当前位置:网站首页>[STL]string
[STL]string
2022-08-09 07:48:00 【Protein_zmm】
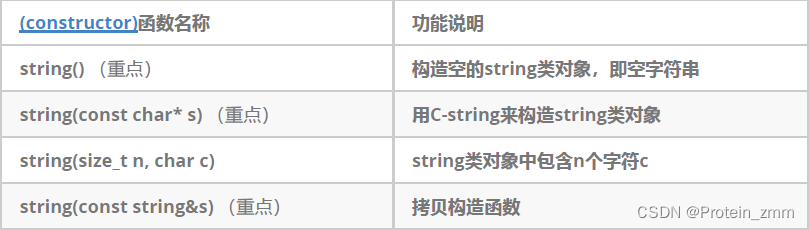
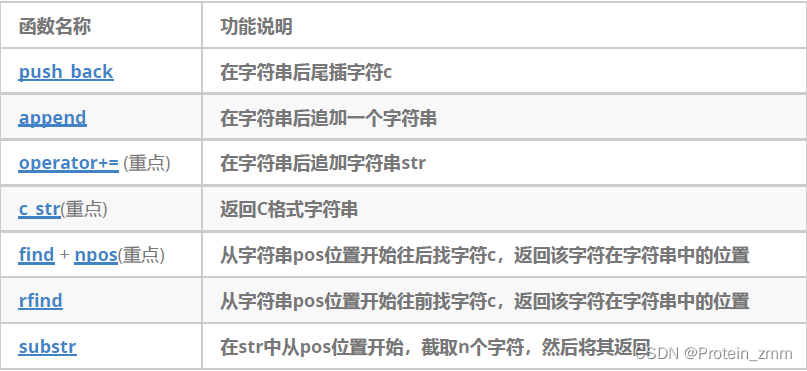
string类常用接口说明
sting类对象的常见构造
c-string就是以\0结束
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s1; // 无参数
string s2("hello world"); //有参数的构造
string s3(s2); // 拷贝构造
string s4(s2, 2, 6);
string s5("hello world", 3); // 只取前三个字符进行初始化
//string(size_t n, char c)含义 n:要初始化的个数,c要填充的字符
string s8(10, '!');
cout << s4 << endl;
cout << s5 << endl;
cout << s8 << endl;
return 0;
}
也可以支持从pos位置开始(下标pos),len个长度开始初始化,最后一个参数给了npos缺省值(是一个静态变量-1)len类型是size_t类型,也就是最大值,相当于就是到\0结束——如string s4
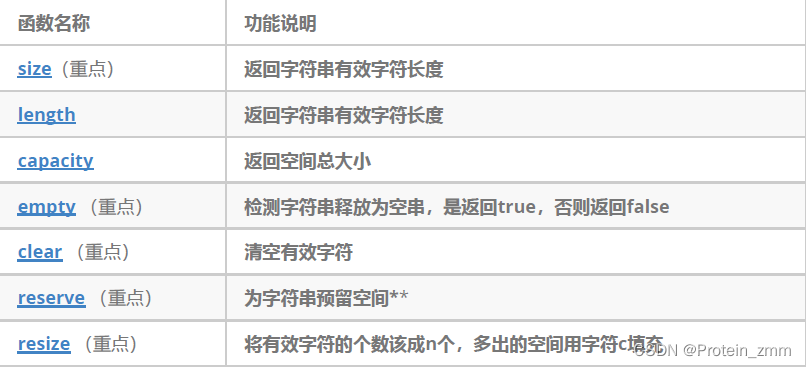
string类对象的容量操作
int main()
{
string s1;
cin >> s1;
// 求字符串有效长度——不包含\0
cout << s1.size() << endl; // 更推荐
cout << s1.length() << endl;
cout << s1.max_size() << endl; // 求字符串的最大长度
cout << s1.capacity() << endl; // 容量大小
s1.clear(); // 把有效字符全部清除
cout << s1 << endl;
cout << s1.capacity() << endl; // clear只清除了数据,但是不清除空间
return 0;
}
string类对象的访问及遍历操作

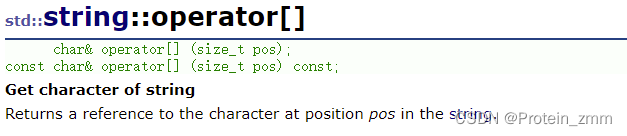
char& operator[] (size_t pos)
{
// 底层就是这样实现的
assert(pos < _size);
return _str[pos];
// 这里的引用返回不是为了减少拷贝,而是为了修改返回对象
}
int main()
{
string s1("hello world");
for (size_t i = 0; i < s1.size(); ++i)
{
cout << s1[i] << " ";
// 等价于
cout << s1.operator[](i) << ""; // 返回每个字符的引用
}
cout << endl;
for (size_t i = 0; i < s1.size(); ++i)
{
s1[i] += 1;
}
cout << s1;
cout << endl;
return 0;
}
[]:数组使用,也就是让字符串可以像数组一样使用数组
以上两个也就是一个可以修改,一个不可以修改
for (size_t i = 0; i < s1.size(); ++i)
{
s1.at(i) -= 1;
}
at和operator[]区别在与:检查越界方式不一样
operator[]是用断言
at是抛异常
string中进行遍历+修改的三种方法
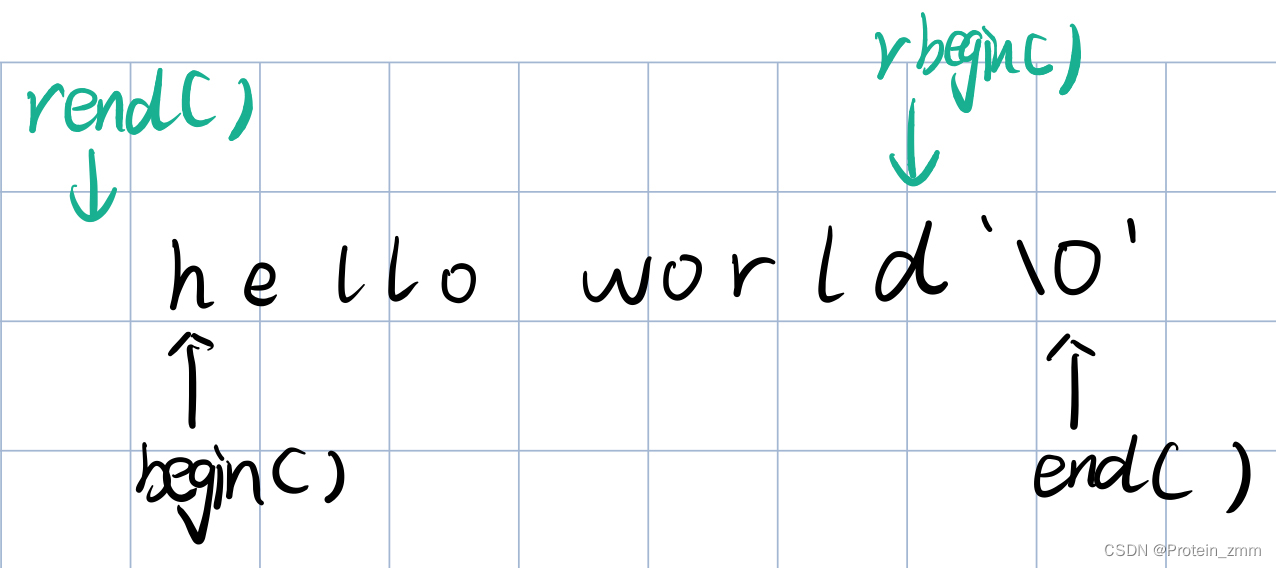
void test_string1()
{
string s1("hello world");
// 遍历+修改
// 1、下标+[]
for (size_t i = 0; i < s1.size(); ++i)
{
s1[i]++;
}
for (size_t i = 0; i < s1.size(); ++i)
{
cout << s1[i];
}
cout << endl;
// 2、迭代器
string::iterator it = s1.begin();
//s1.begin()返回第一个位置的地址
//s1.end()返回最后一个数据的下一个位置的地址也就是\0
//iterator(迭代器)在string类中定义的,先想象成一个像指针一样的类型
//it指向第一个位置也就是h
while (it != s1.end())
{
*it -= 1;
++it;
}
it = s1.begin();
while (it != s1.end())
{
cout << *it;
++it;
}
cout << endl;
// 3、范围for——会自动往后迭代,自动判断结束
//for (auto e : s1)
//{
// e -= 1; // 会发现打印出来并不会影响s1
// // e就是一个拷贝,e改变不会影响s1,所以应该加一个引用
//}
for (auto& e : s1)
{
e -= 1;
}
for (auto e : s1) // 把s1里面每个字符取出来赋值给e
{
cout << e;
}
cout << endl;
}
反向迭代器
void test_string2()
{
string s1("hello world");
string::reverse_iterator rit = s1.rbegin(); // 反向迭代器
// 可以用auto rit = s1.rbegin();
// 倒着遍历
// rbegin是最后一个字符(\0前面的一个字符)
// rend是第一个字符的前一个位置
// 反向迭代器的++是向左走
while (rit != s1.rend())
{
cout << *rit;
++rit;
}
cout << endl;
}
迭代器的意义:所有的容器都可以使用迭代器这种方式去访问,之后的list、map、set都不支持[]访问
正向迭代器——const和非const
void func(const string& s)
{
// string::iterator it = s.begin(); // 此时begin是一个const和iterator不是一个类型
string::const_iterator it = s.begin(); // 这里就必须使用const了
while (it != s.end())
{
*it -= 1; // *it是常量,不能修改
++it;
}
it = s.begin();
while (it != s.end())
{
cout << *it;
++it;
}
}
void test_string3()
{
const string cstr("hello world");
func(cstr);
}
使用反向迭代器——const和非const
void func(const string& s)
{
// string::iterator it = s.begin(); // 此时begin是一个const和iterator不是一个类型
string::const_reverse_iterator it = s.rbegin(); // 这里就必须使用const了
while (it != s.rend())
{
cout << *it;
++it;
}
}
void test_string3()
{
const string cstr("hello world");
func(cstr);
}
C++11针对此加了cbegin、cend(返回const迭代器),实际上不习惯用
sting类对象的修改操作
int main()
{
string s1;
s1.push_back('a'); // 插入一个字符
s1.append("bcde");
cout << s1;
// 可以使用+= ,甚至可以+=一个对象
s1 += ' ';
s1 += "hello world";
cout << s1 << endl;
return 0;
}
研究string的增容
void TestPushBack()
{
string s;
size_t sz = s.capacity();
cout << "making s grow:" << sz << endl;;
for (int i = 0; i < 1000; ++i)
{
// s.push_back('c');
s += 'c';
if (sz != s.capacity())
{
// 只要增容了,就打印一次
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
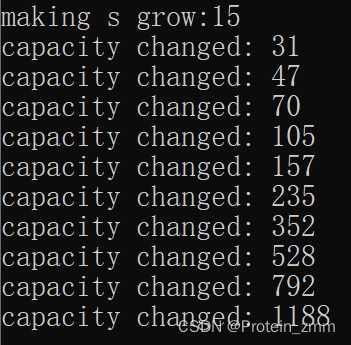
第一个15是有效数据字符,不算入\0
到最后越等于一次增容1.5倍(VS环境下,Linux环境下越等于2倍)
但是每次增容都有代价,因为没有足够的空间为异地增容,数据拷贝过去在释放原来的空间,知道要用多少空间,就用reserve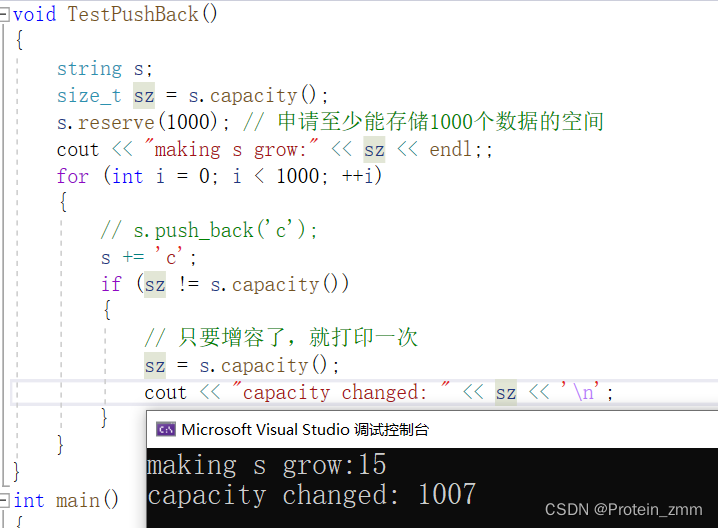
这时候就减少了拷贝,但是虽然是reserve申请了1000,实际上还会大一点——内存对齐
resize():开好空间后还会给一个初始值(\0)也可以给一个指定值,如resize(100,‘x’)
区别在与一个是开空间,另外一个是开空间+初始化
void test_string4()
{
string s1;
s1.reserve(100);
string s2;
s2.resize(100);
// 并不会对已有的数据产生影响
string s3("hello world");
s3.reserve(100); // 扩容
string s4("hello world");
s4.resize(100, 'x'); // 扩容+初始化
}
其余string接口

c_str返回c形式的字符串
void test_string5()
{
string s("hello world");
cout << s.c_str() << endl; // 返回的是const char* 遇到\0结束
cout << s << endl; // 重载了流插入运算符
string file("test.txt");
// 想用c语言的形式打开一个文件
//FILE* fout = fopen(file, "w"); // fopen的第一个参数必须是const char* ,file是string类型因此是错误的
FILE* fout = fopen(file.c_str(), "w"); // fopen的第一个参数必须是const char*
}
字符串的查找:find
从pos位置处开始取一个字符串的子串
void test_string5()
{
string s("hello world");
cout << s.c_str() << endl; // 返回的是const char* 遇到\0结束
cout << s << endl; // 重载了流插入运算符
string file("test.txt");
// 想用c语言的形式打开一个文件
//FILE* fout = fopen(file, "w"); // fopen的第一个参数必须是const char* ,file是string类型因此是错误的
FILE* fout = fopen(file.c_str(), "w"); // fopen的第一个参数必须是const char*
// 要求取出文件的后缀名——find
size_t pos = file.find("."); // 默认从0位置开始找,返回一个第一个匹配的无符号的整型,没找到返回npos(size_t的-1)
if (pos != string::npos)
{
// 从pos位置开始取出子串取len个字符——substr\ // len个长度(算上pos)
string suffix = file.substr(pos, file.size() - pos); // 第二个参数如果不取,默认是size_t的-1
cout << suffix << endl;
}
}
以上代码是取文件的后缀,但是如果要取最后的后缀,如file.txt.zip怎么办?从右往左找——rfind
string file("test.txt.zip");
FILE* fout = fopen(file.c_str(), "w");
size_t pos = file.rfind('.');
if (pos != string::npos)
{
string suffix = file.substr(pos);
cout << suffix << endl;
}
常见的使用方式:
void test_string6()
{
// 分离网址
string url("http://www.cplusplus.com/reference/string/string/find/");
// 分离协议:
size_t pos1 = url.find(':');
string protocol = url.substr(0, pos1 - 0); // 协议
cout << protocol << endl;
// 分离域名.com后面的/结束,从w位置开始找
size_t pos2 = url.find('/', pos1 + 3);
string domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << domain << endl;
string uri = url.substr(pos2 + 1);
cout << uri << endl;
}
尽量少用头部和中间删除,因为要挪动数据,效率太低
void test_string7()
{
// 字符串的插入insert
// 字符串的头/中间插入和删除一般不用——效率低和顺序表一样
string s("hello world");
// 头插,效率是O(n)
s.insert(0, 1, 'x'); // 在头上插入一个x
s.insert(s.begin(), 'y');
s.insert(0, "test");
cout << s << endl;
s.insert(4, "&&&&"); // 第四个位置上插入一些特殊符号
cout << s << endl;
}
void test_string8()
{
string s("hello world");
// 字符串的删除erase
s.erase(0, 1); // 从0位置开始删除一个字符
s.erase(s.size() - 1, 1);
cout << s << endl;
}
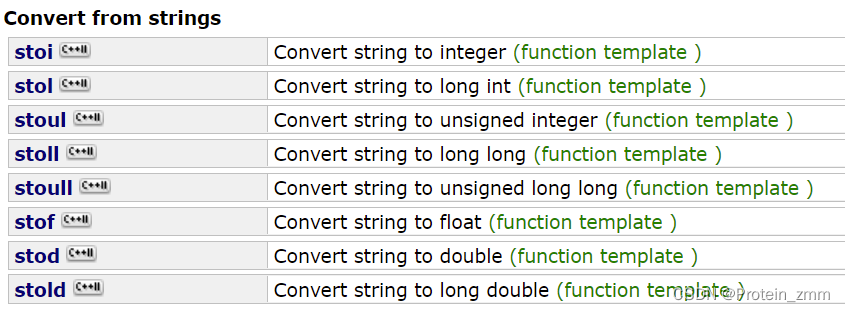
stoi——string to int
stol——string to long
to double、flout等等
to_string——整型转化为字符串
void test_string8()
{
int val = stoi("1234");
cout << val << endl;
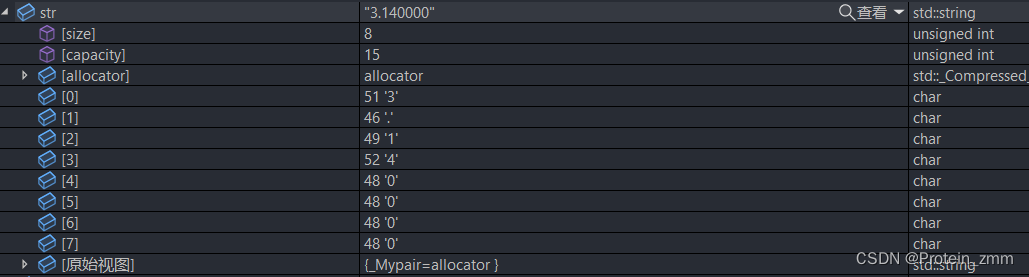
string str = to_string(3.14);
cout << str << endl;
}

逆置
边栏推荐
猜你喜欢



随机推荐
car-price-deeplearning-0411
jmeter并发数量以及压力机的一些限制
(五)、马尔科夫预测模型
JS基础1
【Rust指南】快速入门|开发环境|hello world
74HC595 chip pin description
SAP ALV data export many of the bugs
ImportError: cannot import name ‘imresize‘
【转载】Deep Learning(深度学习)学习笔记整理
(error) NOAUTH Authentication required.
【Template】Tree Chain Segmentation P3384
【模板】树链剖分 P3384
种子数据报错:liquibase.exception.ValidationFailedException: Validation Failed
Tkinter可以选择的颜色
Forest Program DFS + tanjar cactus
Better Scroll Y上下滚动无法上拉滚动解决办法
EXCEL uses function joint debugging (find, mid, vlookup, xlookup)
3.MySQL插入数据, 读取数据、Where子句和Order By关键字
Anaconda replaces the default virtual environment
VOC格式标签转YOLO格式