当前位置:网站首页>CDH cluster integration Phoenix based on CM management
CDH cluster integration Phoenix based on CM management
2022-04-23 14:03:00 【A hundred nights】
be based on CM Managed CDH Cluster integration Phoenix
Background introduction : The original CDH colony , With Hive+Hbase+Impala Conduct data processing query ,Hbase Grammar is difficult to understand , Different from ordinary SQL,Impala Speed query is too slow to modify records . Therefore, consider using Phoenix To integrate Hbase、Hive To solve the above problems .
Premise : Has been based on CM Installation of structures, CDH colony , In this paper parcels Package integration Phoenix To CDH colony .
download Phoenix Parcel Bao He Jar Package and upload to CM-Server node
Adopted in this paper phoenix The version package is as follows :
# Parcel package
manifest.json
PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel
PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel.sha1
# Jar package
PHOENIX-1.0.jar
(1) modify .sha1 File for .sha, Remove the suffix 1. take phoenix Of parcel Bao He jar Packages uploaded to cloudera manager server Node httpd Under service /var/www/html/phoenix, modify phoenix Folder permissions 777. And can be found in http visit http://cdh001/pheonix.
chmod 777 -R /var/www/html/phoenix
# /var/www/html/phoenix The directory structure is as follows
-rwxrwxrwx. 1 root root 2478 8 month 1 2019 manifest.json
-rwxrwxrwx 1 root root 5306 3 month 18 10:37 PHOENIX-1.0.jar
-rwxrwxrwx. 1 root root 402216960 8 month 1 2019 PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel
-rwxrwxrwx. 1 root root 41 8 month 1 2019 PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel.sha
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-dt4oEoO9-1648092283868)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20220324105131812.png)]](/img/28/2621040329f77f569578d850be1279.png)
(2) take parcl Package is copied to the /opt/cloudera/parcel-repo Catalog ( Be careful manifest.json If phoenix In the directory ), And modify the authority 777.
chmod 777 -R /opt/cloudera/parcel-repo
#/opt/cloudera/parcel-repo The directory structure is as follows
-rwxrwxrwx. 1 root root 2478 8 month 1 2019 manifest.json
-rwxrwxrwx. 1 root root 402216960 8 month 1 2019 PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel
-rwxrwxrwx. 1 root root 41 8 month 1 2019 PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel.sha
(3) take phoenix Of jar Put the bag in /opt/cloudera/csd Under the table of contents , And copy to httpd Service directory , Modify the permissions 777.
chmod 777 *R /opt/cloudera/csd
#/opt/cloudera/csd The directory structure is as follows
-rwxr-xr-x 1 root root 5306 3 month 18 10:39 PHOENIX-1.0.jar
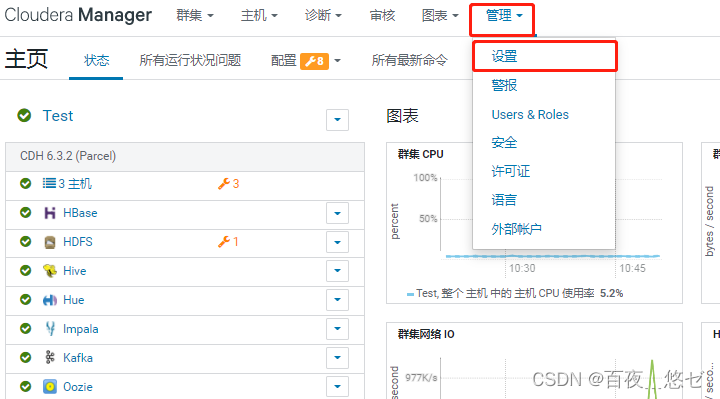
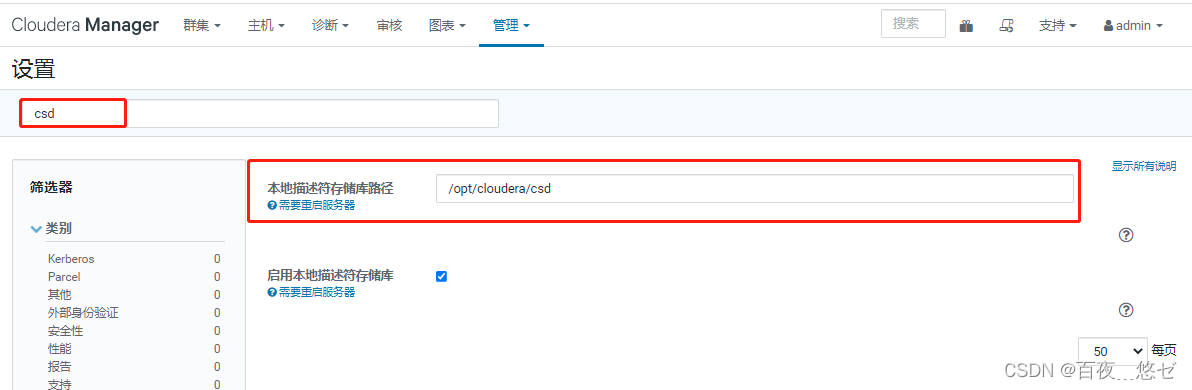
(4) stay CM interface : “ management ”->“ Set up ”-> Input query "csd"-> Change the local descriptor repository path to "/opt/cloudera/csd"
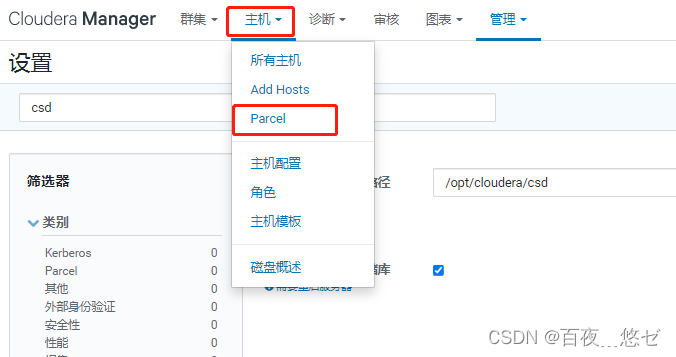
(5) stay CM interface : “ host ”->“Parcel”->“ To configure ”-> long-range Parcel The repository URL Newly added phoenix route “http://cdh001/phoenix/”
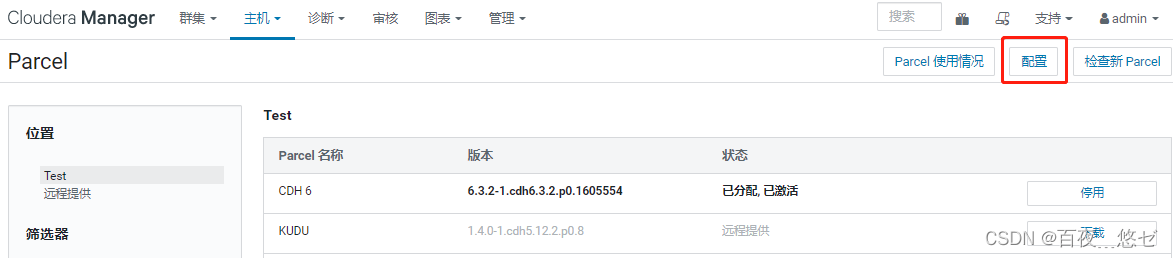
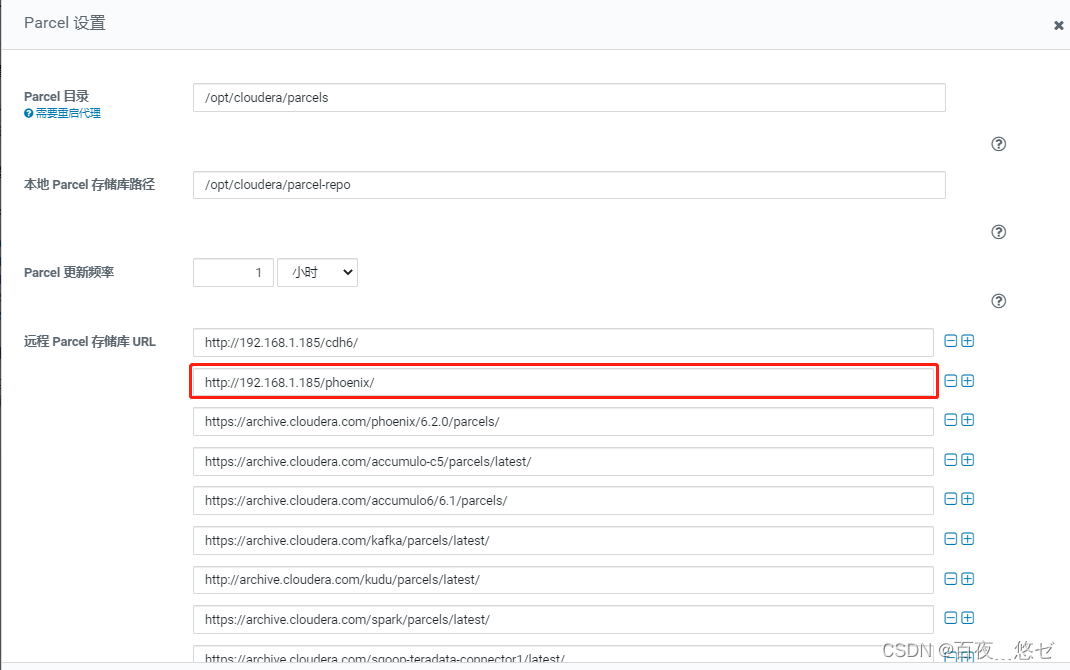
(6)“ Check for updates Parcel”-> find PHOENIX “ download ”->“ Distribute ”->“ Activate ”

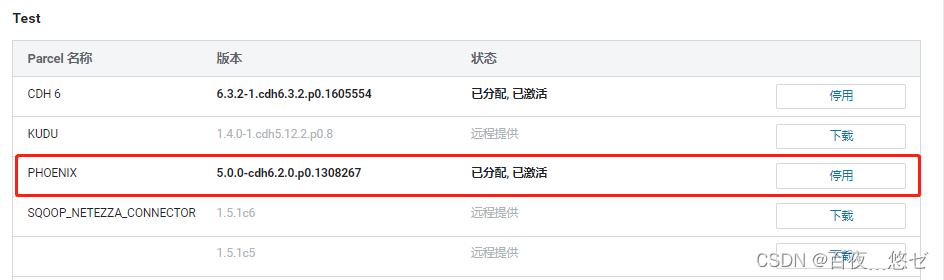
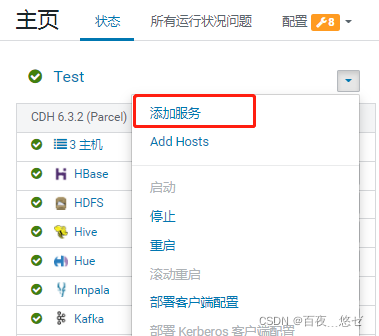
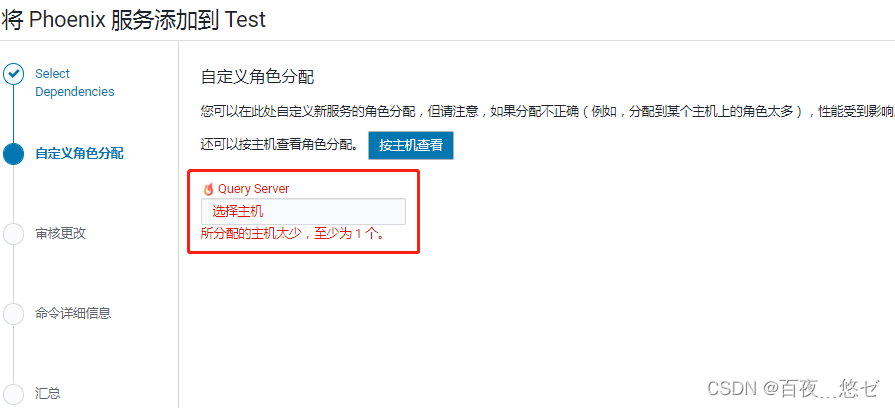
(7) stay CM Main interface operation : colony menu bar " Add service "-> choice "PHOENIX"->quary server Node allocation (3 Cluster all )-> Service startup , go back to CM The interface can see Phoenix.

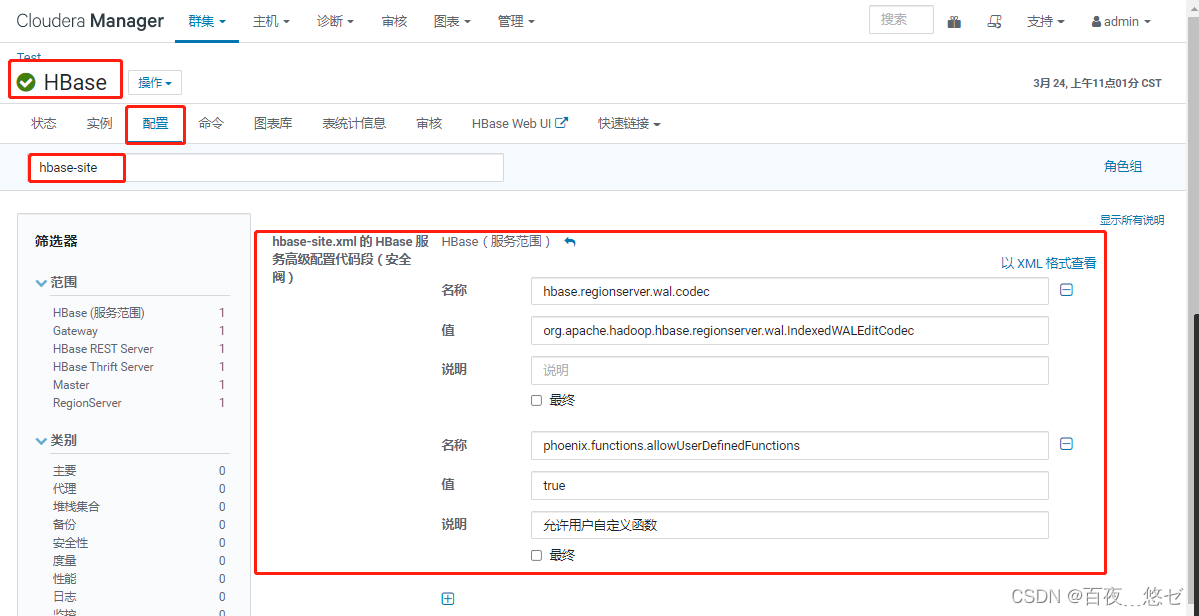
(8) To configure HBASE, “HBASE”->“ To configure ”-> Search for "hbase-site.xml"->“hbase-site.xml Of HBase Service advanced configuration code snippet ”, With XML Format view , Paste the following , And save . This step is phoenix Integrate hbase.
<!-- Define write to prewrite log wal code -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<!-- Enable user-defined functions (UDF) -->
<property>
<name>phoenix.functions.allowUserDefinedFunctions</name>
<value>true</value>
<description>enable UDF functions</description>
</property>
(9) Save configuration changes , Restart expired Services hbase and phoenix.
(10) take Phoenix Configure the installation path into the system environment variable ( All installations Phoenix Node execution ).
vim /etc/profile
#--------------------phoenix------------------------------------
export PHOENIX_HOME=/opt/cloudera/parcels/PHOENIX-5.0.0-cdh6.2.0.p0.1308267
export PATH=$PATH:$PHOENIX_HOME/bin
# Activation takes effect
source /etc/profile
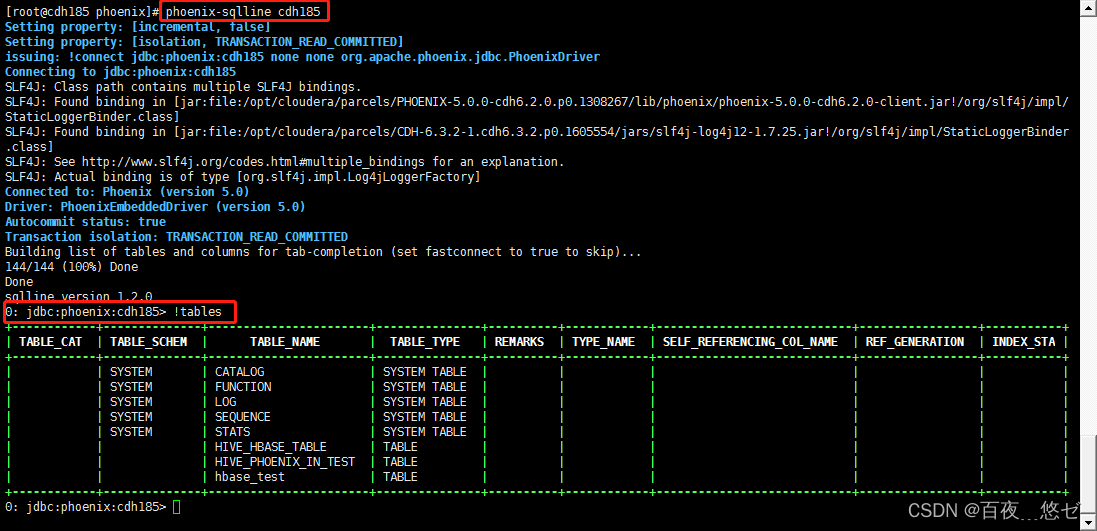
(11) Any node starts phoenix, Through the command phoenix-sqlline zk node hostname:2181/hbase Enter the interactive interface .
phoenix-sqlline cdh185
Enter the command !table When you can see the output table, it will run normally .
Phoenix Integrate Hive
Hive-phoenix Before integration, in hive An error is reported when creating a mapping table in
ParseException: Syntax error in line 7:undefined: STORED BY 'org.apache.phoenix.hive.PhoenixStorageHandler' ^ Encountered: BY Expected: AS CAUSED BY: Exception: Syntax error
Integration approach : take phoenix Installation directory lib in phoenix-5.0.0-cdh6.2.0-hive.jar copy to hive The installation directory /lib in . All installations pheonix All nodes need to be copied .
cp /opt/cloudera/parcels/PHOENIX/lib/phoenix/phoenix-5.0.0-cdh6.2.0-hive.jar /opt/cloudera/parcels/CDH/lib/hive/lib
notes : stay impala End cannot create hive-phoeinx The mapping table .
Hive-Hbase Table mapping implementation
a、hive mapping hbase Table that already exists in
# Get into hbase-shell command :
hbase shell
# establish hbase Table command :
create 'hbase_test','user'
# Insert data command :
put 'hbase_test','111','user:name','jack'
put 'hbase_test','111','user:age','18'
# Inquire about hbase Table command :scan 'hbase_test'
# Get into hive establish hbase Association table
create external table hbase_test1(
id int,
name string,
age int
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,user:name,user:age")
TBLPROPERTIES("hbase.table.name" = "hbase_test");
# see hive Table data , command :
select * from hbase_test1
# Go to hive Insert data into the table :
insert into hbase_test1(id,name,age) values(333,'mary',25);
# Inquire about hive Table data , command :
select * from hbase_test1
# Check at the same time hbase Table data , Yes hive New record in
Phoenix-Hbase Table mapping implementation
a、phoenix mapping hbase Tables already in
#phoenix-shell Start command
phoenix-sqlline.py cdh185:2181
# stay phoenix Create the same table name in and realize Hbase Mapping of tables
create table if not exists "hbase_test"(
"id" varchar primary key,
"user"."name" varchar,
"user"."age" varchar
)
column_encoded_bytes=0;
create view if not exists "hbase_test2"(
"id" varchar primary key,
"user"."name" varchar,
"user"."age" varchar
)
column_encoded_bytes=0;
Be careful :
Phoneix Table created in and HBase The table names mapped in should be the same
phoneix The field name and HBase The field name of the mapping table in should be the same ( Pay attention to case )
# Insert data command :
upsert into "hbase_test"(id,"name","age") values('444','haha','33');
# stay hbase You can view the new record in
Hive-Phoenix Table mapping implementation
Hive Create an internal table at the end
For internal tables ,Hive Manage the lifecycle of tables and data . establish Hive Table time , The corresponding... Will also be created Phoenix surface . once Hive Table deleted ,Phoenix The table is also deleted .
#hive Create an internal table at the end , And map phoenix.
create table hive_phoenix_in_test (
s1 string,
i1 int,
f1 float,
d1 double
)
stored as parquetfile
STORED BY 'org.apache.phoenix.hive.PhoenixStorageHandler'
TBLPROPERTIES (
"phoenix.table.name" = "hive_phoenix_in_test",
"phoenix.zookeeper.quorum" = "cdh185,cdh186,cdh188",
"phoenix.zookeeper.znode.parent" = "/hbase",
"phoenix.zookeeper.client.port" = "2181",
"phoenix.rowkeys" = "s1, i1",
"phoenix.column.mapping" = "s1:s1, i1:i1, f1:f1, d1:d1",
"phoenix.table.options" = "SALT_BUCKETS=10, DATA_BLOCK_ENCODING='DIFF'"
);
#phoenix End table data query
select * from hive_phoenix_in_test
#hive Add data at the end
insert into hive_phoenix_in_test values("a",1,1.0,1.0);
+-----+-----+------+------+
| s1 | i1 | f1 | d1 |
+-----+-----+------+------+
| a | 1 | 1.0 | 1.0 |
+-----+-----+------+------+
#phoenix Add data at the end
upsert into hive_phoenix_in_test values ('b',5,1.85,4.4894165);
upsert into hive_phoenix_in_test values ('b',9,1.85,4.4894165);
+-----+-----+-------+------------+
| s1 | i1 | f1 | d1 |
+-----+-----+-------+------------+
| b | 5 | 1.85 | 4.4894165 |
| a | 1 | 1.0 | 1.0 |
| b | 9 | 1.85 | 4.4894165 |
+-----+-----+-------+------------+
#phoenix End update data ,rowkey Modify the same
upsert into hive_phoenix_in_test values ('b',5,1.85,4.54);
+-----+-----+-------+------------+
| s1 | i1 | f1 | d1 |
+-----+-----+-------+------------+
| b | 5 | 1.85 | 4.54 |
| a | 1 | 1.0 | 1.0 |
| b | 9 | 1.85 | 4.4894165 |
+-----+-----+-------+------------+
#pheonix End delete data
delete from hive_phoenix_in_test where "s1"='b' and "i1"=9;
+-----+-----+-------+-------+
| s1 | i1 | f1 | d1 |
+-----+-----+-------+-------+
| b | 5 | 1.85 | 4.54 |
| a | 1 | 1.0 | 1.0 |
+-----+-----+-------+-------+
Hive Create external tables on the client side
For external tables ,Hive And ** Existing Phoenix surface ** Use it together , Just manage Hive Metadata . from Hive Delete in EXTERNAL The table will only delete Hive Metadata , But it will not be deleted Phoenix surface .
create external table hive_phoenix_out_test (
i1 int,
s1 string,
f1 float,
d1 decimal
)
STORED BY 'org.apache.phoenix.hive.PhoenixStorageHandler'
TBLPROPERTIES (
"phoenix.table.name" = "hive_phoenix_out_test",
"phoenix.zookeeper.quorum" = "cdh185,cdh186,cdh188",
"phoenix.zookeeper.znode.parent" = "/hbase",
"phoenix.zookeeper.client.port" = "2181",
"phoenix.rowkeys" = "i1",
"phoenix.column.mapping" = "i1:i1, s1:s1, f1:f1, d1:d1"
);
Parameter description
phoenix.table.name # Specify the mapped phoenix Table name , Default and hive The table is the same
phoenix.zookeeper.quorum # hbase Of zk Management cluster , Default localhost
phoenix.zookeeper.znode.parent # Appoint HBase Of Zookeeper Parent node , Default /hbase
phoenix.zookeeper.client.port # set zookeeper port , Default 2181
phoenix.rowkeys # phoenix The main column in the list , Required
phoenix.column.mapping # hive and phoenix Mapping between column names
** Be careful :** All delete and update operations should be done in phoenix Aspect implementation .
Other configuration items , You can do it again Hive-CLI Set in .
Performance Tuning Performance tuning
| Parameter | Default Value | Description |
|---|---|---|
| phoenix.upsert.batch.size | 100 | Number of data pieces updated in batch |
| [phoenix-table-name].disable.wal | false | Temporarily set table properties disable_wal by true, That is, turn off the pre write function , Sometimes you can improve performance |
| [phoenix-table-name].auto.flush | false | When the pre write function is disabled and the automatic brush is set to true when ,memstore Refresh for hfile.hbase Component architecture |
Query Data Query data
have access to hivesql Inquire about phoenix The data in the table , On a single table hive Queries can run like phoenix As fast as queries in , And has the following attribute settings :hive.fetch.task.conversion=more and hive.exec.parallel=true.
| Parameter | Default Value | Description |
|---|---|---|
| hbase.scan.cache | 100 | Read the row size requested by the unit |
| hbase.scan.cacheblock | false | Whether to cache blocks |
| split.by.stats | false | Set to true when , The mapper uses table statistics , Every mapper Corresponding to a guide |
| [hive-table-name].reducer.count | 1 | reducer Number . stay Tez In mode , It only affects the query of a single table . |
| [phoenix-table-name].query.hint | Query hints |
Limit :hive Update and delete operations require hive and phoenix The transaction manager of both parties supports .
Column mapping cannot correctly use the mapped row key column .
mapreduce and tez There is always only one assignment reducer.
Phoenix Common grammar
phoenix Interactive interface enable command :./phoenix-sqlline hbase The node list
phoenix Of DLL Double quotation marks are recommended for all table and column names in , otherwise phoenix All will be capitalized for recognition , Do the same phoenix Use single quotation marks for the string when querying the command , Because what is in double quotation marks will be recognized as a column or table or column family .
among row It's the primary key , Corresponding hbase Of rowkey, Use of other fields " Column family ".“ Name " As field name . if hbase Column names in the table contain decimal points , If the family is ’cf’, Column name is ’root.a.b’, It's in Phoenix Of DDL The corresponding in should be "cf”.“root.a.b” varchar.
| command | function | Examples |
|---|---|---|
| !tables | View all current data table names ( Equate to show tables) | !tables |
| select | Query table data | select…from… |
| upsert | Add or change data | upsert into tname values(xx) |
| delete | Delete table record | delete from tname |
版权声明
本文为[A hundred nights]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231401520772.html
边栏推荐
猜你喜欢






随机推荐
微信小程序获取登录用户信息、openid和access_token
Basic knowledge learning record
Jiannanchun understood the word game
go 语言 数组,字符串,切片
PATH环境变量
1256:献给阿尔吉侬的花束
Analysis and understanding of atomicintegerarray source code
Un modèle universel pour la construction d'un modèle d'apprentissage scikit
json反序列化匿名数组/对象
mysql新表,自增id长达20位,原因竟是......
Crontab timing task output generates a large number of mail and runs out of file system inode problem processing
Redis docker 安装
趣谈网络协议
FBS(fman build system)打包
Universal template for scikit learn model construction
3300万IOPS、39微秒延迟、碳足迹认证,谁在认真搞事情?
redis如何解决缓存雪崩、缓存击穿和缓存穿透问题
Pytorch 经典卷积神经网络 LeNet
freeCodeCamp----time_ Calculator exercise
Restful WebService和gSoap WebService的本质区别