当前位置:网站首页>【爬虫】scrapy创建运行爬虫、解析页面(嵌套url)、自定义中间件(设置UserAgent和代理IP)、自定义管道(保存到mysql)
【爬虫】scrapy创建运行爬虫、解析页面(嵌套url)、自定义中间件(设置UserAgent和代理IP)、自定义管道(保存到mysql)
2022-08-10 23:50:00 【冰冷的希望】
1.说明
scrapy是一个快速、高层次的屏幕抓取和web抓取框架,我们只需要在乎怎么提取数据和保存数据,其他的都交给scrapy完成,所以比较快速高效,而且功能强大,很多东西都是可以自定义配置的。
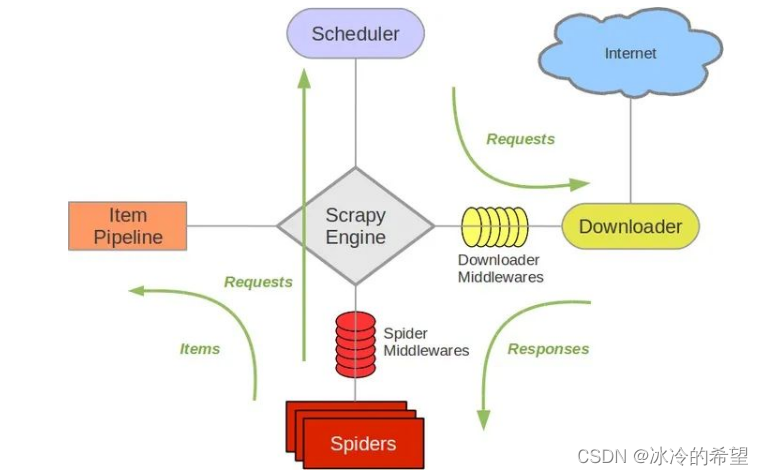
从图中可以看出scrapy的主要由引擎、管道、下载器、调度器、爬虫组成,至于它们的作用简单总结如下
| 组件 | 英文 | 作用 |
|---|---|---|
| 引擎 | ScrapyEngine | 负责整体工作流 |
| 调度器 | Schedule | 安排拿到的URL按某种先后规则交给下载器 |
| 下载器 | Downloader | 拿到URL之后从网络下载并交给爬虫 |
| 爬虫 | Spider | 把下载器下载好的资源进行处理,比如说数据提取,如果有新的URL会交给调度器,如果没有,就把提取好的数据交给管道 |
| 管道 | Pipeline | 对数据进行持久化存储,比如说保持到数据库 |
官方文档:https://docs.scrapy.org/en/latest/index.html
2.创建项目和爬虫
使用pip安装好scrapy库之后,可以终端或cmd使用scrapy命令创建项目,之后再创建一个爬虫(spider)
scrapy startproject 项目名
cd 项目名
scrapy genspider 爬虫名 域名
举个栗子:
scrapy startproject douban_movie
cd douban_movie
scrapy genspider douban_top250 movie.douban.com
项目结构如下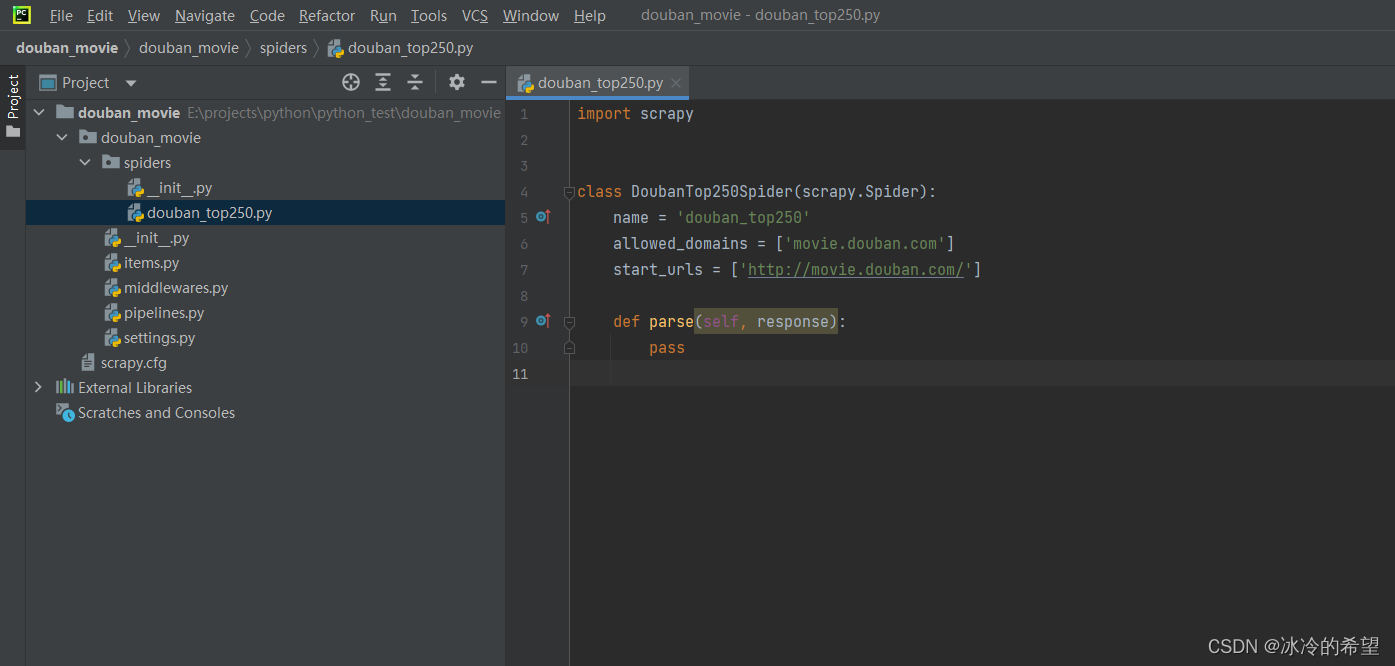
3.运行爬虫
如果你把解析页面什么的都写好了可以使用下面的命令启动爬虫
scrapy crawl 爬虫名 选项
举个栗子
# 默认管道支持json、 jsonlines、 jl、 csv、 xml、 marshal、 pickle文件格式
scrapy crawl douban_top250 -o top250.json # -o是追加模式,-O是覆盖模式
scrapy crawl douban_top250 -o top250.csv
scrapy crawl douban_top250 -O top250.csv --nolog # 运行时不打印日志
4.数据结构(Item)
我们需要定义数据结构的字段,即你最终清洗完数据得到的结构化数据项,定义一个Item类继承scrapy.Item即可
items.py
import scrapy
class DoubanMovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
rating_num = scrapy.Field()
quote = scrapy.Field()
runtime = scrapy.Field()
summary = scrapy.Field()
5.解析页面(Spider)
整个爬虫最主要的工作,就是下载器获取到数据的之后交给爬虫处理,爬虫这边需要提取自己所需要的数据,然后交给Item。如果你需要再访问新的链接,只需要生成一个新的Request交给调度器,Request对象有一个callback回调函数用于解析新的页面,当然也可以通过cb_kwargs参数把当前解析得到的数据传给回调函数,解析函数最后一定是yield一个Item
douban_top250.py
import scrapy
from scrapy import Request, Selector
from douban_movie.items import DoubanMovieItem
class DoubanTop250Spider(scrapy.Spider):
name = 'douban_top250'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/']
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
"Cookie": '...',
}
def start_requests(self):
for page in range(1):
# 如果通过这种方式设置cookie,settings.py一定要设置COOKIES_ENABLED = False
yield Request(url="https://movie.douban.com/top250?start={}&filter=".format(page * 25),
headers=DoubanTop250Spider.headers)
def parse(self, response, **kwargs):
# print("headers['User-Agent']: ", response.request.headers['User-Agent']) # 查看当前User-Agent
selector = Selector(response)
lis = selector.xpath('//ol[@class="grid_view"]/li')
# 实例化一个Item用于组织数据
movie_item = DoubanMovieItem()
for li in lis:
detail_url = li.xpath('./div[@class="item"]/div[@class="info"]/div[@class="hd"]/a/@href').extract_first()
movie_item["title"] = li.xpath(
'./div/div[@class="info"]/div[@class="hd"]/a/span[@class="title"]/text()').extract_first()
movie_item["rating_num"] = li.xpath(
'./div/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract_first()
movie_item["quote"] = li.xpath(
'./div/div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span/text()').extract_first()
# yield movie_item
# 如果有新的页面需要爬取可以再yield一个Request并指定回调函数
yield Request(url=detail_url, callback=self.parse_detail, cb_kwargs={
"movie_item": movie_item},
headers=DoubanTop250Spider.headers)
def parse_detail(self, response, **kwargs):
selector = Selector(response)
movie_item = kwargs.get("movie_item")
movie_item["runtime"] = selector.xpath('//div[@id="info"]/span[@property="v:runtime"]/@content').extract_first()
movie_item["summary"] = selector.xpath(
'//span[@property="v:summary"]/text()').extract_first().strip()
# 最后要生成一个Item
yield movie_item
6.中间件(middlewares)
scrapy有很多中间件,我们能看得到的是在middlewares.py中定义的蜘蛛中间件DoubanMovieSpiderMiddleware和下载中间件DoubanMovieDownloaderMiddleware,这两个类里面定义的方法类型。只要你想,你也可以随意定义中间件,例如我们定义一个设置随机UserAgent的中间件
middlewares.py
import random
from fake_useragent import UserAgent
from scrapy import signals
from itemadapter import is_item, ItemAdapter
# 自定义UserAgent中间件
class RandomUserAgentMiddleware:
def __init__(self):
self.agent = UserAgent()
@classmethod
def from_crawler(cls, crawler):
return cls()
def process_request(self, request, spider):
request.headers['User-Agent'] = self.agent.random
# IP代理中间件
class ProxyMiddleware(object):
def process_request(self, request, spider):
# 代理IP,可以维护自己的IP代理池然后随机取出IP
proxies = ["https://47.115.4.9:3128", ...]
request.meta["proxy"] = random.choice(proxies)
def process_response(self, request, response, spider):
if response.status != '200':
# 不过滤,即重新进入调度器队列
request.dont_filter = True
return request
# 蜘蛛中间件
class DoubanMovieSpiderMiddleware:
...
# 下载中间件
class DoubanMovieDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
...
# 发起请求前执行
def process_request(self, request, spider):
return None
# 请求之后执行
def process_response(self, request, response, spider):
return response
# 抛异常时执行
def process_exception(self, request, exception, spider):
pass
# 爬虫开启之后执行
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
中间件只是一个普通类,只是实现了一些特殊函数(钩子函数),如果想要在scrapy中生效,需要在设置文件指定
settings.py
DOWNLOADER_MIDDLEWARES = {
# 中间件:权重, 权重值越小优先级越高
# 'douban_movie.middlewares.DoubanMovieDownloaderMiddleware': 543,
'douban_movie.middlewares.RandomUserAgentMiddleware': 500,
'douban_movie.middlewares.ProxyMiddleware': 510,
}
7.管道(pipeline)
如果你要把管道数据保存成son、 jsonlines、 jl、 csv、 xml、 marshal、 pickle文件格式,可用使用启动爬虫时使用-o参数指定即可,但如果你需要保存其他文件格式,比如excel或者保持到数据库,那就需要在pipeline中写代码了
pipelines.py
class DoubanMoviePipeline:
def open_spider(self, spider):
pass
def close_spider(self, spider):
pass
def process_item(self, item, spider):
return item
比如说我们要把它保存到mysql数据库
import pymysql
from itemadapter import ItemAdapter
class DoubanMoviePipeline:
def __init__(self):
self.conn = pymysql.connect(host="localhost", port=3306, user="", password="", database="", charset="utf8")
self.cursor = self.conn.cursor()
self.temp_data = list()
# 打开爬虫时执行
def open_spider(self, spider):
pass
# 关闭爬虫时执行
def close_spider(self, spider):
self._save_data()
self.cursor.close()
self.conn.close()
# 每次获取到Item对象时执行
def process_item(self, item, spider):
title = item.get("title", "")
rating_num = item.get("rating_num", "")
quote = item.get("quote", "")
runtime = item.get("runtime", "")
summary = item.get("summary", "")
self.temp_data.append((title, rating_num, quote, runtime, summary))
if len(self.temp_data) == 100:
self._save_data()
return item
def _save_data(self):
if self.temp_data:
self.conn.ping(reconnect=True)
self.cursor.executemany(
'insert into douban_movies(title,rating_num,quote,runtime,summary) values(%s,%s,%s,%s,%s)',
self.temp_data)
self.conn.commit()
self.temp_data.clear()
最后要在设置文件中启用pipeline
settings.py
ITEM_PIPELINES = {
'douban_movie.pipelines.DoubanMoviePipeline': 300,
}
8.常用设置项
settings.py
ROBOTSTXT_OBEY = True # 是否遵循robot协议
DOWNLOAD_DELAY = 1 # 启用下载延迟
AUTOTHROTTLE_ENABLED = True # 是否自动限流,默认False
COOKIES_ENABLED = False # 是否禁用cookie
# 下载中间件
DOWNLOADER_MIDDLEWARES = {
# 'douban_movie.middlewares.DoubanMovieDownloaderMiddleware': 543,
'douban_movie.middlewares.RandomUserAgentMiddleware': 543,
}
# 启用管道
ITEM_PIPELINES = {
'douban_movie.pipelines.DoubanMoviePipeline': 300,
}
边栏推荐
- “蔚来杯“2022牛客暑期多校训练营4 ADHK题解
- YOLOv5的Tricks | 【Trick13】YOLOv5的detect.py脚本的解析与简化
- YOLOv5的Tricks | 【Trick12】YOLOv5使用的数据增强方法汇总
- 如何快速把握行业机会,更高效地推陈出新,是一个重要的命题
- 盘点美军的无人机家底
- [Excel knowledge and skills] Convert numeric format numbers to text format
- UOJ#749-[UNR #6]稳健型选手【贪心,分治,主席树】
- SAS data processing technology (1)
- [C] the C language program design, dynamic address book (order)
- YOLOv5的Tricks | 【Trick11】在线模型训练可视化工具wandb(Weights & Biases)
猜你喜欢
13. 内容协商
线上突然查询变慢怎么核查
Pagoda Test-Building PHP Online Mock Exam System

【C语言】初识指针
2. Dependency management and automatic configuration
Qt入门(六)——抽奖系统的实现

PMP每日一练 | 考试不迷路-8.10(包含敏捷+多选)
SAS data processing technology (1)
Is there a way out in the testing industry if it is purely business testing?

App regression testing, what are the efficient testing methods?
随机推荐
12. Handling JSON
进程和线程
盘点美军的无人机家底
YOLOv5的Tricks | 【Trick12】YOLOv5使用的数据增强方法汇总
鲲鹏编译调试及原生开发工具基础知识
Why do programming languages have the concept of variable types?
开启新征程——枫叶先生第一篇博客
Excel English automatic translation into Chinese tutorial
Part of the reserve bank is out of date
Based on the SSM to reach the phone sales mall system
Multilingual Translation - Multilingual Translation Software Free
Mysql.慢Sql
Timers, synchronous and asynchronous APIs, file system modules, file streams
Dump file generation, content, and analysis
SAS数据处理技术(一)
SQL注入基础
How to recover deleted files from the recycle bin, two methods of recovering files from the recycle bin
学习Apache ShardingSphere解析器源码(一)
10. Notes on receiving parameters
What is the ASIO4ALL