当前位置:网站首页>巧用自定义函数,文本控件秒变高速缓存
巧用自定义函数,文本控件秒变高速缓存
2022-08-11 10:51:00 【InfoQ】

前言
- 表现层(UIL):展现给用户的界面,即用户在使用系统时他的所见所得。
- 业务逻辑层(BLL):针对具体问题的操作,也可以说是对数据层的操作,对数据业务逻辑处理。
- 数据访问层(DAL):针对数据的增添、删除、修改、查找等。
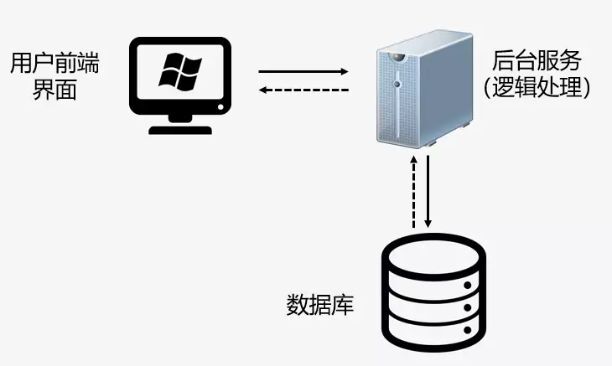
- 一定程度上降低了系统性能。例如:明道云对数据的批量复杂处理主要依靠大量的工作流(包含子流程),当复杂的工作流嵌套较多的时候,维护起来会有难度。
- 前后端关联处理,牵一发而动全身。例如:为了在前端大屏上显示全面的数据可视化效果,要组合运用一系列字段、数据关联、工作流才可以实现。
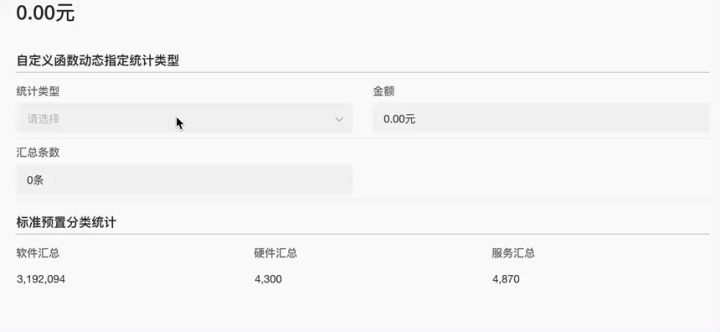
自定义数据结构,把文本控件变成高速缓存
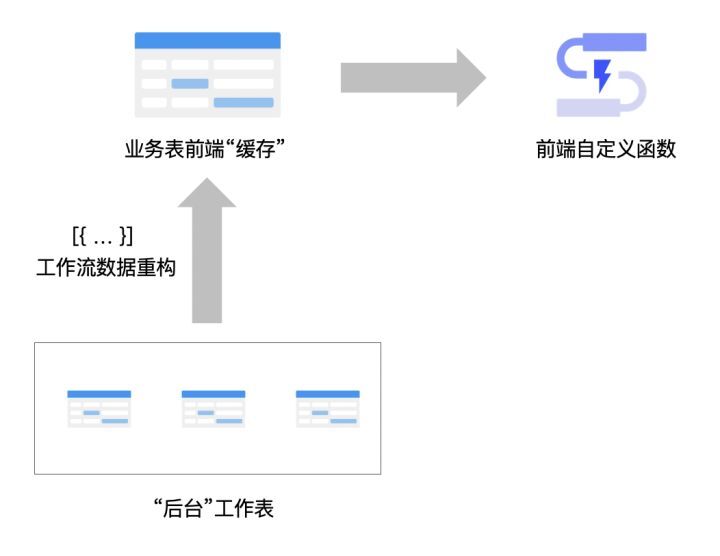
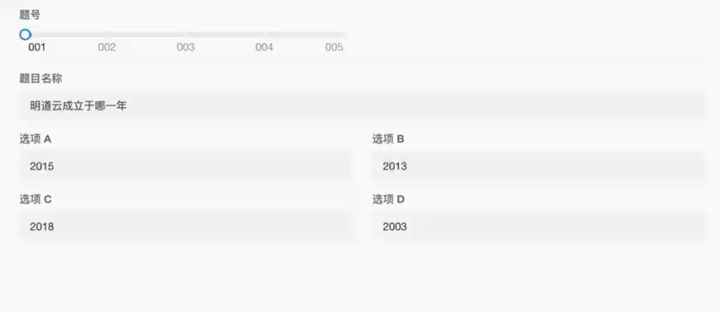
示例效果
- 在查询表中建立一个单条的人员岗位关联控件;
- 为这个关联控件设置一个查询他表的默认值,条件为当前输入的工号
- 通过他表字段或者文本控件默认值把该关联的相关字段引入到当前记录。
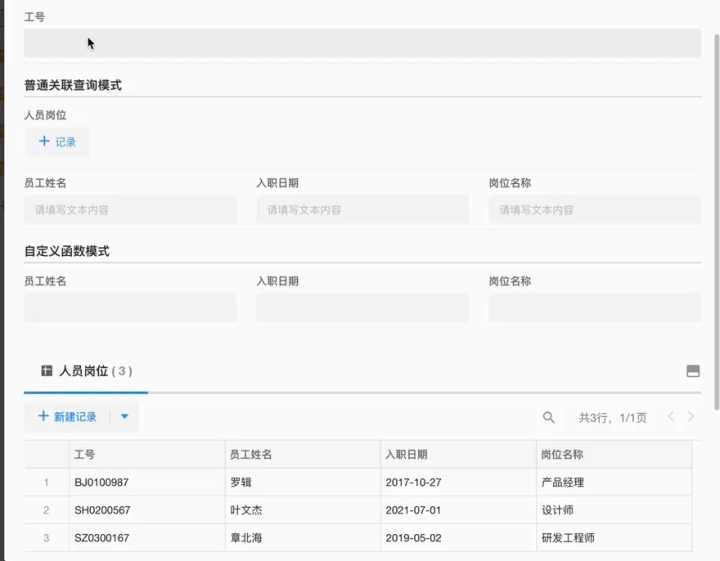
步骤讲解


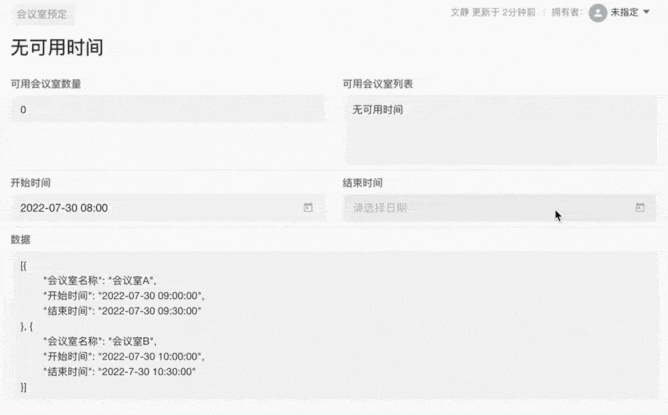
更多应用场景

总结
边栏推荐
- VC6.0 +WDK 开发驱动的环境配置
- [UE] 入坑
- 6.1 总线的概念和结构形态
- 7 天找个 Go 工作,Gopher 要学的条件语句,循环语句 ,第3篇
- Revelations!The former Huawei microservice expert wrote 500 pages of practical notes on the landing architecture, which has been open sourced
- 运动健康服务场景事件订阅,让应用推送“更懂用户”
- 力扣打卡----打家劫舍
- 为什么有些人不喜欢出身底层的人?
- 【luogu CF1286E】Fedya the Potter Strikes Back(字符串)(KMP)(势能分析)(线段树)
- openresty概述及Lua语言的嵌入
猜你喜欢

The ceiling-level microservice boss summed up this 451-page note to tell you that microservices should be learned this way
分析 Flink 任务如何超过 YARN 容器内存限制
从零开始配置 vim(12)——主题配置
独家采访 | 智能源于自发产生而非计划:进化论拥趸,前OpenAI研究经理、UBC大学副教授Jeff Clune
阿里二面:JVM调优你会吗?
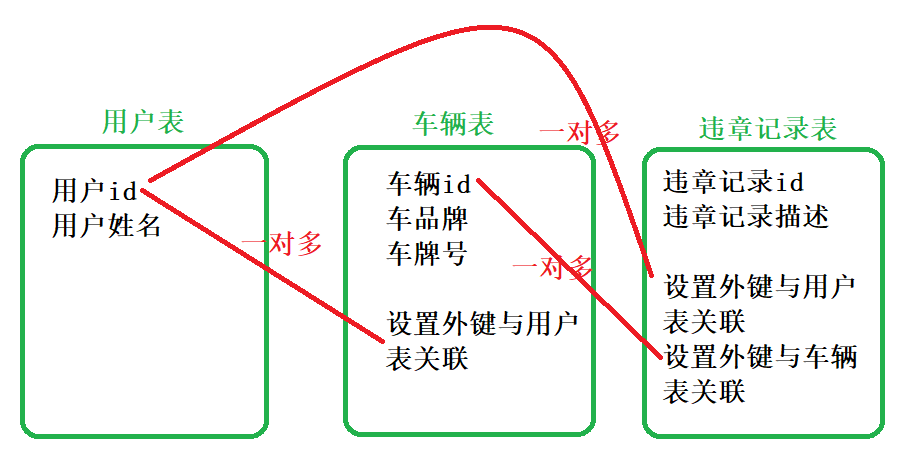
【Mysql系列】03_系统设计
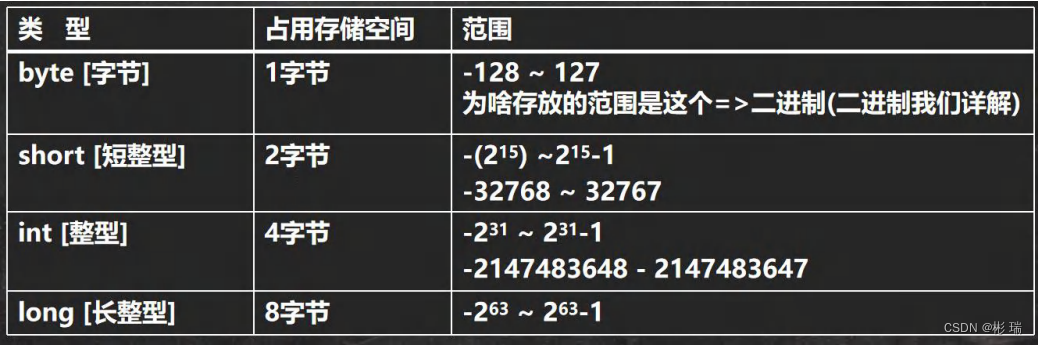
二、第二章变量
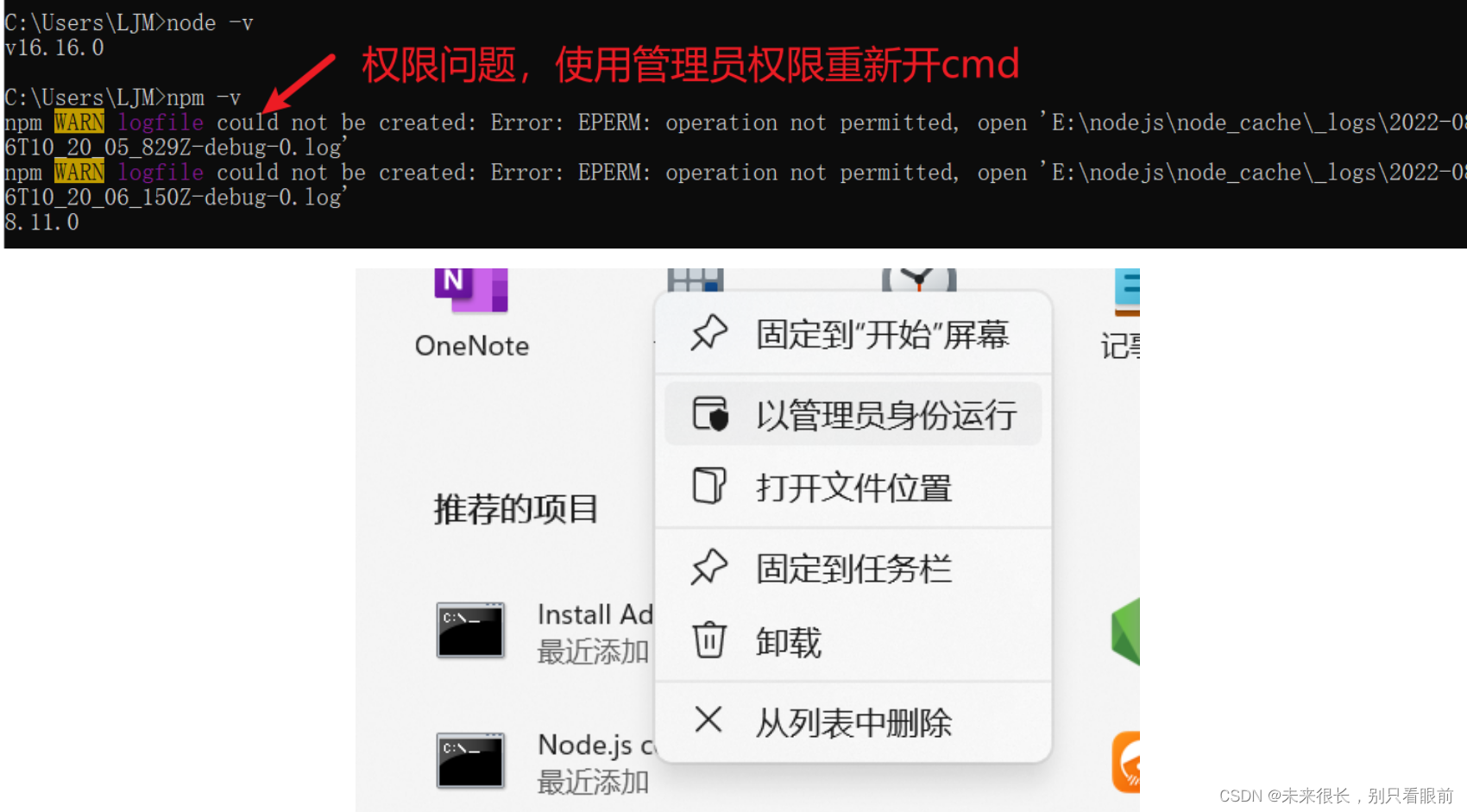
Install nodejs

4. 继承
【Mask2Former】 解决代码中一些问题
随机推荐
Database indexes and their underlying data structures
【luogu CF1286E】Fedya the Potter Strikes Back(字符串)(KMP)(势能分析)(线段树)
Convolutional Neural Network Gradient Vanishing, The Concept of Gradient in Neural Networks
SDS观察站
【luogu CF1427F】Boring Card Game(贪心)(性质)
1.TCP/IP基础知识
Latex引用图片 发现 显示的图片标号不对
Simple implementation of a high-performance clone of Redis using .NET (seven-end)
假设检验:正态性检验的那些bug——为什么对同一数据,normaltest和ktest会得到完全相反的结果?
你必须懂的一些MySQL索引技巧
2. 类与对象——封装
日志使用注意事项和建议
Cholesterol-PEG-FITC, Fluorescein-PEG-CLS, Cholesterol-PEG-Fluorescein water-soluble
Use Function Compute to package and download OSS files [Encounter Pit Collection]
How to explain to my girlfriend what is cache penetration, cache breakdown, cache avalanche?
03列中新增子行
当科学家决定搞点“花里胡哨”的东西
rem如何使用
如何解决 “主节点故障恢复的自动化” 问题?
[Ext JS]11.14 SimXhr.js?_dc=1659315492151:65 Uncaught TypeError问题分析与解决