当前位置:网站首页>字节面试 transformer相关问题 整理复盘
字节面试 transformer相关问题 整理复盘
2022-04-23 15:23:00 【moletop】
transformer
动机:
RNN特点:给你一个序列,计算是从左往右一步一步往前的。对句子来说,就是一个词一个词的看,对第t个词会计算一个ht,也叫做他的隐藏状态,是由前一个词的ht-1和 当前第t个词本身决定的。这样就可以把之前学习到的历史信息通过ht-1放到当下,然后和当前的词做一些计算然后得到输出.
问题:因为是时序传递,导致1. 难以并行2.早期的学习到的信息会丢掉,如果不想丢掉,那可能就要做一个很大的ht,但是如多做一个很大的ht,每一个时间都要保存下来,导致内存的开销是比较大的。
——> 纯用attention机制就可以使并行度大大提高
- 考虑使用CNN替换循环神经网络的话:CNN对比较长的序列难以建模,卷积每次计算都是看一个小窗口,以像素为例,如果两个像素隔的比较远,那么就需要很多层卷积,才能把这两个隔的远的像素融合起来。而而对于transformer来说,我一次就能看见所有的像素,相对来说就没有这个问题。但是卷积有一个好处就是可以做多输出通道。每一个通道就可以认为他可以去识别不一样的模式。所以muti-headed attention被提出来,用来模拟卷积神经网络多输出通道的效果,也可以说是多尺度的概念,让模型从多个不同的尺度空间来学习。
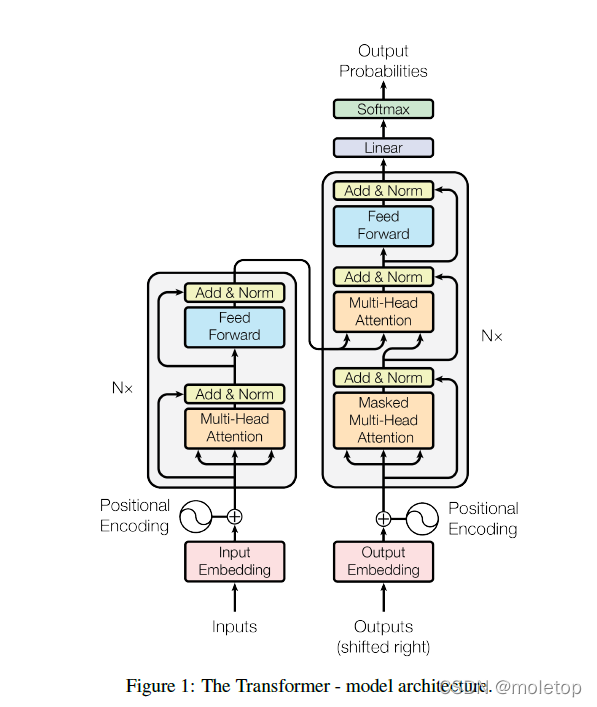
结构
encoder:
左边部分,N等于6的完全一样的layer每个layer里有两个sub-layers。第一个sub-layer就是multihead self attention,第二个其实就是个MLP。然后每一个子层用了一个残差连接,最后用了一个LayerNorm。所以每一个子层的输出就是LayerNorm(x + Sublayer (x))。
细节:因为残差的输入和输出的大小要一样,所以为了简单起见,每一个输出的维度设置未512,也就是每一个词,不管在哪一层,都做成了512的长度表示。这个和CNN或者MLP是不一样的,这两者要么是维度减小或者是空间的维度减小,通道的维度上拉。所以这也使得模型相对会更简单,调参的话只要调这个512和前面这个N = 6就好了。
位置编码:没有采用RNN的transformer好像没有捕捉序列信息的功能,它分不清到底是我咬了狗还是狗咬了我。怎么办呢,可以在输入词向量的时候结合上单词的位置信息,这样到就可以学习词序信息了
一种做法就是分配一个0到1之间的数值给每个时间步,其中,0表示第一个词,1表示最后一个词。这种方法虽然简单,但会带来很多问题。其中一个就是你无法知道在一个特定区间范围内到底存在多少个单词。换句话说,不同句子之间的时间步差值没有任何的意义。
另一种做法就是线性分配一个数值给每个时间步。也就是,1分配给第一个词,2分配给第二个词,以此类推。这种方法带来的问题是,不仅这些数值会变得非常大,而且模型也会遇到一些比训练中的所有句子都要长的句子。此外,数据集中不一定在所有数值上都会包含相对应长度的句子,也就是模型很有可能没有看到过任何一个这样的长度的样本句子,这会严重影响模型的泛化能力。
实际是用周期不一样的sin和cos计算出来的
decoder:
比编码器多了第三个子层(也是一个多头注意力机制,也用了残差,也用layernorm)叫masked muti-headed attention(为下一层提供Q)。解码器用了一个自回归,当前层的一些输入时上面一些时刻的输入,这就意味着你在做预测的时候,当然不能看到之后的那些时刻的输出。但是做attention的时候,是可以看见完整的输入的,为了避免这个发生,使用带mask的注意力机制。这就可以保证训练和预测的时候行为是一致的。
两种mask:
1.padding mask:我们输入的序列长度是不一定相同的.对于长度超过我们期望的长度的序列,我们就只保留期望长度内的内容。对于长度没有达到期望的长度的序列,我们就用0来填充它,填充的位置是没有任何意义,我们不希望attention机制给它分配任何注意力,所以我们给填充过的位置加上负无穷,因为在计算注意力的时候我们会用到softmax函数,加上过负无穷的位置会被softmax处理变成0)。
2.预测用的mask:不能看到后面的输出。
LayerNorm
先看batch Normlization

注意:最后要加上缩放因子和平移因子(参数是自己学习的)。这是为了保证模型的表达能力不因为规范化而下降。因为上层神经元可能很努力地在学习,但不论其如何变化,其输出的结果在交给下层神经元进行处理之前,将被粗暴地重新调整到这一固定的范围。但是并不是每一个样本都适合归一的,有些特殊的样本归一化之后。失去了他的学习价值。另一方面的重要意义在于保证获得非线性的表达能力。规范化会将几乎所有数据映射到激活函数的非饱和区(线性区),仅利用到了线性变化能力。仅利用到了线性变化能力,从而降低了神经网络的表达能力。而进行再变换,则可以将数据从线性区变换到非线性区,恢复模型的表达能力。
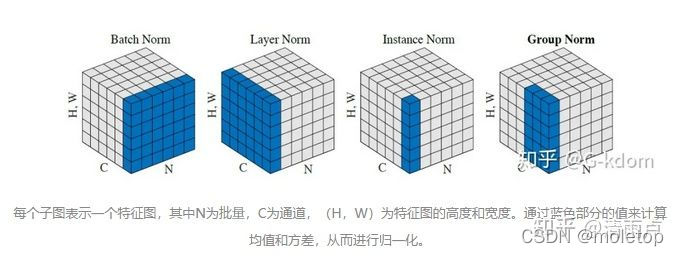
为什么用layerNorm效果更好:
Normlization 目的:白化,使之成为独立同分布
batch Normlization是不同样本的同一通道做归一,layer Normlization是同一样本的不同通道做归一。对于一个特征图来说,两者只是切这一刀的方向不一样,一个横向,一个纵向。RNN等文本网络不适合用BN的原因:Normalize的对象(position)来自不同分布。CNN中使用BN,对一个batch内的每个channel做标准化。多个训练图像的同一个channel,大概率来自相似的分布。(例如树的图,起始的3个channel是3个颜色通道,都会有相似的树形状和颜色深度)。RNN中使用BN,对一个batch内的每个position做标准化。多个sequence的同一个position,很难说来自相似的分布。(例如都是影评,但可以使用各种句式,同一个位置出现的词很难服从相似分布)所以RNN中BN很难学到合适的μ和σ。但是如果你自身单个样本内normlization的话,就不存在这个问题了。
其他的Normlization:Weight Normalization(参数规范化) Cosine Normalization (余弦规范化)
参考:https://zhuanlan.zhihu.com/p/33173246
复杂度:
此处是粘图,参考链接:https://zhuanlan.zhihu.com/p/264749298

版权声明
本文为[moletop]所创,转载请带上原文链接,感谢
https://blog.csdn.net/Leiroy/article/details/124093213
边栏推荐
- 22年了你还不知道文件包含漏洞?
- 填充每个节点的下一个右侧节点指针 II [经典层次遍历 | 视为链表 ]
- Async void caused the program to crash
- Detailed explanation of kubernetes (IX) -- actual combat of creating pod with resource allocation list
- The win10 taskbar notification area icon is missing
- regular expression
- Mysql database explanation (VII)
- Explanation of redis database (III) redis data type
- Mysql连接查询详解
- JSON date time date format
猜你喜欢
Sword finger offer (1) -- for Huawei

Sword finger offer (2) -- for Huawei

Functions (Part I)
T2 icloud calendar cannot be synchronized
Wechat applet customer service access to send and receive messages

Advanced version of array simulation queue - ring queue (real queuing)
Share 20 tips for ES6 that should not be missed
Krpano panorama vtour folder and tour

TLS / SSL protocol details (30) RSA, DHE, ecdhe and ecdh processes and differences in SSL
UML learning_ Day2
随机推荐
Basic operation of sequential stack
让阿里P8都为之着迷的分布式核心原理解析到底讲了啥?看完我惊了
win10 任务栏通知区图标不见了
What exactly does the distributed core principle analysis that fascinates Alibaba P8? I was surprised after reading it
8.5 concise implementation of cyclic neural network
分布式事务Seata介绍
Alexnet model
How does eolink help telecommuting
Detailed explanation of C language knowledge points -- first understanding of C language [1] - vs2022 debugging skills and code practice [1]
MySQL Basics
Llvm - generate if else and pH
Collation of errors encountered in the use of redis shake
Lotus DB design and Implementation - 1 Basic Concepts
如果conda找不到想要安装的库怎么办PackagesNotFoundError: The following packages are not available from current
Llvm - generate for loop
Ffmpeg installation error: NASM / yasm not found or too old Use --disable-x86asm for a clipped build
JSON date time date format
Mysql database explanation (8)
重定向和请求转发详解
Flink DataStream 类型系统 TypeInformation