当前位置:网站首页>数据分析入门 | kaggle泰坦尼克任务(四)—>数据清洗及特征处理
数据分析入门 | kaggle泰坦尼克任务(四)—>数据清洗及特征处理
2022-04-23 06:20:00 【猿知】

一、数据清洗及特征处理
(1)数据清洗简述
我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能继续做后面的分析或建模,所以拿到数据的第一步是进行数据清洗,本章我们将学习缺失值、重复值、字符串和数据转换等操作,将数据清洗成可以分析或建模的样子。
(2)观察缺失值
①方法一:
df.info()
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
②方法二:
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
(3)缺失值处理
df[df['Age']==None]=0
df.head(3)
df[df['Age'].isnull()] = 0 # 还好
df.head(3)
df[df['Age'] == np.nan] = 0
df.head()
df.dropna().head(3)
df.fillna({
'Age':0}).head(3) #补Age
df.fillna(0) #全表补0
df.loc[df['Age'].isnull(),'Age'] = 0
#在Age为空的那一列补0
【思考】检索空缺值用np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
【回答】数值列读取数据后,空缺值的数据类型为float64所以用None一般索引不到,比较的时候最好用np.nan
(4)重复值的处理
df[df.duplicated()] #会将重复的数值输出
df = df.drop_duplicates() #删除重复行
df.head()
(5)特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
(6)对年龄进行分箱(离散化)处理
#将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'], 5,labels = [1,2,3,4,5])
df.head()
#将连续变量Age划分为(0,5] (5,15] (15,30] (30,50] (50,80]五个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'],[0,5,15,30,50,80],labels = [1,2,3,4,5])
df.head(3)
#将连续变量Age按10% 30% 50 70% 90%五个年龄段,并用分类变量12345表示
df['AgeBand'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9],labels = [1,2,3,4,5])
df.head()
(7)对文本变量进行转换
#查看类别文本变量名及种类
#方法一: value_counts
df['Sex'].value_counts()
-->output:
male 453
female 261
0 1
Name: Sex, dtype: int64
#方法二: unique
df['Sex'].unique()
-->output:
array(['male', 'female', 0], dtype=object)
#将类别文本转换为12345
#方法一: replace
df['Sex_num'] = df['Sex'].replace(['male','female'],[1,2]) #不加inplace返回副本
df.head()
#方法二: map
df['Sex_num'] = df['Sex'].map({
'male': 1, 'female': 2})
df.head()
#方法三: 使用sklearn.preprocessing的LabelEncoder
from sklearn.preprocessing import LabelEncoder
for feat in ['Cabin', 'Ticket']:
lbl = LabelEncoder()
label_dict = dict(zip(df[feat].unique(), range(df[feat].nunique())))
df[feat + "_labelEncode"] = df[feat].map(label_dict)
df[feat + "_labelEncode"] = lbl.fit_transform(df[feat].astype(str))
df.head()
from sklearn.preprocessing import LabelEncoder
df['Cabin'] = LabelEncoder().fit_transform(df['Cabin'])
df.head()
#将类别文本转换为one-hot编码
#方法一: OneHotEncoder
for feat in ["Age", "Embarked"]:
# x = pd.get_dummies(df["Age"] // 6)
# x = pd.get_dummies(pd.cut(df['Age'],5))
x = pd.get_dummies(df[feat], prefix=feat) #第一个参数是要处理的数据,第二个是改名后的前缀
df = pd.concat([df, x], axis=1) #按列加到原来数据后面
#df[feat] = pd.get_dummies(df[feat], prefix=feat)
df.head()
(8)从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
df['Title'] = df.Name.str.extract('([A-Za-z]+)\.', expand=False)
df.head()
数据分析入门 | kaggle泰坦尼克任务 系列持续更新,欢迎
点赞收藏+关注
上一篇:数据分析入门 | kaggle泰坦尼克任务(三)—>探索数据分析
下一篇:
本人水平有限,文章中不足之处欢迎下方评论区批评指正~如果感觉对你有帮助,点个赞 支持一下吧 ~
不定期分享 有趣、有料、有营养内容,欢迎 订阅关注 我的博客 ,期待在这与你相遇 ~
版权声明
本文为[猿知]所创,转载请带上原文链接,感谢
https://blog.csdn.net/Magic_Zsir/article/details/123561508
边栏推荐
- el-table 横向滚动条固定在可视窗口底部
- 技术小白的第一篇(表达自己)
- vim+ctags+cscpope开发环境搭建指南
- Draw margin curve in arcface
- How to improve the service efficiency of the hotel without blind spots and long endurance | public and Private Integrated walkie talkie?
- 数论之拓展欧几里得
- ESP32学习-GPIO的使用与配置
- PyTorch 14. Module class
- 学习笔记7-深度神经网络优化
- hql求一个范围内最大值
猜你喜欢

自定义classloader并实现热部署-使用loadClass

PyTorch 10. Learning rate
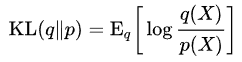
直观理解熵

学习笔记5-梯度爆炸和梯度消失(K折交叉验证)

电力行业巡检对讲通信系统

ES6之箭头函数细谈

Emergency air space integrated communication system scheme of Guangxi Power Grid

Solution of emergency communication system for major security incidents

基于可视化结构的身份证号码校验系统-树莓派实现
Draw margin curve in arcface
随机推荐
ESP32学习-向工程项目添加文件夹
南方投资大厦SDC智能通信巡更管理系统
javscript获取文件真实后缀名
地铁无线对讲系统
go语言:在函数间传递切片
Object.create()原理,Object.create()规范,手写Object.create(),Object.create()用法
jvm知识点汇总-持续更新
LATEX使用
Meishe helps Baidu "Duka editing" to make knowledge creation easier
基于可视化结构的身份证号码校验系统-树莓派实现
小程序换行符\n失效问题解决-日常踩坑
防汛救灾应急通信系统
连接orcale
什么是闭包?
可视化常见问题解决方案(七)画图刻度设置解决方案
(一)OpenPAI jupyter jupyterhub jupyterlab 方案比较
PyTorch 20. Pytorch tips (continuously updated)
可视化常见绘图(三)面积图
PyTorch 13. Nested functions and closures (dog head)
启动mqbroker.cmd失败解决方法