当前位置:网站首页>SEATA分布式事务框架解析
SEATA分布式事务框架解析
2022-08-09 13:15:00 【软件开发随心记】
随着微服务框架的流行,目前应用服务的设计也越来越精细化。过去单应用就能完成的任务,目前可能会拆分打散到各个不同的子服务中,如用户中台、数据中台、订单中心、库存平台。随之而来的问题是如何保证各个子服务间数据的一致性,从中提出了分布式事务的需求。
为什么需要事务
在对分布式事务进行介绍之前,有必要再回顾一下事务的基本概念。
我们知道事务的概念是指“事务中的一系列操作要么全部成功,要么一个不做”,并且具有ACID四个基本特性:
- 原子性(Atomicity):整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性(Consistency):在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
- 隔离性(Isolation):隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务运行在相同的时间内执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
- 持久性(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
上面四个特性经常作为计算机考试要点,相信大家都不陌生。不过我们再次认真思考一下,我们平时使用事务的过程中,最重要的目的是什么?或者说ACID四者之中,哪一个才是我们最为关注的。
笔者认为,事务之所以有不可替代的重要性,是因为它的一致性保证,也就是Consistency。
先看原子性以及隔离性,它们解决的核心问题是在并发场景下确保数据写入与程序预期一致。然而退一步讲,我们可以通过调整程序逻辑将所有并发操作降级为串行执行,从而消除对原子性及隔离性的依赖。虽然效率可能会大打折扣,但至少从应用系统的角度有可选的替代方案,例如常见的分布式锁。
持久性是指数据落盘后持续生效不丢失。不过假设原子性、隔离性以及一致性都有充分保障的前提下,持久性也是可以替代的。例如Redis缓存,虽然Redis提供了数据持久化的机制,不过我们大部分场景里都不会依赖于Redis做持久化存储,更多时候只是为了提升灾备恢复效率。因为缓存的数据只是副本,在一致性有保证的前提下,我们可以从数据源完成对缓存数据的复写。数据本身是完整的,我们需要承担的只是复原数据的时间成本。
一致性为什么最重要,是因为从应用层面没有能够保证完全一致性的手段,必须依赖事务的支持。设想一个场景,我们的代码没有任何Bug,所有业务也都按预期进行,但在某个时点数据库突然断电,等重新恢复供电的时候,我们如何让程序能够恢复到断电瞬间的运行状态?假如没有一致性保证,断电后将会产生大量不一致的数据,例如:用户账号已经扣费但订单没有生成、商品显示已经锁定但没有对应订单。对于这类不一致的数据,要从应用层面进行无损失的故障恢复几乎不能实现,因为应用程序的模型是:接收输入 -> 完成逻辑计算 -> 输出结果。如果输入端的数据已经不一致了,那么输出的结果也必然存在不一致,类似物理学里的熵增定律,无序总会在处理过程中被放大。一致性的保证超出了应用程序的设计范围,因此只能通过事务特性来实现。
MySQL如何实现事务一致性
接下来我们以MySQL的Innodb引擎为例,看看MySQL是如何实现事务一致性的。
MySQL里面,所有对数据的增删改查操作并不直接修改磁盘上的数据,而是将数据提取到了位于内存中的缓存池(Buffer Pool),再对缓存池的内容进行修改。这样做避免了频繁读写磁盘导致的性能损耗,是MySQL保持高吞吐率的核心机制。不过由于内存操作无法保证持久性,一旦断电后所有操作中的数据都会丢失。对此MySQL使用了两类日志来应对灾备恢复问题:RedoLog和UndoLog。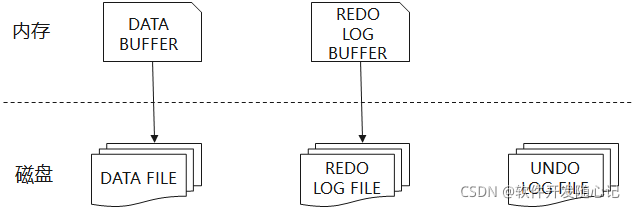
RedoLog是MySQL在对数据页进行修改前需要记录的操作日志,记录此次修改了哪些页面文件,以及修改后的结果;UndoLog与RedoLog相对应,不过它记录的是数据记录修改前的内容,并且它在数据结构上更加接近于表的概念。从功能上看,RedoLog负责保证数据写入的持久化,记录所有前向修改内容;UndoLog负责保证数据的一致性,记录所有修改的反向日志,确保能够通过UndoLog将数据还原到修改前的状态。
MySQL在进行用户数据修改时,始终遵循“日志先行”的规则,即对数据内容真正进行操作前,先保证所有相应的日志已经完成持久化,也就是RedoLog和UndoLog。而RedoLog的存储结构与数据页存储结构类似,也分为RedoLog Buffer和RedoLog File。基于上述的结构,一次完整的事务提交流程如下:
- 开始事务;
- 记录修改数据UndoLog;
- 修改数据缓存页Data Buffer;
- 记录修改数据的RedoLog Buffer;
- 在适当时机将RedoLog Buffer写入RedoLog File;
- 完成事务提交;
- 在适当时机将数据缓存Data Buffer写入磁盘文件Data File;
上述流程中,关键的几个步骤为:
- 执行修改前记录UndoLog;
- 修改数据缓存后记录RedoLog;
- 事务提交前确保RedoLog Buffer写入RedoLog File。
这几个步骤保证了,所有执行成功的数据修改都必然对应一份完整的RedoLog和UndoLog;所有不成功或未提交的事务都有一份完整的UndoLog。因此即使出现断电情况,我们也很容易判断如何根据日志完成数据恢复。
- 场景一:事务已提交,但数据未写入Data File
从CheckPoint开始扫描RedoLog,发现该事务存在提交事务的操作日志,则回放这一段RedoLog日志内容,完成前向恢复; - 场景二:事务未提交
从CheckPoint开始扫描RedoLog,发现事务没有提交步骤日志或存在RollBack情况,则读取UndoLog,完成逆向恢复。
额外提一点有意思的地方。前面提到了UndoLog的数据结构更加接近于表,是MySQL对灾备恢复处理较为巧妙的机制。因为结构与数据表相近,在生成UndoLog的过程中,也会产生修改UndoLog数据页所对应的RedoLog。因此,MySQL灾备恢复的第一阶段始终都是先还原RedoLog,因为刚启动时UndoLog有可能也是不一致的;等所有RedoLog都处理结束后,此时UndoLog也被前向恢复到了故障发生时的状态,从而下一阶段再根据UndoLog完成故障恢复。
分布式事务难点
回顾完事务的基本概念,接下来我们进入分布式事务的内容。
分布式事务也是事务的一种,因此会带有ACID的特性。不过存在的问题是,在复杂的分布式环境下,如何保证ACID同时满足。
首先能想到几个客观存在的难点:
一、网络通讯环境下的不稳定性
分布式事务由于完整的流程分散在不同的业务系统上,而各个业务系统又部署于不同机器设备,因此大部分时候都需要通过网线来进行通讯。我们知道网络协议的目的都是在不可靠的传输介质上实现可靠的数据投递,受传输介质影响,协议所处层级越高为实现可靠性的成本就越大。上述MySQL通过RedoLog/UndoLog实现一致性,是基于单机架构下的物理电路完成信号投递,此时因通讯失败导致事务回滚的情况极少出现,例如断电、硬盘故障、地震、火灾等;而分布式事务基于网络进行通讯,先不说传输速率上的降级,数据链路层、传输层的所有异常,都有可能导致通讯超时、传输失败等。
二、集群规模效应
假设一台机器24小时无故障运行的概率是99.9%,那么四台机器24小时同时无故障运行的概率是99.6%,将其规模扩大到一百台后,其概率只有9%。分布式事务由于跨应用的特性,完整的链路涉及更多的机器参与其中,从而放大了事务过程的故障风险。
三、集群环境下的事务隔离对性能的影响
为了确保一致性,数据库在写入数据时会对操作记录加排他锁,直到事务提交或回滚之前,这个锁都会一直被占有。但在分布式事务环境下,这个特性反而会成为致命的问题。设想程序调用库存接口进行扣减后,下一步调用订单服务进行操作时遇到网络故障导致挂起,那么在这个事务超时退出以前,所有对同商品库存的操作都会阻塞,如果发生在秒杀或者核心业务流程中,造成的损失将无法估量。
SEATA分布式框架
SEATA(Simple Extensible Autonomous Transaction Architecture)是阿里开源的分布式事务解决方案,下面是摘抄自SEATA官网的描述
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。在 Seata 开源之前,Seata 对应的内部版本在阿里经济体内部一直扮演着分布式一致性中间件的角色,帮助经济体平稳的度过历年的双11,对各BU业务进行了有力的支撑。经过多年沉淀与积累,商业化产品先后在阿里云、金融云进行售卖。2019.1 为了打造更加完善的技术生态和普惠技术成果,Seata 正式宣布对外开源,未来 Seata 将以社区共建的形式帮助其技术更加可靠与完备。
SEATA支持四种不同的分布式事务模式,分别是AT、TCC、SAGA、XA模式。关于不同模式之间的差异可以参考之前的分布式事务学习笔记这篇文章,这里主要介绍AT模式,也是SEATA独有的分布式事务机制。
SEATA模型结构
在SEATA框架里共有三类结构对象,分别为事务协调者TC、事务管理器TM、资源管理器RM。
- TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。 - TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。 - RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
实际部署时,TC就是独立的分布式事务控制中心,可独立部署于单台机器,也可架设成为TC集群提高容灾能力;TM是分布式事务的发起者,当一方发起分布式事务时,TM负责完成全局事务的注册、提交以及回滚;RM是分布式事务的参与者,可以理解成微服务里各个独立的应用,当参与者完成本地事务处理并准备提交时,将向TC注册分支事务,并等待最终的全局提交/回滚。
AT模式介绍
相对于TCC、SAGA等模式,AT模式最大的特点是业务无侵入,事务处理对开发人员透明。下面是AT模式下程序发起分布式事务的方式:
@GlobalTransactional
public void purchase(String userId, String commodityCode, int orderCount) {
......
}
只需要在方法头上加@GlobalTransactional注解,即完成了全局事务的启动,后续提交、回滚等操作均对程序透明,只需要按照正常业务逻辑完成后续流程开发,几乎不需要对业务代码做特殊改造。
不过使用上的便利并不意味着底层实现简单,接下来我们看看这个注解背后的实现机制。
AT模式的核心
笔者认为AT模式有三个核心要素:两阶段提交、全局锁以及UndoLog。
两阶段提交
AT模式本质上是两阶段提交(2PC)模型,即准备阶段和提交阶段。
第一阶段(准备阶段):
- TM发起全局事务,并在TC端注册,获取全局事务XID;
- TM通过RPC调用子服务,并传递XID;
- 子服务所在RM执行本地事务,并生成相应UndoLog;
- RM提交本地事务,向TC注册分支事务并上报提交结果;
第二阶段(提交场景):
- RM收到 TC 的分支提交请求,把请求放入异步队列,马上返回提交成功的结果给 TC;
- RM异步删除UNDO LOG记录。
第二阶段(回滚场景):
- RM收到TC分支回滚请求,开启一个本地事务;
- 通过XID和BranchId查找UndoLog;
- 比对UndoLog后镜像与当前数据,如果数据一致,执行下一步;否则根据配置策略进行处理;
- 根据UndoLog前镜像及业务SQL生产回滚语句并执行;
- 提交本地事务,并将本地回滚事务提交结果上报TC;

比较特别的是,AT模式下第一阶段已经完成了分支事务的提交,即各个子服务的数据已完成持久化,此时全局提交时,第二阶段无需进一步处理,仅需清理第一阶段产生的UndoLog即可。而全局回滚时,各个子服务需要通过UndoLog内容再次发起本地事务,将数据还原至全局事务前的状态。
因此AT模式可以理解为:本地事务 + 全局调度。利用各个子服务的本地事务完成数据的写入,同时本地事务提交前向全局注册分支事务,收到全局提交/回滚指令后再判断是否需要还原本次修改。
全局锁
由于AT模式第一阶段已经完成了本地事务提交,因此只要本地事务执行结束后即释放了所有数据库锁。不过根据事务ACID特性,这个时候还需要额外机制保证在 本地事务提交后 -> 全局事务提交 期间,所有事务修改过的数据不能被其他事务修改。对此,这里AT模式使用了全局锁的机制。
这里的全局锁就是指分布式锁,它确保了全局事务的写隔离,以及特定场景下的读隔离。它的机制如下:
写隔离:
- 一阶段本地事务提交前,需要确保先拿到全局锁。
- 拿不到全局锁,不能提交本地事务。
- 拿全局锁的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
读隔离:
- 仅针对Select For Update场景,通过切面代理申请全局锁;
- 默认隔离级别为读未提交(Read Uncommitted)
下面通过SEATA官网的例子了解全局锁的功能。
- 全局事务tx1先执行,它开启本地事务后,首先获取到修改记录的本地锁,并完成数据更新;
- tx1提交本地事务前,先获取修改记录的全局锁,拿到后才完成本地事务提交,释放本地锁;
- 全局事务tx2后执行,同样它也开启本地事务,首先尝试获取同一条记录的本地锁;此时由于tx1已完成本地事务提交,因此tx2本地事务获取锁成功;
- tx2完成数据修改,准备提交本地事务前,也会去尝试获取修改记录的全局锁,不过由于此时全局锁被tx1持有,因此tx2需要等待重试全局锁,直到tx1提交。
全局锁的特性保证了全局事务之间的写隔离,因此不会担心出现脏写问题。上面是正常提交的场景,仔细观察,在tx2提交本地事务的时候存在一个现象:此时tx2持有本地锁并等待全局锁,tx1持有全局锁并等待提交/回滚。那假设tx1后续出现了回滚呢,根据前面2PC的步骤描述,tx1需要再次开启一个本地事务进行数据回滚,但此时本地锁被tx2所占有,于是死锁就发生了。对此SEATA给出的方案是tx1的分支回滚会因拿不到全局锁而一直重试,直到tx2请求全局锁超时后放弃请求并回退本地事务,从而解决死锁。

全局锁的实现机制
全局锁本质上是分布式锁,因此我们可以很直观的对锁的内容进行查阅。在SEATA里事务协调者TC的核心部分由三张表构成:
- global_table:每当有一个全局事务发起后,就会在该表中记录全局事务的ID
- branch_table:记录每一个分支事务的ID,分支事务操作的哪个数据库等信息
- lock_table:记录全局锁,当前持有全局事务ID、分支事务ID、数据库主键
其中lock_table就是全局锁数据表,我们可以通过将SEATA配置文件的store.mode配置为db,即可以通过数据库实时查询当前全局事务相关内容。下面是分布式事务执行过程中对全局事务、分支事务以及全局锁的截图。
全局事务:
分支事务:
全局锁:
可以看到全局锁的核心是记录了当前持有锁的全局事务ID(XID),以及对应RM的数据库主键。
UndoLog
最后,支持AT模式下能够无侵入完成数据回滚的核心机制,就是SEATA的UndoLog。
这里思考一个问题,为什么SEATA不需要RedoLog?因为SEATA不像MySQL一样存在Data Buffer -> Data File的持久化结构,只要本地事务提交成功了,即可以认为分支事务数据已完成持久化,不用考虑如何保证灾备场景下数据正向还原问题,这些都由数据库的本地事务完成了保证。因此SEATA的核心便放在了如何将数据还原到分支事务发生之前,而这里SEATA使用的机制也是UndoLog。
与数据库的UndoLog不同,SEATA在数据库之上额外定义了自己的UndoLog数据格式,这样的好处是避免了不同数据库平台间UndoLog格式不同导致的解析问题,同时也给人为介入提供便利性。
下面是SEATA中UndoLog的表结构定义:
可以看到其结构非常简单,核心内容就在于rollback_info的字段,里面存储的是结构化的JSON字符串,记录了数据修改的前镜像以及后镜像,对应修改前的内容和修改后的内容,如下。
{
"@class":"io.seata.rm.datasource.undo.BranchUndoLog",
"xid":"192.168.0.106:8091:8313831052107195637",
"branchId":8313831052107195639,
"sqlUndoLogs":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.undo.SQLUndoLog",
"sqlType":"UPDATE",
"tableName":"t_storage",
"beforeImage":{
"@class":"io.seata.rm.datasource.sql.struct.TableRecords",
"tableName":"t_storage",
"rows":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Row",
"fields":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"id",
"keyType":"PRIMARY_KEY",
"type":4,
"value":1
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"count",
"keyType":"NULL",
"type":4,
"value":976
}
]
]
}
]
]
},
"afterImage":{
"@class":"io.seata.rm.datasource.sql.struct.TableRecords",
"tableName":"t_storage",
"rows":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Row",
"fields":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"id",
"keyType":"PRIMARY_KEY",
"type":4,
"value":1
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"count",
"keyType":"NULL",
"type":4,
"value":973
}
]
]
}
]
]
}
}
]
]
}
在SEATA里,UndoLog是通过解析业务SQL得来的。当RM处于全局事务中时,将按照以下步骤执行本地事务:
- 拦截DML语句,解析其过滤条件;
- 提取本次操作需要修改的数据主键;
- 保存修改前的数据内容,形成前镜像;
- 执行DML语句,完成数据修改;
- 保存修改后的数据内容,形成后镜像;
- 汇总前镜像与后镜像内容,写入UndoLog;
- 提交本地事务;

利用UndoLog,分支事务可以在全局事务回滚的时候将所有分支事务的修改操作还原到事务开始时的状态。不过这里读者可能已经留意到了,回滚时只需要前镜像就可以完成数据还原,为什么还需要记录数据修改后的后镜像呢?
这是SEATA留的一个数据校验机制,前面提到全局锁的本质是分布式锁,那就会存在一个问题,数据隔离只对了解并遵守分布式锁规则的修改操作生效,如果操作数据的一方不在这个机制内,就无法保证数据隔离性。例如DBA手工修数,这个时候SEATA并不能感知到数据在框架之外被修改了,只有在回滚过程中通过对比当前数据与后镜像内容发现不一致的情况,此时需要人工或事先配置的策略进行特殊处理。与此类似,如果数据库对应的所有业务系统不能都纳入分布式事务框架里,AT模式也将无法保证其一致性,这也一定程度限制了AT模式的使用场景。
SEATA的高可用设计
分布式事务流转的核心是TC,为了防止TC成为架构上的瓶颈,SEATA通过加入事务分组的概念将TC服务流量分流至不同的节点,从而实现高可用支持。具体可见SEATA官网的相关介绍。
总结
SEATA的AT模式做到了非常好的无业务侵入特性,使用简单改造成本也较低,不过即便如此,分布式事务也还未大范围应用。究其原因,笔者认为主要是分布式环境下回滚的成本太高,结果不可控。我们使用事务的核心是为了保证一致性,本地事务由于脱离了应用程序控制范畴,因此无法通过架构设计进行替代。分布式事务较为特殊,其不一致性不在于程序输入与输出,而在不同系统之间的数据不对称,但这种不对称问题是程序框架范围内可以解决的。
根据CAP与BASE理论,分布式系统追求的是最终一致性,保证经过一定时间同步后系统能够最终达到一致状态;而在这之前系统可以是松散的,中间允许一定程度上的不一致状态存在。分布式事务满足了CP特性,但在可用性A上做出了让步,因此并不是所有场景都适用,需要有所取舍。不过如前面所说,如果不让所有关联业务系统都纳入分布式事务框架里,一致性保证又将大打折扣。因此技术没有好坏之分,只有看能不能满足业务场景。
作者:阮伟聪
边栏推荐
猜你喜欢

![行程和用户[阅读理解法]](/img/4b/77bba3c488b5410fdec5c3894c7421.png)
随机推荐
企业公众号开通微信支付
群组行动控制--自动队列化实现策略
RobotFramework 之 用户关键字
opencv-matchTemplate 之使用场景为大图里面找小图
NC15 求二叉树的层序遍历
javscript基础易错点集合
pytest 之 重运行机制与测试报告
eslint语法规则报错
CutefishOS系统默认自动桌面壁纸
Record the system calls and C library functions used in this project-2
易语言获取cookie
Come and throw eggs.
Q_07 词汇表
Q_06_05 文件结构
音视频录入的pts和dts问题
Draw a histogram with plot_hist_numeric()
ArcEngine(九)图形绘制
Spark读取多目录
正则表达式-re模块
FFmpeg长时间无响应的解决方法