当前位置:网站首页>Cvpr2022 | efficient pre training based on knowledge distillation
Cvpr2022 | efficient pre training based on knowledge distillation
2022-04-23 21:48:00 【Zhiyuan community】

Thesis link :https://arxiv.org/abs/2203.05180
版权声明
本文为[Zhiyuan community]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/113/202204232144292288.html
边栏推荐
- Ali has another "against the sky" container framework! This kubernetes advanced manual is too complete
- Oracle ora-01033: Oracle initialization or shutdown in progressprocess solution
- Is rust more suitable for less experienced programmers?
- MySQL 回表
- 危机即机遇,远程办公效率为何会提升?
- Arm architecture assembly instructions, registers and some problems
- Yolov5 NMS source code understanding
- How to play the guiding role of testing strategy
- Mixed use of Oracle column row conversion and comma truncated string
- Flomo software recommendation
猜你喜欢

Use 3080ti to run tensorflow GPU = 1 X version of the source code
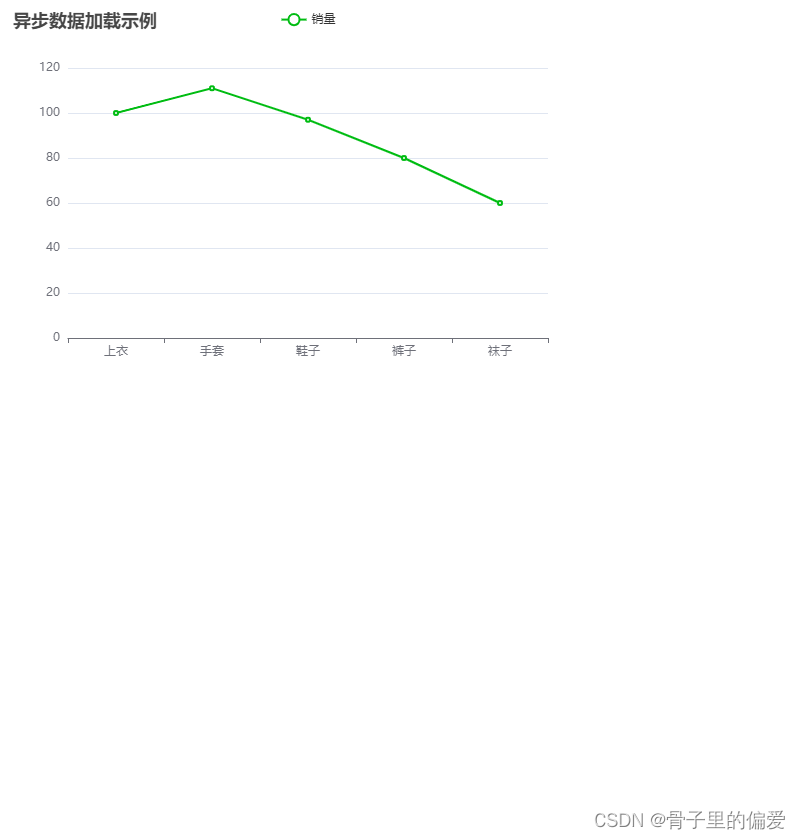
thinkphp5+数据大屏展示效果

Opencv application -- jigsaw puzzle

Xiaomi mobile phone has abandoned the "Mi" brand all over the world and switched to the full name brand of "Xiaomi"
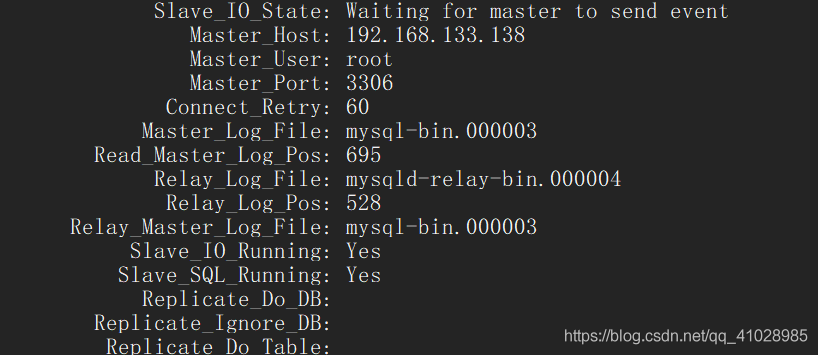
Centos7 builds MySQL master-slave replication from scratch (avoid stepping on the pit)
Flomo software recommendation
![[leetcode refers to offer 10 - I. Fibonacci sequence (simple)]](/img/f9/22a379f330c3ee21a2a386bbd4a98f.png)
[leetcode refers to offer 10 - I. Fibonacci sequence (simple)]
![[※ leetcode refers to offer 46. Translate numbers into strings (medium)]](/img/72/fbdc5d14dada16cd211c99cd8f9d31.png)
[※ leetcode refers to offer 46. Translate numbers into strings (medium)]
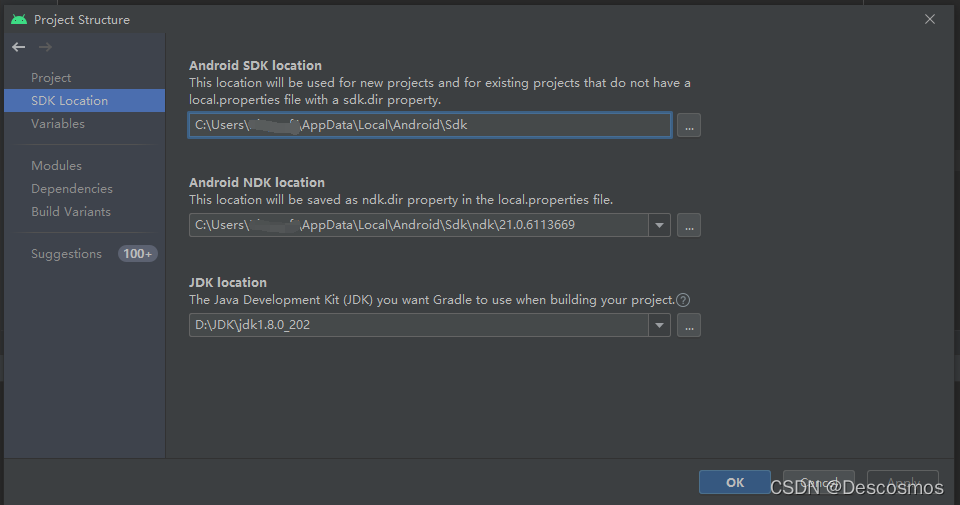
FAILURE: Build failed with an exception. * What went wrong: Execution failed for task ‘:app:stripDe
Display, move, rotate
随机推荐
Pytorch: runtimeerror: an attempt has been made to start a new process Error reporting (resolved)
Presto on spark supports 3.1.3 records
阿里又一个“逆天”容器框架!这本Kubernetes进阶手册简直太全了
1. Finishing huazi Mianjing -- 1
Unit function expansion
Problem brushing plan -- dynamic programming (III)
Pyuninstaller package exe cannot find the source code when running, function error oserror: could not get source code
[leetcode sword finger offer 10 - II. Frog jumping steps (simple)]
[leetcode refers to the two numbers of offer 57. And S (simple)]
Oracle updates the data of different table structures and fields to another table, and then inserts it into the new table
1.整理华子面经--1
[leetcode refers to offer 47. Maximum value of gift (medium)]
JS prototype and prototype chain
How Axure installs a catalog
Database Experiment 2 data query
This paper solves the cross domain problem of browser
Deep analysis of C language function
MySQL 回表
Ubutnu20 installer centernet
[leetcode refers to offer 18. Delete the node of the linked list (simple)]