当前位置:网站首页>正则表达式
正则表达式
2022-04-23 14:07:00 【ジ你是我永远のbugグ】
1、感受 正则表达式的魅力吧
1.1、正则表达式步骤
- 先创建一个 Pattern 对象,模式对象,就是一个正则表达式对象
Pattern pattern = Pattern.compile("[a-zA-z]+");
- 创建一个匹配器对象:就是matcher 匹配器按照 pattern 到content文本中取匹配符合要求的
Matcher matcher = pattern.matcher(content);
- 开始循环匹配
while (matcher.find()){
// 匹配内容。放到matcher.group(0)
System.out.println("找到:" + matcher.group(0));
}
1.2、示例
/** * 体验正则表达式的威力,给我们问们处理带来哪些便利 * * 正则表达式专门处理文本类的问题 */
public class A_regexp {
public static void main(String[] args) {
// 如下 文本
String content = "订单软件一般用于显示数字和其他项以便快速引用和分析。" +
"在现实生活中:订单软件有表格应用软件也有表格控件," +
"典型的像Office word,excel表格是1最常用的订单数据处8理方式之一," +
"主要6用于输入、输出、显示、处理和打印数据,可以制作各种复杂的表格文档," +
"甚至能帮助用5户进行复杂6的统计运算和图表32化展示1等。表格控件还4可常用于数据库中1数据的呈现和编辑" +
"数据录入界面设计、数据交换(如与Excel交换数据)、数据报表及分发等。比如Spread ComponentOne的FlexGrid。" +
"ip:172.16.20.20;192.16.255.185";
// 提取文章中所有的英文单词
// 1、传统方法,遍历 代码量大,效率不高
// 2、使用正则表达式技术匹配单词
// 1、先创建一个 Pattern 对象,模式对象,就是一个正则表达式对象
// Pattern pattern = Pattern.compile("[a-zA-z]+"); // 匹配英文单词
// Pattern pattern = Pattern.compile("[0-9]+"); //匹配数字
// Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-z]+)"); //匹配数字 + 英文单词
Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+"); //ip地址
// 2、创建一个匹配器对象:就是matcher 匹配器按照 pattern 到content文本中取匹配符合要求的
Matcher matcher = pattern.matcher(content);
// 3、开始循环匹配
while (matcher.find()){
// 匹配内容。放到matcher.group(0)
System.out.println("找到:" + matcher.group(0));
}
}
}
示例结果:匹配英文单词
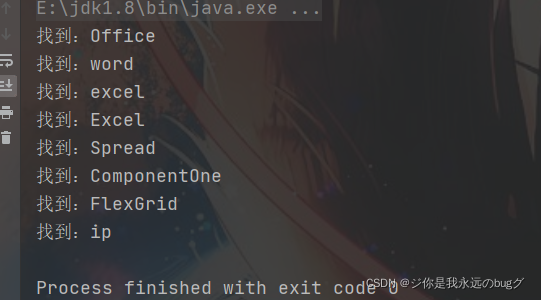
2、正则表达式的底层原理
什么是正则表达式分组
(\d\d)(\d\d)
正则表达式分组: 第一个()是第一组 第二个是第二组
2.1、正则表达式不分组
/** * 正则表达式的原理:底层实现 * demo:获取文本中 连续出现的4个数字:1998 */
public class B_RegTheory {
public static void main(String[] args) {
String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。1999年6月," +
"Sun公司发布了第二代Java平台(简称为Java2)的3个版本:J2ME(Java2 Micro Edition,Java2平台的微型版)," +
"应用于移动、无线及有限资源的环境;J2SE(Java 2 Standard Edition,Java 2平台的标准版)," +
"应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2平台的企业版),应用于基于Java的应用服务器。Java 2平台的发布," +
"是Java发展过程中最重要的一个里程碑,标志着Java的应用开始1991普及。\n" +
"1999年4月27日,HotSpot虚拟机发布。HotSpot虚拟机发2992布时是作为JDK 1.2的附加程序3993提供的," +
"后来它成为了JDK 1.3及之12345678后所有版本的Sun JDK的默认虚拟机";
/** * 获取文本中 连续出现的4个数字:如1998 * * 说明: * 1、\\d表示一个任意的数字 * */
String regStr = "\\d\\d\\d\\d";
// 先创建一个 Pattern 对象,模式对象,就是一个正则表达式对象
Pattern pattern = Pattern.compile(regStr);
// 2、创建一个匹配器对象:就是matcher 匹配器按照 pattern 到content文本中取匹配符合要求的
Matcher matcher = pattern.matcher(content);
// 3、开始循环匹配
while (matcher.find()){
// 匹配内容。放到matcher.group(0)
System.out.println("找到:" + matcher.group(0));
}
}
}
2.1.1 matcher.find() 作用
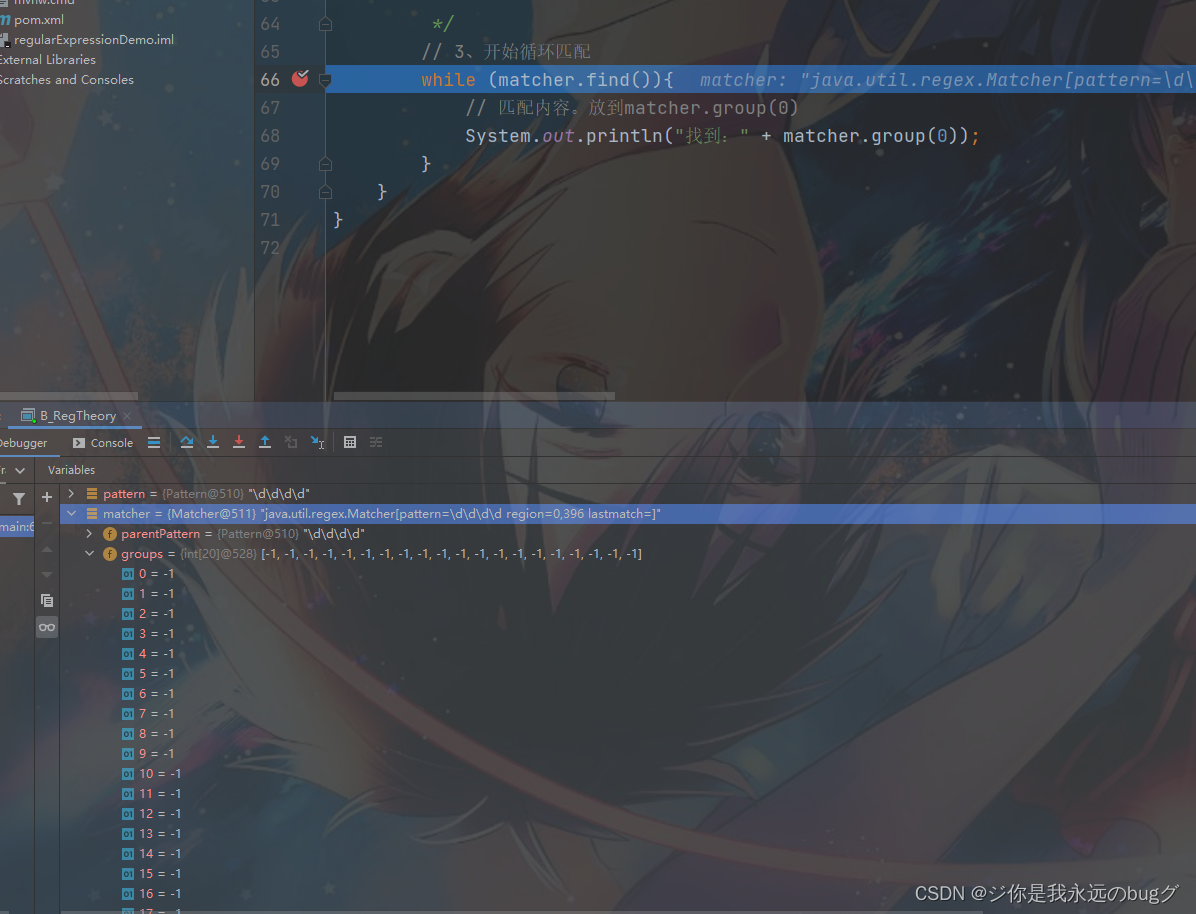
1、根据指定规则定位满足规则的子字符串(比如1998)
2、找到后,将子字符串的开始索引记录到matcher对象的属性中 int[] groups;
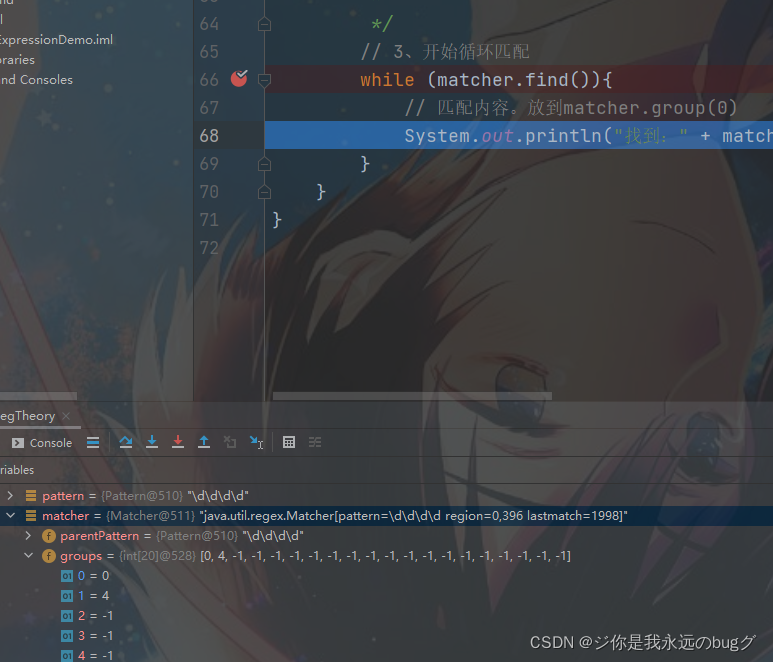
比如 1998中 1的索引为0 groups[0] = 0
结束字符 8的索引 +1 的值记录在 groups[1] = 4
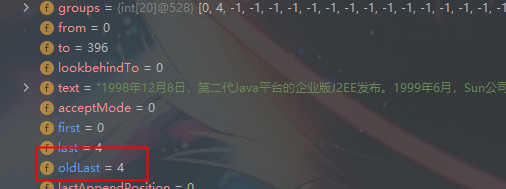
3、同时记录oldLast 的值为 匹配结束字符 的索引 +1 下次的 find 从该处开始
打个断点看看:groups 默认值为 -1
断点下一步 groups[0] = 0 groups[1] = 4
同时 oldLast = 4 下次 从 4 开始 匹配
2.1.2、matcher.group(0) 作用
源码:
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
根据 group[0] = 0 和 group[1] = 4的记录的位置 ,从content 开始截取子字符串返回
就是 从 String 文本中的 subString(0,4) 打印出 符合规则的文本
2.2、正则表达式分组
String regStr = “(\d\d)(\d\d)”;
/** * 正则表达式的原理:底层实现 * demo:获取文本中 连续出现的4个数字:1998 正则表达式分组 */
public class C_RegTheory {
public static void main(String[] args) {
String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。1999年6月," +
"Sun公司发布了第二代Java平台(简称为Java2)的3个版本:J2ME(Java2 Micro Edition,Java2平台的微型版)," +
"应用于移动、无线及有限资源的环境;J2SE(Java 2 Standard Edition,Java 2平台的标准版)," +
"应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2平台的企业版),应用于基于Java的应用服务器。Java 2平台的发布," +
"是Java发展过程中最重要的一个里程碑,标志着Java的应用开始1991普及。\n" +
"1999年4月27日,HotSpot虚拟机发布。HotSpot虚拟机发2992布时是作为JDK 1.2的附加程序3993提供的," +
"后来它成为了JDK 1.3及之12345678后所有版本的Sun JDK的默认虚拟机";
/** * 获取文本中 连续出现的4个数字:如1998 * * 说明: * 1、\\d表示一个任意的数字 * * 正则表达式 有一个()是一组 两个是两组 * */
String regStr = "(\\d\\d)(\\d\\d)";
// 先创建一个 Pattern 对象,模式对象,就是一个正则表达式对象
Pattern pattern = Pattern.compile(regStr);
// 2、创建一个匹配器对象:就是matcher 匹配器按照 pattern 到content文本中取匹配符合要求的
Matcher matcher = pattern.matcher(content);
// 3、开始循环匹配
while (matcher.find()){
// 匹配内容。放到matcher.group(0)
System.out.println("找到:" + matcher.group(0));
System.out.println("找到第一组:" + matcher.group(1));
System.out.println("找到第二组:" + matcher.group(2));
}
}
}
分组最大的区别在于 matcher.find():
1、根据指定规则定位满足规则的子字符串(比如1998)
2、找到后,将子字符串的开始索引记录到matcher对象的属性中 int[] groups;
比如 1998中
2.1、 1的索引为0 groups[0] = 0 结束字符 8的索引 +1 的值记录在 groups[1] = 4
2.2、 记录第一组 匹配到的字符串19 groups[2] = 0, 结束字符 9的索引 +1 :groups[3] = 2
2.3、 记录第二组 匹配到的字符串98 groups[4] = 2, 结束字符 8的索引 +1 :groups[5] = 4
以此类推
3、同时记录oldLast 的值为 匹配结束字符 的索引 +1 下次的 find 从该处开始
断点看一下
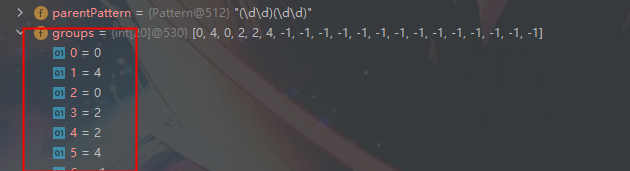
这时 可以打印 正则表达式 各个分组匹配到的 字符串
// 3、开始循环匹配
while (matcher.find()){
// 匹配内容。放到matcher.group(0)
System.out.println("找到:" + matcher.group(0));
System.out.println("找到第一组:" + matcher.group(1));
System.out.println("找到第二组:" + matcher.group(2));
}

3、元字符
3.1、转义号
转移号:\
提示:java中的两个 \\ 相当于 其他语言中的 一个 \
说明: 用正则表达式检索某些特殊字符的时候,需要用到转义符号\\ 否则检索不到结果 甚至报错
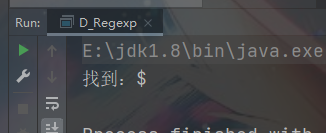
案例: 用 $ 去匹配 “abc$(”
public class D_Regexp {
public static void main(String[] args) {
String str = "abc$(abc(123(";
String regStr = "\\$";
Pattern compile = Pattern.compile(regStr);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
}
}
只有加 \\ 才能检索到 特殊字符
3.2、字符匹配符
| 字符匹配符 | 说明 | 示例 | 示例说明 | 符合要求的demo |
|---|---|---|---|---|
| [] | 可匹配的字符列表 | [efgh] | 匹配 e、f、g、h中任意一个 | e |
| [^] | 不可匹配的字符列表 | [^edgh] | 匹配除了[] 中的edgh以外的任意一个 | a |
| - | 连接符 | [a-z] | 匹配a-z中任意一个小写字母 | a |
| . | 匹配除 \n之外的任何字符 | a…b | 以a开头 以b结尾 中间包括两个任意字符长度为4的字符串 | aaab |
| \\d | 匹配单个数字字符 == [0-9] | \\d{3}(\\d)? | 匹配连续 3个 或四个数字的字符串 | abc123 |
| \\D | 匹配单个非数字字符 相当于 [^0-9] | \\D(\\d)* | 以单个非数字开头,后接任意个数字字符串 | a12354 |
| \\w | 匹配单个数字、大小写字母字符和下划线 == [0-9a-zA-z_] | \\d{3}\\w{4} | 以三个数字后接 4个数字/大小写字母字符/_ | 123as1_ |
| \\W | 匹配单个非 数字、大小写字母字符和下划线 == [^0-9a-zA-z_] | \\W+\\d{2} | 至少一个 非 数字、大小写字母字符 后接 2个数字结尾的字符串 | #$23 |
| \\s | 匹配任何空白字符(空格、制表符等) | \\s | c v | |
| \\S | 匹配任何非空白字符(空格、制表符等) |
理解:
1、\\d{3} == \\d\\d\\d
2、(\\d)? == \\d 有可能有一个也有可能没有
3、(\\d)* == 有任意个 \\d
4、\\W+ == 至少一个 \\W
5、[^a-z]{2} == 连续两个不是a-z的字符
不区分大小写
不区分大小写
1、(?i)q (?i)这个后面的不区分大小写匹配
(?i)acb abc不区分大小
a(?i)bc bc不区分大小
a((?i)b)c b不区分大小
2、Pattern compile = Pattern.compile(regStr,Pattern.CASE_INSENSITIVE);
3.3 选择匹配符
|
: 匹配“ | ” 之前或之后的表达式
如:ab|cd :ab或者cd
3.4、限定符
指定其前面的字符和组合项连续出现多少次
| 限定符 | 说明 | 示例 | 示例说明 | 符合要求的demo |
|---|---|---|---|---|
| * | 指定 字符出现 0次或 n次 | (abc)* | 仅包含任意个abc的字符串 | abcabcabc |
| + | 指定字符出现至少1次 | m+ | 至少一个m开头的字符串 | mmss |
| ? | 指定字符重复0次或者1次 | cm? | c后面 有0个m或者1个m | cmab c |
| {n} | 指定字符出现的n次数 | [a-z]{3} | a-z之间的字符一共出现3次 | abc |
| {n,} | 指定字符至少出现n次数 | [a-z]{3,} | a-z之间的字符至少出现3次 | asfv |
| {n,m} | 指定字符出现至少N次 最多m次 | [a-z]{3,4} | a-z之间的字符出现至少3次 最多4次 | abc |
| ? | 任何限定符跟?,匹配模式改为 非贪婪模式 | o+? | 原本是o至少出现一次,加上?就是只能是一次 | aa0 |
理解:
java 尽量匹配多的 默认 贪婪匹配
什么是贪婪匹配
如:b{3,4} 文本为"bbbbb" 此时b有5个 正则表达式会 匹配到 4个bbbb,尽可能多的匹配
非贪婪匹配:o+? o+本来是至少一次,现在加上?就是非贪婪匹配,只能匹配出现1个o
1、ab{3,4} a后面跟3个或者4个b
2、[ab]{3,4} a或者b连续出现三个或四个
3、(ab){3,4} ab连续出现三个或四个
4、cm? c后面 有0个m或者1个m
.cm? 只限定于 ? 前的字符
3.5、定字符
规定字符出现的位置,比如开始结束的位置
| 限定符 | 说明 | 示例 | 示例说明 | 符合要求的demo |
|---|---|---|---|---|
| ^ | 指定起始字符 | ^a | 以a开头 | abc |
| $ | 指定结束字符 | [a-z]+$ | 至少一个小写字母结尾 | 1-ss |
| \\b | 匹配目标字符串的边界 | han\\b | 字符串以空格分割成子串, 子串以han结尾的 | aaa nnhan mmm |
| \\B | 匹配非目标字符串的边界 | han\\B | 字符串以空格分割成子串, 子串不以han结尾的 | aaa hannn mmm |
3.6、 分组
3.6.1、捕获 分组
1、非命名捕获(pattern)
捕获匹配的子字符串。编号为0的(group(0))捕获的是整个正则表达式匹配的;
其他捕获结果 是根据分组()从左向右的顺序从 1 开始编号(group(1)group(2)).
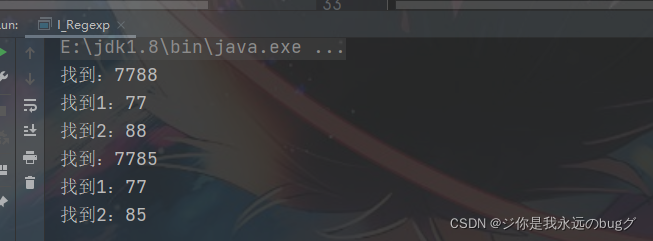
示例:
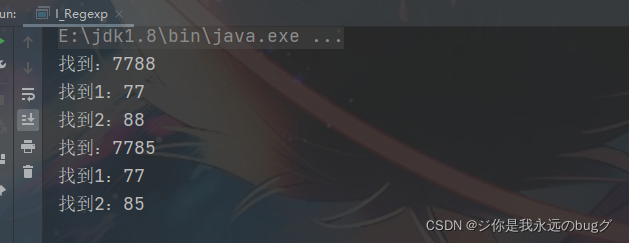
String str = "asdvxs s7788 nn7785bb";
/** * 非命名 分组:()是一组 * group(0)) 捕获的是整个正则表达式匹配的 * group(1) 捕获的是 第一个分组 * group(2) 捕获的是 第二个分组 * */
String reg = "(\\d\\d)(\\d\\d)";
Pattern compile = Pattern.compile(reg);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
/** * 非命名 分组 */
System.out.println("找到1:" + matcher.group(1));
System.out.println("找到2:" + matcher.group(2));
}
2、命名分组(?<name>pattern)
命名捕获,将匹配的子字符串捕获到一个组名或编号名称中,可以用编号或 组名 获取匹配的内容
name的字符串不能包含任何标点符号,并且不能以数字开头,可以使用单引号替代尖括号,例如 :(?‘name’)示例:
String str = "asdvxs s7788 nn7785bb";
/** * * 命名分组 * */
String reg = "(?<d1>\\d\\d)(?<d2>\\d\\d)";
Pattern compile = Pattern.compile(reg);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
/** * 命名分组 */
System.out.println("找到1:" + matcher.group("d1"));
System.out.println("找到2:" + matcher.group("d2"));
}
就是给分组命名,用名字取匹配的内容
3.6.2、非捕获分组
非 捕获分组,不能根据 group() 获取匹配的内容。
1、(?:pattern)
匹配pattern 但不捕获该 匹配的子表达式,即他是
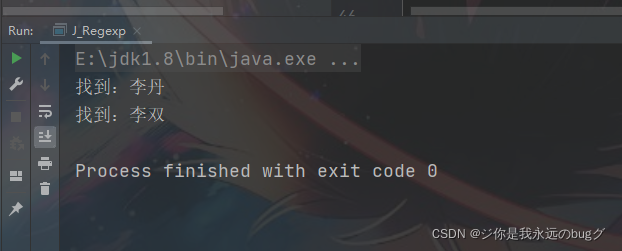
作用: 李(?:丹|双) == 李丹|李双
示例:
/** * (?:pattern) */
String str = "李丹 李双";
// String regStr = "李丹|李双";
String regStr = "李(?:丹|双)";
Pattern compile = Pattern.compile(regStr);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
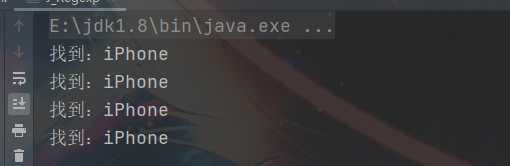
2、(?=pattern)
非捕获匹配 作用:iPhone(?=5|6|8|13) 匹配 iPhone 后是5或者6或者8或者13的 iPhone字符串 但不会匹配 iPhone后是7 的iPhone字符串
/** * (?=pattern) */
String str = "iPhone5,iPhone6,iPhone8,iPhone13,iPhone20";
// String regStr = "李丹|李双";
String regStr = "iPhone(?=5|6|8|13)";
Pattern compile = Pattern.compile(regStr);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
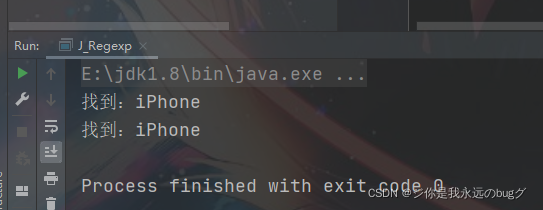
3、(?=pattern)
非捕获匹配 作用:iPhone(?!5|6|8|13) 除了不匹配 iPhone 后是5或者6或者8或者13的 iPhone字符串,其他都匹配
/** * (?=pattern) */
String str = "iPhone5,iPhone6,iPhone8,iPhone13,iPhone20";
// String regStr = "李丹|李双";
String regStr = "iPhone(?!15|6|8|13)";
Pattern compile = Pattern.compile(regStr);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
4、反向引用
反向引用需要用到 分组和捕获
1、分组: 用一个()组成一个分组
2、捕获 获取 一个分组匹配的子字符串 可由 group(1)group(2)…获取
3、反向引用
分组的内容被捕获后,可以在这个括号后被使用。从而写出一个比较实用的匹配模式,这个我们称为 反向引用
这个引用既可以用在 正则表达式内部 用\\分组号 也可以是在正则表达式外部,用 $分组号
4.1 匹配两个连续的相同数字
/** * 匹配两个连续的相同数字 内部引用 * */
String str = "12312216543663789";
String regStr = "(\\d)\\1";
Pattern compile = Pattern.compile(regStr);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
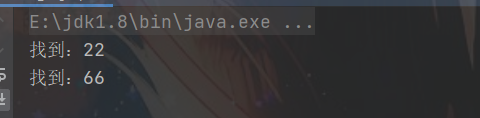
4.2 匹配五个连续的相同数字
/** * 匹配五个连续的相同数字 内部引用 * */
String str = "12312216543666663789";
String regStr = "(\\d)\\1{4}";
Pattern compile = Pattern.compile(regStr);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
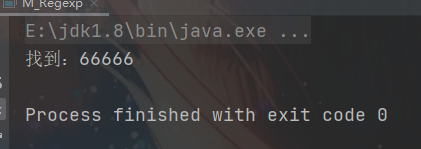
4.3 找出格式:1221 3663数字
/** * 要求 找出四个数字连在一起的 并且 第一位和第四位相同 第二位和第三位相同 如 1221 3663 */
String str = "12312216543663789";
String regStr = "(\\d)(\\d)\\2\\1";
Pattern compile = Pattern.compile(regStr);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
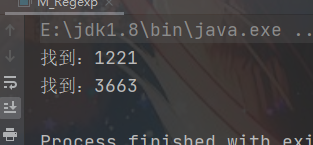
4.4、找到 类似:12321-444999666
/** * 找到 类似:12321-444999666 */
String str = "12312212321-44499966663789";
String regStr = "(\\d)(\\d)(\\d)\\2\\1-(\\d)\\4{2}(\\d)\\5{2}(\\d)\\6{2}";
Pattern compile = Pattern.compile(regStr);
Matcher matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
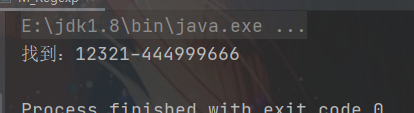
5、结巴 去重
如:我…我要去…学学学…java == 我要去学java
String str = "我...我要去...学学学...java";
// 1、去掉点.
Pattern compile = Pattern.compile("\\.");
Matcher matcher = compile.matcher(str);
str = matcher.replaceAll("");
System.out.println(str);
/** * 2、去掉重复的字 * 思路: 1、用 反向引用 拿到重复的字 (.)\\1+ * 2、使用 外部反向引用$1 替换匹配的内容 */
compile = Pattern.compile("(.)\\1+"); // 分组的捕获内容记录到了 $1
matcher = compile.matcher(str);
while (matcher.find()){
System.out.println("找到:" + matcher.group(0));
}
// 使用 外部反向引用$1 替换匹配的内容 用 我 替换我我
str =matcher.replaceAll("$1");
System.out.println(str);
6、String 类 中使用正则表达式
String.matches() 是整体匹配
public static void main(String[] args) {
String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。JDK1.3 和 JDK1.4 和 J2SE1.3相继发布";
// 使用正则表达式 将JDK1.3 JDK1.4 替换成 JDK
content = content.replaceAll("JDK1.3|JDK1.4", "JDK");
System.out.println(content);
// 要求: 验证一个手机号,要求必须是 138 139 开头
content = "13816966686";
boolean matches = content.matches("^(138|139)\\d{8}");
System.out.println(matches);
// 要求按照 # 或者 - 或者 ~ 或者 数字 来分割
content = "nihao#mawoshi-nidie~shima18suila";
String[] split = content.split("[\\#\\-\\~\\d]");
for (Object d:split) {
System.out.println(d);
}
}
结束Test
1、验证邮箱是否合法
/** * 1、验证邮箱是否合法 * 规则: * 1、只能有一个@ * 2、@前是用户名 可以是a-zA-Z0-9和-_字符 * 3、@后是域名,并且域名只能是英文字母,如:sohu.com */
String str = "[email protected]";
String regStr = "^[a-zA-Z0-9\\-\\_]+@([a-zA-Z]+\\.)+[a-zA-Z]+$";
if (str.matches(regStr)){
System.out.println("1ok");
}
2、验证是不是整数 或者 小数
/** * 2、验证是不是整数 或者 小数 * 要考虑正数数 和 负数 * 比如:123 -123 34.89 -87.3 -0.01 0.45 * 0089 不合理 */
String str2 = "89.139909";
String regStr2 = "^[\\+\\-]?([1-9]\\d*|0)(\\.)?\\d+$";
if (str2.matches(regStr2)){
System.out.println("2ok");
}
3、一个url 进行解析
/** * 对 一个url 进行解析 http://www.baidu.com:8080/abc/index.htm * * 获取 其 :协议: http/https * 域名: www.baidu.com * 端口: 8080 * 文件名:index.htm * */
String str3 = "http://www.baidu.com:8080/abc/index.htm";
String regStr3 = "^([a-z]+)://([a-zA-Z.]+):(\\d+)[\\w-/]*/([\\w.]+)$";
Pattern pattern = Pattern.compile(regStr3); // 匹配英文单词
Matcher matcher = pattern.matcher(str3);
// 3、开始循环匹配
while (matcher.find()){
// 匹配内容。放到matcher.group(0)
System.out.println("找到:" + matcher.group(0));
System.out.println("找到协议:" + matcher.group(1));
System.out.println("找到域名:" + matcher.group(2));
System.out.println("找到端口:" + matcher.group(3));
System.out.println("找到文件名:" + matcher.group(4));
}
版权声明
本文为[ジ你是我永远のbugグ]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_47848696/article/details/123068331
边栏推荐
- Cdh6 based on CM management 3.2 cluster integration atlas 2 one
- RobotFramework 之 公共变量
- 关于训练过程中损失函数出现断崖式增长的问题
- 如何快速批量创建文本文档?
- Win10 comes with groove music, which can't play cue and ape files. It's a curvilinear way to save the country. It creates its own aimpack plug-in package, and aimp installs DSP plug-in
- 云容灾是什么意思?云容灾和传统容灾的区别?
- redis数据库讲解(四)主从复制、哨兵、Cluster群集
- 01-NIO基础之ByteBuffer和FileChannel
- jacob打印word
- Chapter I review of e-commerce spike products
猜你喜欢

帆软分割求解:一段字符串,只取其中某个字符(所需要的字段)
Some experience of using dialogfragment and anti stepping pit experience (getactivity and getdialog are empty, cancelable is invalid, etc.)
使用Postman进行Mock测试
How QT designer adds resource files
VMware15Pro在Deepin系统里面挂载真机电脑硬盘
Jira截取全图
Visio installation error 1:1935 2: {XXXXXXXX
MYSQL 主从同步避坑版教程
RecyclerView细节研究-RecyclerView点击错位问题的探讨与修复
Check in system based on ibeacons


随机推荐
How QT designer adds resource files
Wechat applet obtains login user information, openid and access_ token
redis数据库讲解(四)主从复制、哨兵、Cluster群集
封装logging模块
室内外地图切换(室内基于ibeacons三点定位)
使用itextpdf实现截取pdf文档第几页到第几页,进行分片
RecyclerView细节研究-RecyclerView点击错位问题的探讨与修复
sql中出现一个变态问题
postman批量生产body信息(实现批量修改数据)
基于CM管理的CDH6.3.2集群集成Atlas2.1.0
VMware Workstation 无法连接到虚拟机。系统找不到指定的文件
微信小程序进行蓝牙初始化、搜索附近蓝牙设备及连接指定蓝牙(一)
CDH cluster integration Phoenix based on CM management
leetcode--380. O (1) time insertion, deletion and acquisition of random elements
帆软报表设置单元格填报以及根据值的大小进行排名方法
Use of WiFi module based on wechat applet
Jmeter设置环境变量支持在任意终端目录输入jmeter直接启动
基于ibeacons签到系统
RecyclerView高级使用(一)-侧滑删除的简单实现
FBS (fman build system) packaging