当前位置:网站首页>机器学习理论之(8):模型集成 Ensemble Learning
机器学习理论之(8):模型集成 Ensemble Learning
2022-04-23 18:26:00 【暖仔会飞】
文章目录
集成学习的思路
- 通过构造多个基分类器(base classifier)将这些基分类器的分类结果进行集成来得到最终的预测结果

- 模型集成的方法基于下面的直觉:
- 多个模型的总和决策好于单个模型
- 多个弱分类器的结果至少和一个强分类器表现相同
- 多个强分类器的结果至少和一个基分类器表现相同
多个分类器的结果一定好么
- C 1 , C 2 , C 3 C_1,C_2,C_3 C1,C2,C3 分别代表了 3 个基分类器, C ∗ C^* C∗ 表示的是三个分类器的结合的最终结果:

- 实验结果表明集成的结果未必比单个分类器强
什么时候模型集成有效
- 基分类器之间不犯同样的错误
- 每个基分类器都有合理的精度
如何构造基分类器
- 通过训练实例的划分来产生多个不同的基分类器:对样本实例进行多次采样,每次采样生成一个基分类器
- 通过训练实例的特征划分来产生多个不同的基分类器:将特征集合划分成多个子集,通过拥有不同特征子集的样本来训练多个基分类器
- 通过算法调整来产生多个不同的基分类器:给定一个算法,将算法内部的参数进行调整然后根据训练集产生多个不同的基分类器。
如何通过基分类器进行分类
- 通过多个基分类器进行分类的最常用方法是 投票法
- 对于离散的输出结果,可以通过计数的方式来得到最终的分类结果,例如一个二分类的数据集,label=0/1,构造了 5 个基分类器,对于某个样本有三个基分类器的输出结果是 1, 两个是 0 那么这个时候,总和来看结果就应该是 1
- 对于连续型的输出结果,可以将他们的结果进行平均来得到多个基分类器的最终结果
模型的泛化误差
- Bias(偏置):衡量一个分类器进行错误预测的趋势
- Variance(变异度):衡量一个分类器预测结果的偏离程度
- 如果一个模型有更小的 bias 和 variance 就代表这个模型的泛化性能很好。
分类器集成方法
装袋法 Bagging
- 核心思想:更多数据就应该有更好的表现;那么如何通过固定的数据集来产生更多的数据呢?
- 通过随机抽样和替换来产生多个不同的数据集
- 将原始数据集进行有放回的随机采样 N N N 次,得到了 N N N 个数据集,针对这些数据集一共产生 N N N 个不同的基分类器
- 对于这 N N N 个分类器,让他们采用投票法来决定最终的分类结果
- 但是装袋法有个问题,那就是有些样本可能永远不会被用到。因为 N N N 个样本,每个样本每次被取到的概率为 1 N \frac{1}{N} N1 那么一共取 N N N 次没取到的概率为 ( 1 − 1 N ) N (1-\frac{1}{N})^N (1−N1)N 这个值在 N N N 很大的时候的极限值 ≈ 0.37 \approx0.37 ≈0.37
- 装袋法的特点:
- 这是一种基于采样和投票法的集成方法(instance manipulation)
- 多个单独的基分类器可以同步并行进行计算
- 可以有效的克服数据集中的噪声数据
- 通常情况下比单个基分类器的结果好的多,但也存在比单个基分类器效果差的情况
随机森林法 Random Forest
-
随机森林依赖的单个分类器是决策树,但是这个决策树和之前的决策树略有不同
-
在随机森林中使用的单个决策树都只选用一部分特征进行树的建立。也就是说随机森林中的树使用的特征空间不是全部的特征空间
- 例如,采用一个固定的比例 τ \tau τ 来选择每个决策树的特征空间大小
- 随机森林中的每棵树的建立都比一个单独的决策树要简单和快速;但是这种方法增加了模型的 variance
-
随机森林中的每棵树都使用了不同的训练集(using different bagged training dataset)
-
最后通过投票的方法得到最终的结果。

-
这样操作的思想是:尽可能减少任意两棵树之间的关联
-
随机森林的超参数:
- 森林中树的个数 B B B
- 每个特征子集的尺寸,随着尺寸的增加,分类器的能力和相关性都增加了 ( ⌊ l o g 2 ∣ F ∣ + 1 ⌋ \lfloor log_2|F|+1\rfloor ⌊log2∣F∣+1⌋) 因为随机森林中的每棵树使用的特征越多,其与森林中其他树的特征重合度就可能越高,导致产生的随机数相似度越大
- 可解释性:单个实例预测背后的逻辑可以通过多棵随机树共同决定
-
随机森林的特点:
- 随机森林非常强大,可以高效地进行构建
- 可以并行的进行
- 对过拟合有很强的鲁棒性
- 可解释性被牺牲了一部分,因为每个树的特征都是特征集合中随机选取的一部分
演进法 Boosting
-
boosting 方式主要关注困难样本
-
boosting 可将弱学习器提升为强学习器,其运行机制为:
- 从初始训练集训练出一个基学习器;这时候每个样本 instance 的权重都为 1 N \frac{1}{N} N1
- 每个 iteration 都会根据上一轮预测结果调整训练集样本的权重
- 基于调整后的训练集训练一个新的基学习器
- 重复进行,直到基学习器数量达到开始设置的值 T T T
- 将 T T T 个基学习器通过加权的投票方法(weighted voting )进行结合
-
对于boosting方法,有两个问题需要解决:
- 每一轮学习应该如何改变数据的概率分布
- 如何将各个基分类器组合起来


AdaBoost
- adaptive boosting 自适应增强算法;是一种顺序的集成方法(随机森林和 Bagging 都属于并行的集成算法)
- AdaBoost 的基本思想:
- 有 T T T 个基分类器: C 1 , C 2 , . . . , C i , . . . , C T C_1,C_2,...,C_i,...,C_T C1,C2,...,Ci,...,CT
- 训练集表示为 { x j , y j ∣ j = 1 , 2 , . . , N } \{x_j,y_j|j=1,2,..,N\} { xj,yj∣j=1,2,..,N}
- 初始化每个样本的权重都为 1 N \frac{1}{N} N1,即: { w j ( 1 ) = 1 N ∣ j = 1 , 2 , . . . , N } \{w_j^{(1)}=\frac{1}{N}|j=1,2,...,N\} { wj(1)=N1∣j=1,2,...,N}
在每个 iteration i i i 中,都按照下面的步骤进行:
- 计算错误率 error rate ϵ i = Σ j = 1 N w j δ ( C i ( x j ) ≠ y j ) \epsilon_i=\Sigma_{j=1}^Nw_j\delta(C_i(x_j)\neq y_j) ϵi=Σj=1Nwjδ(Ci(xj)=yj)
- δ ( ⋅ ) \delta(\cdot) δ(⋅) 是一个 indicator 函数,当函数的条件满足的时候函数值为 1 1 1;即,当弱分类器 C i C_i Ci 对样本 x j x_j xj 进行分类的时候如果分错了就会累积 w j w_j wj
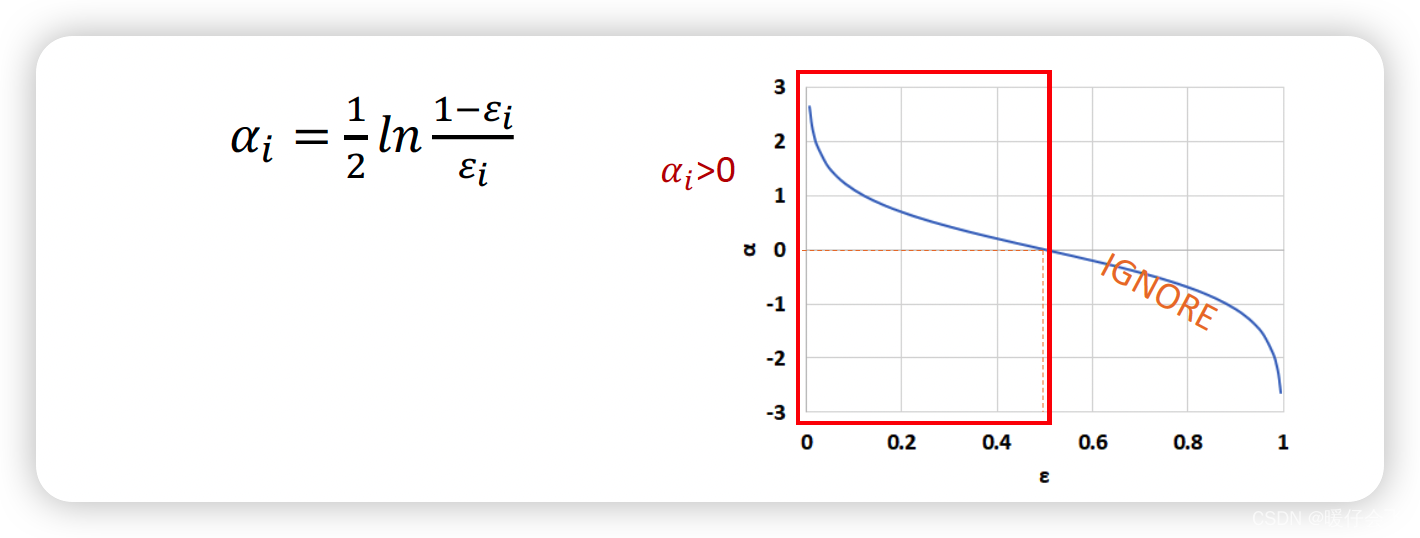
- 使用 ϵ i \epsilon_i ϵi 来计算每个基分类器 C i C_i Ci 的重要程度(给这个基分类器分配权重 α i \alpha_i αi) α i = 1 2 l n 1 − ϵ i ϵ i \alpha_i=\frac{1}{2}ln\frac{1-\epsilon_i}{\epsilon_i} αi=21lnϵi1−ϵi
- 从这个公式也能看出来,当 C i C_i Ci 判断错的样本量越多,得到的 ϵ i \epsilon_i ϵi 就越大,相应的 α i \alpha_i αi 就越小(越接近 0 0 0 )
- 根据 α i \alpha_i αi 来更新 每一个样本的 权重参数,为了第 i + 1 i+1 i+1 个 iteration 做准备:
- 样本 j j j 的权重由 w j ( i ) w_j^{(i)} wj(i) 变成 w j ( i + 1 ) w_j^{(i+1)} wj(i+1) 这个过程中发生的事情是:如果这个样本在第 i i i 个 iteration 中被判断正确了,他的权重就会在原本 w j ( i ) w_j^{(i)} wj(i) 的基础上乘以 e − α i e^{-\alpha_i} e−αi;根据上面的知识 α i > 0 \alpha_i>0 αi>0 因此 − α i < 0 -\alpha_i<0 −αi<0 所以根据公式我们可以知道,那些被分类器预测错误的样本会有一个大的权重;而预测正确的样本则会有更小的权重;
- Z ( i ) Z^{(i)} Z(i) 是一个 normalization 项,为了保证所有的权重相加之和为 1 1 1
- 最终将所有的 C i C_i Ci 按照权重进行集成
- 持续完成从 i = 2 , . . . , T i=2,...,T i=2,...,T 的迭代过程,但是当 ϵ i > 0.5 \epsilon_i>0.5 ϵi>0.5 的时候需要重新初始化样本的权重
最终采用的集成模型进行分类的公式: C ∗ ( x ) = a r g m a x y Σ i = 1 T α i δ ( C i ( x ) = y ) C^*(x)=argmax_y\Sigma_{i=1}^T \alpha_i\delta(C_i(x)=y) C∗(x)=argmaxyΣi=1Tαiδ(Ci(x)=y)
- 这个公式的意思大概是:例如我们现在已经得到了 3 3 3 个基分类器,他们的权重分别是 0.3 , 0.2 , 0.1 0.3, 0.2, 0.1 0.3,0.2,0.1 所以整个集成分类器可以表示为 C ( x ) = Σ i = 1 T α i C i ( x ) = 0.3 C 1 ( x ) + 0.2 C 2 ( x ) + 0.1 C 3 ( x ) C(x)=\Sigma_{i=1}^T \alpha_iC_i(x)=0.3C_1(x)+0.2C_2(x) +0.1C_3(x) C(x)=Σi=1TαiCi(x)=0.3C1(x)+0.2C2(x)+0.1C3(x) 如果类别标签一共只有 0 , 1 0,1 0,1 那就最终的 C ( x ) C(x) C(x) 对于 0 0 0 的值大还是对于 1 1 1 的值大了。
只要每一个基分类器都比随机预测的效果好,那么最终的集成模型就会收敛到一个强很多的模型


- Boosting 集成方法的特点:
- 他的基分类器是决策树或者 OneR 方法
- 数学过程复杂,但是计算的开销较小;整个过程建立在迭代的采样过程和加权的投票(voting)上
- 通过迭代的方式不断的拟合残差信息,最终保证模型的精度
- 比 bagging 方法的计算开销要大一些
- 在实际的应用中,boosting 的方法略有过拟合的倾向(但是不严重)
- 可能是最佳的词分类器(gradient boosting)
Bagging / Random Forest 以及 Boosting 对比

堆叠法 Stacking
- 采用多种算法,这些算法拥有不同的 bias
在基分类器(level-0 model) 的输出上训练一个元分类器(meta-classifier) 也叫 level-1 model
- 了解哪些分类器是可靠的,并组合基分类器的输出
- 使用交叉验证来减少 bias
-
Level-0:基分类器
- 给定一个数据集 ( X , y ) (X,y) (X,y)
- 可以是 SVM, Naive Bayes, DT 等
-
Level-1:集成分类器
- 在 Level-0分类器的基础上构建新的 attributes
- 每个 Level-0 分类器的预测输出都会加入作为新的 attributes;如果有 M M M 个 level-0 分离器最终就会加入 M M M 个 attributes
- 删除或者保持原本的数据 X X X
- 考虑其他可用的数据(NB 概率分数,SVM 权重)
- 训练 meta-classifier 来做最终的预测
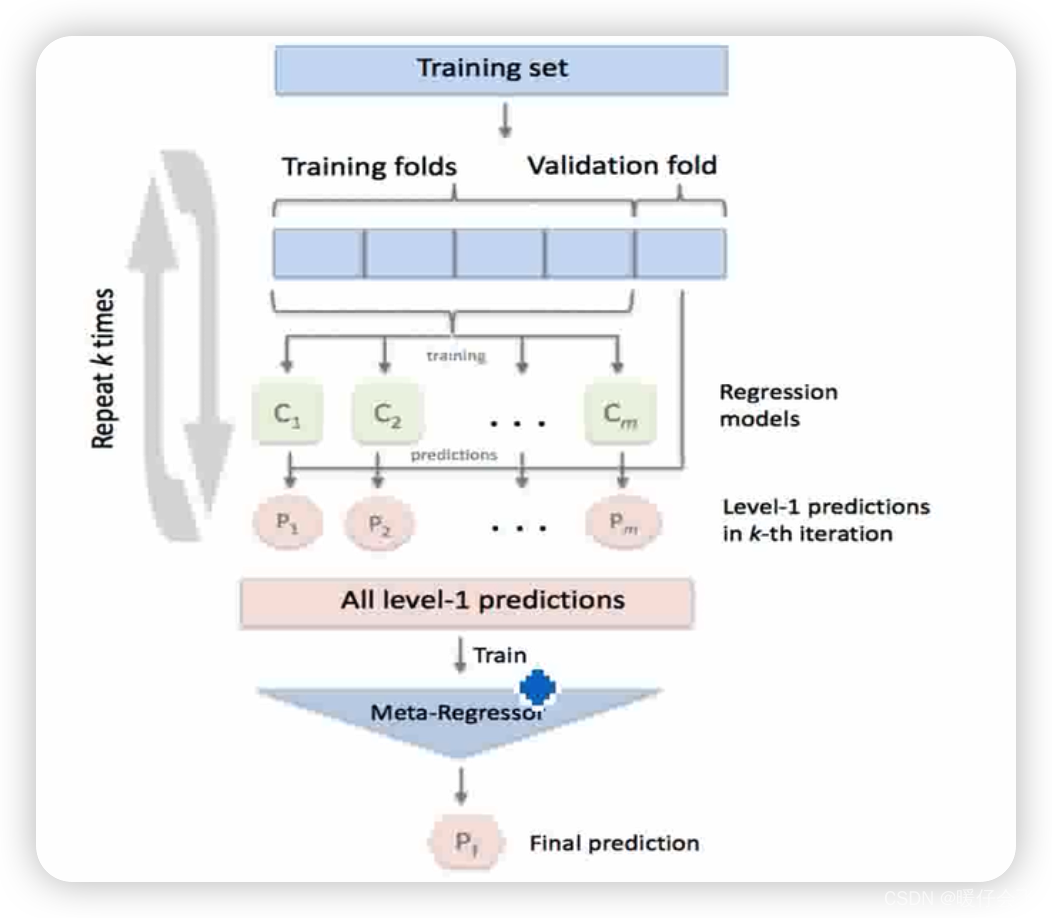
可视化这个 stacking 这个过程
- 首先将原本的数据分成训练集和验证集,例如这里 4 份用于训练,1 份用于测试
- 将这些用于训练的数据 ( X t r a i n , y t r a i n ) (X_{train},y_{train}) (Xtrain,ytrain) 来训练 m m m 个基分类器 C 1 , . . . , C m C_1,...,C_m C1,...,Cm,每个基分类器对测试集数据 ( X t e s t , y t e s t ) (X_{test},y_{test}) (Xtest,ytest) 进行 predict 得到预测结果 P 1 , . . . , P m P_1,...,P_m P1,...,Pm,然后将这些预测的结果和原本测试机的标签 y t e s t y_{test} ytest 构成新的训练集 ( X n e w , y t e s t ) (X_{new},y_{test}) (Xnew,ytest),其中 X n e w = { P 1 , . . . , P m } X_{new}=\{P_1,...,P_m\} Xnew={ P1,...,Pm}来训练 level-1 的集成模型。
- stacking 方法的特点:
- 结合多种不同的分类器
- 数学表达简单,但是实际操作耗费计算资源
- 通常与基分类器相比,stacking 的结果一般好于最好的基分类器
版权声明
本文为[暖仔会飞]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_42902997/article/details/124350440
边栏推荐
- Daily CISSP certification common mistakes (April 13, 2022)
- Use of regular expressions in QT
- Refcell in rust
- Crawl lottery data
- Daily CISSP certification common mistakes (April 12, 2022)
- How to ensure the security of futures accounts online?
- Docker installation MySQL
- 【ACM】376. 摆动序列
- Nodejs installation
- Rust: how to match a string?
猜你喜欢
JD-FreeFuck 京东薅羊毛控制面板 后台命令执行漏洞
硬核解析Promise對象(這七個必會的常用API和七個關鍵問題你都了解嗎?)
Halo open source project learning (VII): caching mechanism

idea中安装YapiUpload 插件将api接口上传到yapi文档上
Install the yapiupload plug-in in idea and upload the API interface to the Yapi document
Robocode tutorial 7 - Radar locking
【ACM】509. 斐波那契数(dp五部曲)
【ACM】455. 分发饼干(1. 大饼干优先喂给大胃口;2. 遍历两个数组可以只用一个for循环(用下标索引--来遍历另一个数组))

Docker 安装 MySQL

In win10 system, all programs run as administrator by default
随机推荐
STM32 learning record 0008 - GPIO things 1
使用 bitnami/postgresql-repmgr 镜像快速设置 PostgreSQL HA
JD-FreeFuck 京東薅羊毛控制面板 後臺命令執行漏洞
RC smart pointer in rust
From introduction to mastery of MATLAB (2)
Multifunctional toolbox wechat applet source code
Analysez l'objet promise avec le noyau dur (Connaissez - vous les sept API communes obligatoires et les sept questions clés?)
In win10 system, all programs run as administrator by default
Introduction to QT programming
Robocode Tutorial 4 - robocode's game physics
函数递归以及趣味问题的解决
Spark performance optimization guide
Rust: how to implement a thread pool?
Notepad + + replaces tabs with spaces
Nodejs安装
Nodejs installation
idea中安装YapiUpload 插件将api接口上传到yapi文档上
Solution to Chinese garbled code after reg file is imported into the registry
Gobang game based on pyGame Library
In shell programming, the shell file with relative path is referenced