当前位置:网站首页>MySQL集群模式与应用场景
MySQL集群模式与应用场景
2022-04-23 15:37:00 【dengk2013】
省流助手:
单库模式:一个mysql数据库承载所有相关数据。
读写分离集群模式:在原有的基础上增加中间层,与后端数据集构成读写分离的集群。整体基础结构:原有的主库派生出字库1,字库2,
利用mysql原有的主从同步机制(即为:binlog日志同步),将主库的数据变化在从库中复现,保证数据同步。主库一般用于写入处理,
从库负责读取。细节:如果直接面对主库进行操作无法完成读写分离,需要在前端分配分片中间件(阿里mycat,京东ShardingSphere),
该中间件通过curd请求,来决定由哪个库处理。MHA中间件实现高可用(即:主服务器坏了,MHA中间件可以将某个从表提升为主服务器)。
所有节点数据均保持同步。适用于读多写少,单表不过千万的互联网应用。
分库分表(分片)集群模式:一个mysql数据库撑不住的情况下。将数据库的数据分到不同的节点数据库(即:节点数据库的数据合起来为完整的数据体)。
需要用到中间件进行路由。(对sql进行解析,将请求发到对应的数据库,分发请求的过程叫路由)。不具备高可用性。
为什么大厂做垂直分表?
一张表的字段太多需要做垂直分表。
什么是水平分表?
以行为单位对数据进行拆分(范围法,hash法)。特点:所有的表结构完全相同。用于解决数据量大的存储问题。
什么是垂直分表?
将表按列拆分成2张以上的小表,通过主外键关联获取数据。
为什么要这么做?
需要了解mysql的InnoDB处理引擎。
行数据称为:row
管理数据基本单位称为页:page;每一页的默认大小:16k
保存页的单位称为区:Extent。
关系:区由连续页组成,页由连续行组成。1024/16=64(即:一个1M的区有64个页)
InnoDB1.0后新特性,压缩页。
压缩页:对数据底层进行压缩,使实际大小小于逻辑大小。
在跨页检索数据的过程中,压缩和解压缩的效率低。在表设计时,尽可能在页内多存储行数据,减少跨页检索,增加页内检索。
分析:
1行数据为1K,1页16K,即1页16条数据,1亿的数据需要625万页
垂直分页后,1行数据为64字节(1K=1024字节),即1页256条数据,1亿的数据需要40万页。分页后的数据根据id等关系进行快速提取。
通过将重要字段单独剥离成小表,让每页容纳更多行数据,页减少后,缩小数据扫描范围,达到提高执行效率的目的。
垂直分表条件:
1.单表数据达千万
2.字段超20个,且包含vachar,CLOB,BLOB等字段
字段放大小表的依据:
小表:数据查询、排序时需要的字段;高频访问的小字段
大表:低频访问字段;大字段
自增主键在分布式环境下不适用。
由于自增主键必须连续,所以按范围法进行分片,ID的数量已固定。无法进行动态扩展。会产生“尾部热点”效应。
尾部热点:即按范围法进行分片后,前面的分片已储存数据,最后一个分片的压力很大。
Hash分片的效率更高。
使用UUID替代自增主键吗?不可以、
涉及数据库底层机制:
1.uuid,唯一无序。无序导致索引重排。主键有序的情况下,B+树只需要在原有的数据后面追加即可。
怎么解决?分布式且有序的主键生成算法?
雪花算法(SnowFlake),推特公司。
结构:符号位(1bit)+时间戳(41bit)+机器ID(10bit)+序列(12bit)
使用方法:直接调用JAR包
雪花算法需要注意时间回拨带来的影响。可能出现id重复的可能
阿里canal
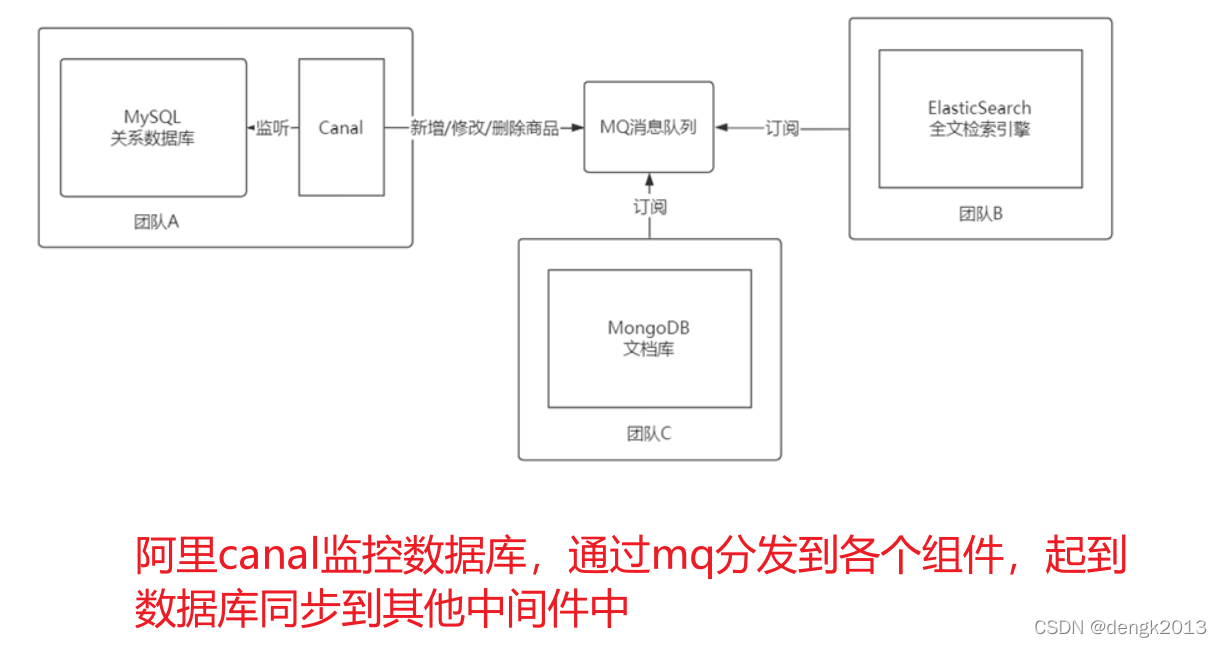

版权声明
本文为[dengk2013]所创,转载请带上原文链接,感谢
https://blog.csdn.net/u012222011/article/details/124336044
边栏推荐
- 字节面试 transformer相关问题 整理复盘
- JVM-第2章-类加载子系统(Class Loader Subsystem)
- 一刷314-剑指 Offer 09. 用两个栈实现队列(e)
- 码住收藏▏软件测试报告模板范文来了
- How to test mobile app?
- Rsync + inotify remote synchronization
- Differential privacy (background)
- php类与对象
- The wechat applet optimizes the native request through the promise of ES6
- Hj31 word inversion
猜你喜欢
Krpano panorama vtour folder and tour
Mumu, go all the way
Multitimer V2 reconstruction version | an infinitely scalable software timer

现在做自媒体能赚钱吗?看完这篇文章你就明白了
使用 Bitnami PostgreSQL Docker 镜像快速设置流复制集群

深度学习——超参数设置
CVPR 2022 优质论文分享
Wechat applet customer service access to send and receive messages
机器学习——逻辑回归

Byte interview programming question: the minimum number of K
随机推荐
fatal error: torch/extension. h: No such file or directory
[backtrader source code analysis 18] Yahoo Py code comments and analysis (boring, interested in the code, you can refer to)
PHP 的运算符
多生成树MSTP的配置
pywintypes.com_error: (-2147221020, ‘无效的语法‘, None, None)
What if the package cannot be found
JSON date time date format
控制结构(二)
Squid agent
时序模型:长短期记忆网络(LSTM)
山寨版归并【上】
Connectez PHP à MySQL via aodbc
What are the mobile app software testing tools? Sharing of third-party software evaluation
时序模型:门控循环单元网络(GRU)
Control structure (I)
Differential privacy (background)
Openstack theoretical knowledge
shell脚本中的DATE日期计算
电脑怎么重装系统后显示器没有信号了
Rsync + inotify remote synchronization