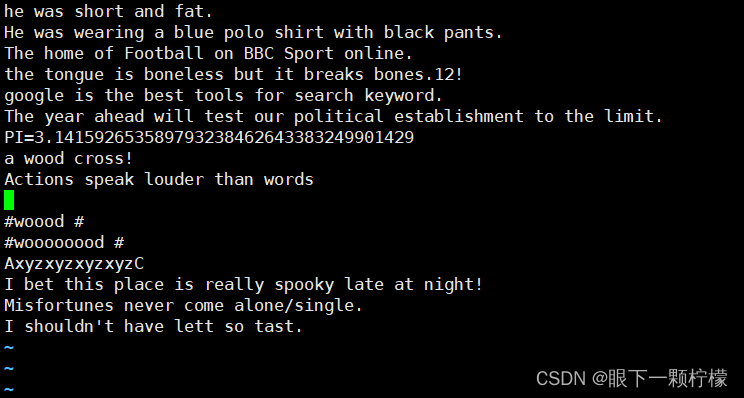
1.查找特定字符
查找特定字符非常简单,如执行一下命令即可从test.txt文件中查找特定字符"the"所在位置。-n表示显示行号、-i表示不区分大小写

若反向选择,如查找不包括"the"字符的行,则需要通过grep命令的"-v"选项实现,并配合"-n"一起使用显示行号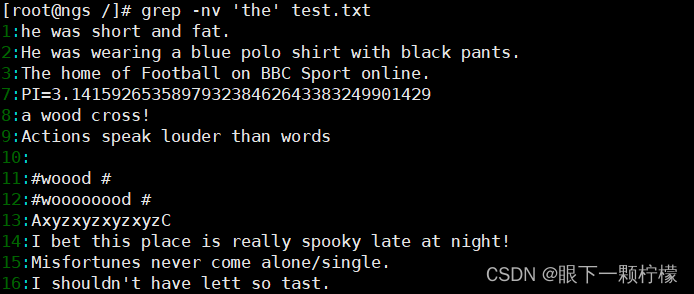
2.利用中括号"[]"来查找集合字符
想要查找"shirt"与"short"这两个字符串时,可以发现这两个字符串均包括"sh"与"rt"。磁性执行一下即可同时查找到"shirt"与"short"这两个字符串,其中"[]“中无论有几个字符,都仅代表一个字符,也就是说”[io]“表示匹配"i"或者"o”
查找包含重复单个字符"oo"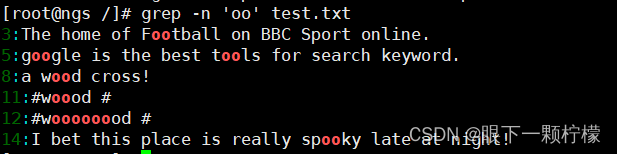
若查找"oo"前面不是"w"的字符串,只需要通过集合字符的反向选择"[^]"来实现该目的
在上述命令的执行结果中发现“woood”与“wooooood”也符合匹配规则,二者均包含“w”。 其实通过执行结果就可以看出,符合匹配标准的字符加粗显示,而上述结果中可以得知, “#woood #”中加粗显示的是“ooo”,而“oo”前面的“o”是符合匹配规则的。同理“#woooooood #” 也符合匹配规则。
若不希望“oo”前面存在小写字母可以使用"grep -n ‘[ ^a-z]oo’ test.txt"实现。
其中,“a-z”表示小写字母,大写字母则通过“A-Z”表示。
查找包含数字的行可以通过"grep -n ‘[0-9]’ test.txt"命令
3.查找行首"^“与行尾字符”$"
基础正则表达式包含两个定位元字符:“^”(行首)与"$“(行尾)。如果想要查询以"the"字符串为行首的行,则可以通过” ^"元字符来实现。
查询以小写字母开头的行可以通过"^a-z"规则来过滤,查询大写字母开头的行则使用" ^A-Z"规则,若查询不以字母开头的行则使用" ^ [ ^a-zA-Z]"规则
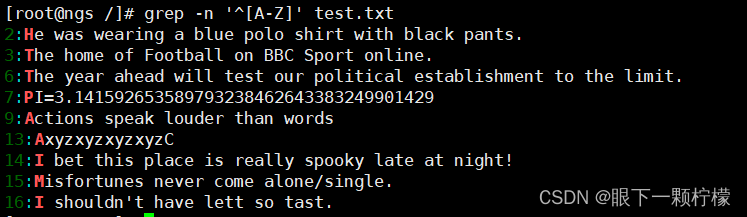

"^“符号在元字符集合”[]“符号内外的作用时不一样的,在”[]“符号内表示反向选择,在”[]"符号外则代表定位行首。繁殖,若想查找以某一特定字符结尾的行则可以使用 $定位符。
执行以下命令即可实现查询以小数点”.“结尾的行。因为小数点".“在正则表达式中也是一个元字符,所以需要用转义字符”"将具有特殊意义的字符转化成普通字符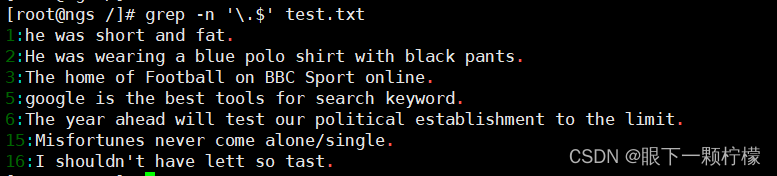
当查询空白行时,执行"grep -n ‘^$’ test.txt"即可
4.查找任意一个字符".“与重复字符”*"
在正则表达式中小数点"."也是一个元字符,代表任意一个字符。
执行"grep -n ‘w…d’ test.txt"可以查找"w??d"的字符串,即共有四个字符,以w开头d结尾
若想要查询oo、ooo、oooo等资料,则需要使用星号""元字符。
""代表的时重复零个或多个前面的单字符。"o"表示拥有零个(即空字符)或大于等于一个"o"的字符,因为允许空字符,所以执行"grep -n 'o’ test.txt"会将文本中的所有内容都输出打印。**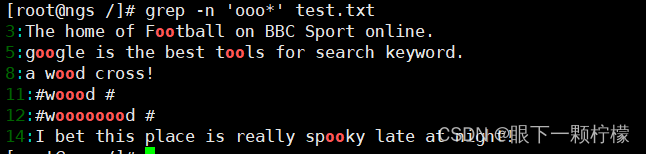
查询以w开头d结尾,中间包含至少一个o的字符串
查询以w开头d结尾,中间的字符可有可无的字符串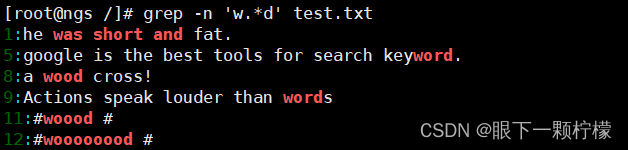
查询任意数字所在行
5.查找连续字符范围"{}"
如果要查找三到五个的连续字符,这个时候就需要使用基础正则表达式中的限定范围的字符"{}“。因为”{}“在Shell中具有特殊意义,所以在使用”{}“字符时,需要利用转义字符”“,将”{}"字符转换成普通字符
查询两个o的字符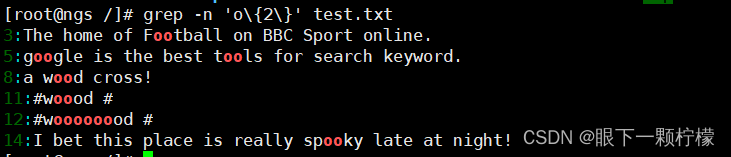
查询以w开头以d竭而亡i,中间包含2~5个o的字符
查询以w开头以d结尾,中间报班两个或两个以上o的字符串
四、扩展正则表达式
通常情况下会使用基础正则表达式就已经足够了,但有时为了简化整个指令,需要使用范围更广的扩展正则表达式。例如使用基础这个则表达式查询除文件中空白行与行首为"#"之外的行,使用grep -v ‘^$’ test.txt |grep -v ’ ^#‘即可实现。这里需要使用管道命令来搜索两次。如果使用扩展正则表达式,可以简化为egrep -v ’ ^ $ | ^#’ test.txt,其中单引号中的管道符号表示或者(or)
此外,grep命令仅支持基础正则表达式,如果使用扩展正则表达式,需要使用egrep或awk命令。egrep命令与grep命令的用大基本相似。egrep命令是收缩文件获得模式,使用该命令可以搜索文件获得模式,使用该命令可以搜索文件中的任意字符串和符号,也可以收缩一个或多个文件的字符串,一个提示符一课时单个字符、一个字符串、一个字或一个句子。
扩展正则表达式常见元字符
+
作用:重复一个或者一个以上的前一个字符
示例:执行"egrep -n 'wo+d' test.txt"命令,即可查询"wood" "woood" "wooood"等字符串
?
作用:零个或者一个的前一个字符
示例:执行"egrep -n 'bes?t' test.txt"命令,即可查询“bet”“best”这两个字符串
|
作用:使用或者(or)的方式找出多个字符
示例:执行"egrep -n 'of|is|on' test.txt"命令即可查询"of"或者"if"或者"on"字符串
()
作用:查找“组”字符串
示例:"egrep -n 't(a|e)st' test.txt"。"tast"与"test"因为这两个单词的"t"与"st"是重复的,所以将"a"与"e" 列于“()”符号当中,并以"|"分隔,即可查询"tast"或者"test"字符串
()+
作用:辨别多个重复的组
示例:"egrep -n 'A(xyz)+C' test.txt"。该命令是查询开头的"A"结尾是"C",中间有一个以上的"xyz"字符串的意思
实用写法
将网卡中的IP地址,子网掩码及广播地址过滤出来
或
查看apache中哪些用户进行了访问
先过滤出日志文件中的IP地址,然后使用sort -n先进行排序,再使用uniq -c进行计数,最后进行倒序排列,输出10行
边栏推荐
猜你喜欢



随机推荐
研发分享:机器学习卡片的使用
Luogu P1110 report statistics multiset stl good question
SAP ALV data export many of the bugs
RAID配置实战
HDU - 3183 A Magic Lamp Segment Tree
Codeforces Round #359 (Div. 2) C. Robbers' watch Violent Enumeration
c语言位段
账户和权限管理2
CoCube传感器MPU6050笔记
C语言:字符逆序
3安装及管理程序
Sklearn data preprocessing
IDEA文件UTF-8格式控制台输出中文乱码
解决pycharm每次新建项目都要重新pip安装一些第三方库等问题
Change Jupyter Notebook default open directory
ssh:connect to host master port 22:Network is unreachable
[STL]stack与queue
EXCEL使用函数联调(find,mid,vlookup,xlookup)
yolov5检测数据集标签数量
.net(三) 项目结构