当前位置:网站首页>亲测有效|处理风控数据特征缺失的一种方法
亲测有效|处理风控数据特征缺失的一种方法
2022-08-10 21:51:00 【番茄风控】
样本数据的特征缺失值处理,在数据建模圈子里是一个老生常谈的话题,虽然看似原理简单但却显得非常重要。在机器学习模型的开发过程中,缺失值的分析与处理往往是数据预处理的一个关键步骤,尤其是针对那些无法自动处理缺失值的模型算法(例如线性回归、逻辑回归等),缺失值处理是一项必要的数据清洗环节。此外,即使是面向那些可以自动处理缺失值的模型算法(例如决策树、朴素贝叶斯、K近邻等),数据的缺失值处理可以有助于模型训练效果的提升。因此,样本特征的缺失值处理不仅是数据预处理的一个模块,而且在很多场景下是优化模型性能的前提条件。
对于特征缺失值处理的方法,我们最常接触的方法是通过字段的统计指标来进行填充。例如,针对连续型特征常采用平均值、最大值、最小值、中位数、众数、加权均值等指标填充;针对离散型特征,常采用众数指标填充。这些方法原理简单易于理解,虽然有时数据处理的精准度有一定欠缺,但在建模数据的预处理情形仍然得到广泛应用。但是,如果要进一步考虑特征缺失值处理的较优效果,也就是使特征缺失情况的填充值可以更加符合字段的实际分布特点,这样的数据处理结果也正是我们所希望的。
结合以上实际场景,本文将为大家介绍一种通过模型训练与预测的思路来进行特征缺失值处理的方法,而模型的具体名称则是我们比较熟悉也是应用非常流行的机器学习算法——随机森林。本文将会采用随机森林的回归模型与分类模型,来分别处理连续型特征与离散型特征的缺失值。这里简单介绍下数据处理的原理逻辑,假设某样本数据的包含6个特征分别为X1~X6,其中特征X1存在缺失值情况,采用随机森林模型填充字段缺失值的过程主要包括以下两种情形:
(1)当特征X1的取值类型为连续型时,以X1作为目标因变量,X2~X6作为特征自变量,采用特征X1非缺失的样本数据来训练拟合回归模型,然后以此模型来预测特征X1缺失样本的目标X1值;
(2)当特征X1的取值类型为离散型时,以X1作为目标因变量,X2~X6作为特征自变量,采用特征X1非缺失的样本数据来训练拟合分类模型,然后以此模型来预测特征X1缺失样本的目标X1值。
以上采用模型来处理特征缺失值的情形,其核心思路是一致的,也就是将存在缺失值的某个特征作为目标变量,其他所有或部分非缺失的特征作为自变量来训练构建模型,然后通过模型预测目标特征的标签值。这里需要注意的是,每次特征缺失值的处理过程仅能针对一个特征变量,理由是模型训练只能有一个Y标签,而X字段额可以自有选择多个。当然,在具体业务场景中,可以通过循环函数来实现样本多个特征的缺失值处理。
通过以上介绍,我们大概熟悉了采用随机森林模型处理特征缺失值的思路,下面我们结合具体的实例数据,来详细分析样本数据特征缺失值的处理过程与实现效果。本文选用的样本数据包含10000条样本与9个特征,具体数据样例如图1所示,其中number为样本主键,var1~var8为特征变量。
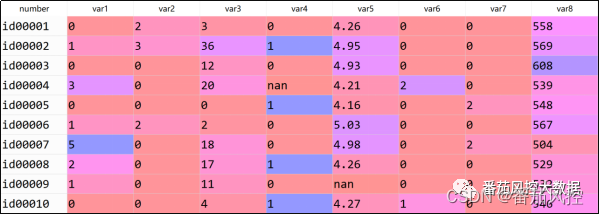
图1 样本数据
根据以上样本数据,我们通过isnull()函数来了解下特征变量的缺失分布情况,实现过程如图2所示,输出结果如图3所示。

图2 特征缺失情况汇总
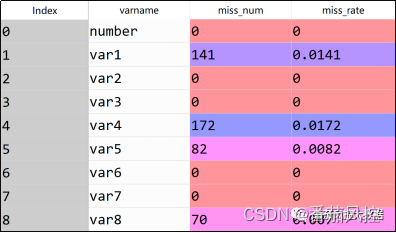
图3 特征缺失情况分布
由以上结果可知,特征变量var1、var4、var5、var8均存在缺失值情况,现对各字段的缺失值进行处理。为了有效采用随机森林模型来实现特征缺失值的填充,此处需要提前分析确定存在缺失值的特征类型,即连续型或离散型,这里决定了随机森林算法是采用回归模型还是分类模型来训练和预测数据。对以上含有缺失值的特征进行取值分布探索,以特征var1为例,其实现过程如图4所示,输出结果如图5所示。

图4 特征var1取值分布实现
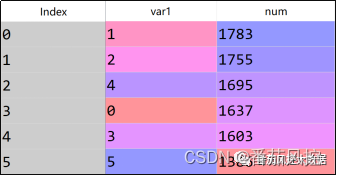
图5 特征var1取值分布结果
由特征var1的取值分布结果可知,var1的取值类型为离散型。按照以上同样的逻辑,对特征var4、var5、var8依次进行分析,最后结果为var1与var4为离散型,var5与var8为连续型。根据特征类型的分析结果,接下来便可以有针对性的采用随机森林算法来解决各特征的缺失值情况,具体过程为特征var1与var4通过随机森林分类模型训练和预测,而var5与var8通过随机森林回归模型实现。其中,离散型特征var1与连续型特征var5的模型处理缺失值过程分别如图6、图7所示。

图6 离散型特征var1缺失值处理

图7 连续型特征var5缺失值处理
以上模型训练过程,自变量数据为由非缺失特征var2、var3、var6、var7构成,以此分别拟合目标变量var1和var5,最后采用各自训练成功的模型来预测特征缺失值数据pred_X,并输出预测结果pred_Y,也就是缺失情况填充后的数值。对于特征var4与var8的缺失值处理,分别对照以上var1和var5的实现步骤,只需要更换data_Y的目标变量即可。当各特征的缺失值处理完成后,为了验证是否有效完成,可以采用df.isnull().sum()函数来进行检验,如果处理正常则日志显示各特征缺失数值均为0。此外,本文案例围绕随机森林模型处理特征缺失值的具体介绍过程,这里需要特别注意以下几个要点:
(1)分析过程中样本数据选取的特征数量有限,在具体实践场景中模型训练的自变量特征数量越多,一般情况下有利于随机森林训练预测精度的提升;
(2)模型训练完成后,考虑引入模型评估环节,当模型相关性能指标欠佳时,可以通过模型参数调整来优化模型,从而保证模型预测的准确度;
(3)当样本存在缺失情况的特征数量较多时,可以自定义模型处理缺失值的函数,自动化实现特征的批量分析与处理,以提高特征数据处理的效率。
综合以上内容,我们采用随机森林分类模型与回归模型,分别实现了样本离散型特征与连续型特征的缺失值处理,这在实际建模场景中有较好的实用性,可以有效提升模型的训练效果。为了便于大家对随机森林模型处理样本特征缺失值的进一步熟悉与理解,本文额外附带了与以上内容同步的样本数据与python代码,详情请移至知识星球查看相关内容。
…
~原创文章
边栏推荐
- shell编程之正则表达式与文本处理器
- 元宇宙社交应用,靠什么吸引用户「为爱发电」?
- 艺术与科技的狂欢,阿那亚2022砂之盒沉浸艺术季
- Alibaba and Ant Group launched OceanBase 4.0, a distributed database, with single-machine deployment performance exceeding MySQL
- VLAN huawei 三种模式
- Likou 215 questions, the Kth largest element in an array
- “数据引擎”开启前装规模量产新赛道,「智协慧同」崭露头角
- ASCII、Unicode和UTF-8
- An article to teach you a quick start and basic explanation of Pytest, be sure to read
- QT笔记——QT工具uic,rcc,moc,qmake的使用和介绍
猜你喜欢
2022年8月的10篇论文推荐
shell (text printing tool awk)
![[Maui official version] Create a cross-platform Maui program, as well as the implementation and demonstration of dependency injection and MVVM two-way binding](/img/07/2baa3bd1d8da0f868fd49b5bdd0527.png)
[Maui official version] Create a cross-platform Maui program, as well as the implementation and demonstration of dependency injection and MVVM two-way binding

xshell (sed command)
H3C S5130 IRF做堆叠
Likou 221 questions, the largest square
C#【必备技能篇】Hex文件转bin文件的代码实现
HighTec快捷键(Keys)设置位置

【PCBA solution】Electronic grip strength tester solution she'ji
威纶通触摸屏如何在报警的同时,显示出异常数据的当前值?
随机推荐
SDP
LeetCode-498-对角线遍历
测试4年感觉和1、2年时没什么不同?这和应届生有什么区别?
What is Jmeter? What are the principle steps used by Jmeter?
元宇宙社交应用,靠什么吸引用户「为爱发电」?
论文解读(g-U-Nets)《Graph U-Nets》
交换机和生成树知识点
camera preview process --- from HAL to OEM
字节跳动原来这么容易就能进去...
Intelligent scheme design - intelligent rope skipping scheme
美味的石井饭
Extended Chinese Remainder Theorem
Live Classroom System 08-Tencent Cloud Object Storage and Course Classification Management
高数_复习_第5章:多元函数微分学
RADIUS Authentication Server Deployment Costs That Administrators Must Know
阿里云贾朝辉:云XR平台支持彼真科技呈现国风科幻虚拟演唱会
阿里巴巴、蚂蚁集团推出分布式数据库 OceanBase 4.0,单机部署性能超 MySQL
艺术与科技的狂欢,阿那亚2022砂之盒沉浸艺术季
12 Recurrent Neural Network RNN2 of Deep Learning
How to translate financial annual report, why choose a professional translation company?