当前位置:网站首页>修改ddt生成的测试用例名称
修改ddt生成的测试用例名称
2022-04-23 14:02:00 【沉觞流年】
修改ddt生成的测试用例名称
修改ddt生成的测试用例名称,首先得了解ddt生成的测试用例名称的逻辑

ddt生成的测试用例名称的逻辑
以该篇文章进行举例:DDT+Excel进行接口测试

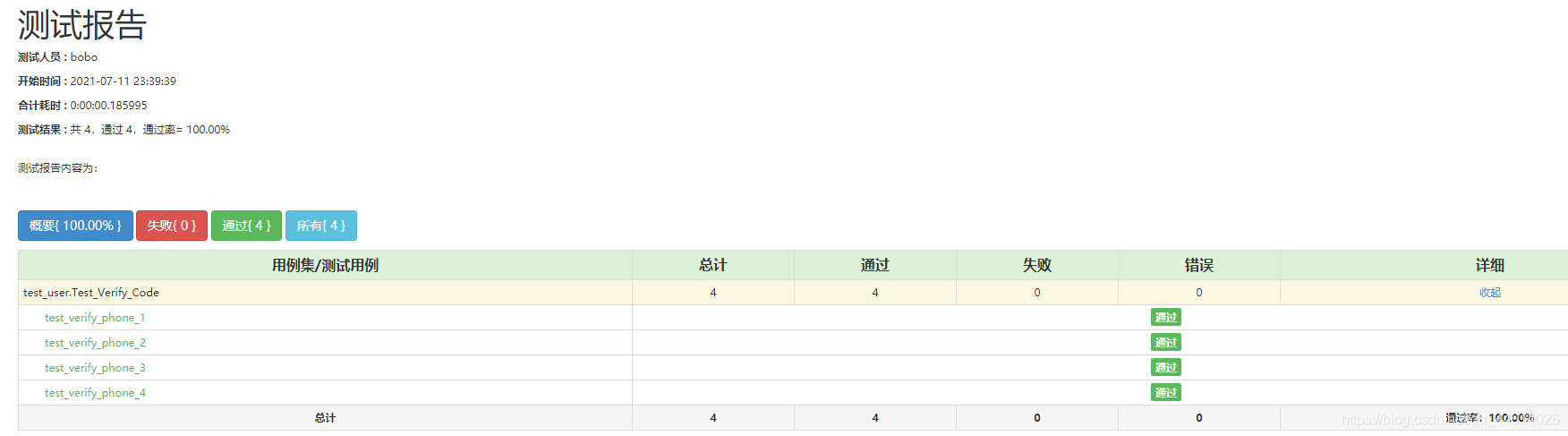
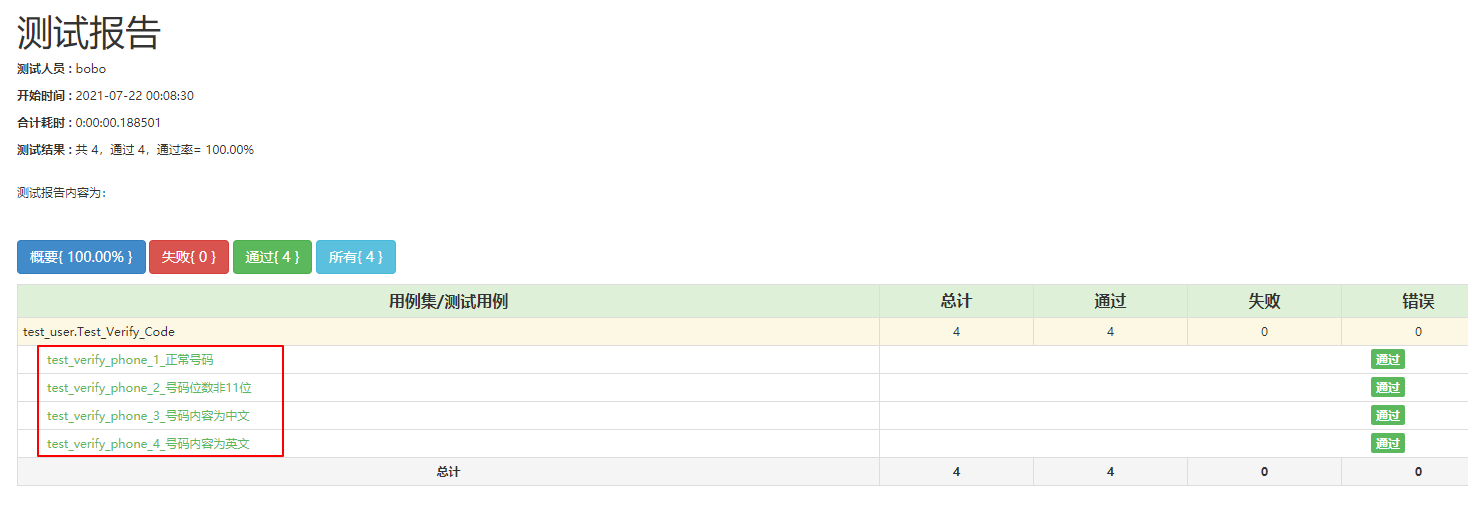
通过ddt验证多组数据测试场景时,生成的测试报告,会根据测试用例的名称test_verify_phone,自动在测试用例名称后加上数字,如test_verify_phone_1、test_verify_phone_2…
这些数字与测试数据的一一对应
测试用例py文件
@ddt.ddt
class Test_Verify_Code(unittest.TestCase):
def setUp(self) -> None:
pass
def tearDown(self) -> None:
pass
@ddt.data(*test_data)
def test_verify_phone(self,test_data):
res = HTTPHandler().visit(test_data["url"],test_data["method"],json=test_data["phonenum"])
self.assertEqual(res["code"],test_data["excepted"])
将鼠标光标移至 @ddt.data(*test_data) 的 data 处,按住Ctrl,点击 data 处,查看源码内容
获取测试数据的数量
源码文件
def data(*values):
""" Method decorator to add to your test methods. Should be added to methods of instances of ``unittest.TestCase``. """
global index_len
index_len = len(str(len(values)))
return idata(values)
有一个 data函数,通过获取测试数据的长度(数量),获取测试数据的数量。
在 index_len = len(str(len(values)))这一行打上断点,然后通过DEBUG的方式,执行测试用例py文件
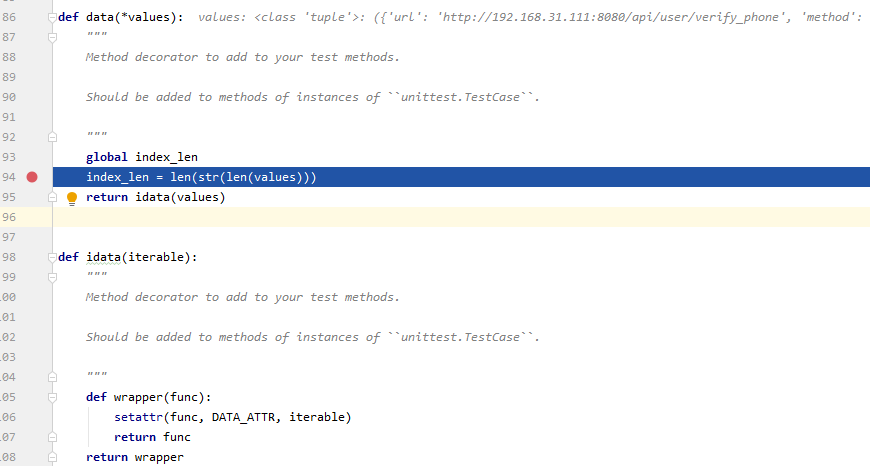
这里的values,其实就是测试数据,这是一个tuple元组类型的数据,里面有4条dict字典类型的数据
当然,起作用的,主要是下面的一个idata函数
这个函数的作用,是生成测试用例的个数,通过ddt验证了多少组数据,就会有多少个测试用例
这是一个返回函数,这个函数就比较有意思了,内容很丰富,具体的逻辑,不深究了,如果有兴趣,可以在关键步骤继续打断点,一步步调试,查看数据走向
生成测试用例名称
源码文件
def mk_test_name(name, value, index=0, name_fmt=TestNameFormat.DEFAULT):
index = "{0:0{1}}".format(index + 1, index_len)
if name_fmt is TestNameFormat.INDEX_ONLY or not is_trivial(value):
return "{0}_{1}".format(name, index)
try:
value = str(value)
except UnicodeEncodeError:
# fallback for python2
value = value.encode('ascii', 'backslashreplace')
test_name = "{0}_{1}_{2}".format(name, index, value)
return re.sub(r'\W|^(?=\d)', '_', test_name)
有一个 mk_test_name函数,该函数的作用是:通过ddt验证多组数据测试场景时生成对应的测试用例名称。
index=0,最开始的时候为0;index + 1,进行 +1处理;
"test_name ={0}_{1}".format(name, index),这行明确说明了返回的测试用例名称的格式。如果有兴趣,也可以在这行打一个断点,DEBUG调试一下
ddt生成的测试用例名称
回到测试用例文件,将鼠标光标移至 @ddt.ddt处,按住Ctrl,点击第二个 ddt 处,查看源码内容
源码文件
def ddt(arg=None, **kwargs):
fmt_test_name = kwargs.get("testNameFormat", TestNameFormat.DEFAULT)
def wrapper(cls):
for name, func in list(cls.__dict__.items()):
if hasattr(func, DATA_ATTR):
for i, v in enumerate(getattr(func, DATA_ATTR)):
test_name = mk_test_name(name,getattr(v, "__name__", v),i,fmt_test_name)
test_data_docstring = _get_test_data_docstring(func, v)
if hasattr(func, UNPACK_ATTR):
if isinstance(v, tuple) or isinstance(v, list):
add_test(cls,test_name,test_data_docstring,func,*v)
else:
# unpack dictionary
add_test(cls,test_name,test_data_docstring,func,**v)
else:
add_test(cls, test_name, test_data_docstring, func, v)
delattr(cls, name)
elif hasattr(func, FILE_ATTR):
file_attr = getattr(func, FILE_ATTR)
process_file_data(cls, name, func, file_attr)
delattr(cls, name)
return cls
这块就是最关键的部分了
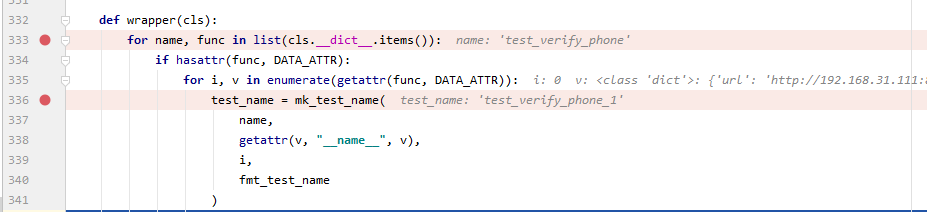
在这两行打断点,一步步进行调试,可以发现 name 在这里,其实就是测试用例的名称test_verify_phone,test_name 这里调用了mk_test_name 函数,所以,在 test_verify_phone后加上了数字,这时候 test_name = test_verify_phone_1
ddt生成的测试用例名称的逻辑,就是如此了。所以通过ddt验证的测试场景,在测试用例名称后都会加上对应的数字。
修改ddt生成的测试用例名称
然而,这种情况,有些时候,并不知道这个测试用例对应的是哪个测试场景。
假设这时候,领导说看日志很麻烦,要你把这个测试报告里的内容描述清楚,他想知道哪个场景是通过的,哪个是没有通过的,让你把测试用例的标题改一下,这一个测试用例是测什么场景的,要让他能一眼就能看懂。

虽然心里把他骂了几十遍,但最终你还是得按他的要求完成

在上面的调试过程中,可以发现 v 这个变量,指的是每一组测试数据的内容,所以,只需要在每组测试数据里,加上描述的内容,然后再拼接到生成的测试用例名称上就行了
从excel读取的数据,一般以字典或列表的形式进行存储。
判断一下,如果测试数据是 list列表类型,则取这个列表里的第一个元素的内容;如果测试数据是 dict字典类型,则取这个字典里case_name的值
所以,修改ddt生成的测试用例名称,并不难
在 test_name = mk_test_name(name,getattr(v, "__name__", v),i,fmt_test_name)后面加上几行代码就行了
if isinstance(v, list):
test_name = mk_test_name(name, v[0], i)
elif isinstance(v, dict):
test_name = mk_test_name(name, v['case_name'], i)
当然,我们还可以再严谨一点,如果读取的数据,都不是字典、列表的类型,这时候抛出异常,但又不影响原来ddt的功能,可以这样修改:
def ddt(arg=None, **kwargs):
fmt_test_name = kwargs.get("testNameFormat", TestNameFormat.DEFAULT)
def wrapper(cls):
for name, func in list(cls.__dict__.items()):
if hasattr(func, DATA_ATTR):
for i, v in enumerate(getattr(func, DATA_ATTR)):
try:
if isinstance(v, list):
test_name = mk_test_name(name, v[0], i)
elif isinstance(v, dict):
test_name = mk_test_name(name, v['case_name'], i)
except Exception as e:
test_name = mk_test_name(name,getattr(v, "__name__", v),i,fmt_test_name)
logging.exception(e)
test_data_docstring = _get_test_data_docstring(func, v)
if hasattr(func, UNPACK_ATTR):
if isinstance(v, tuple) or isinstance(v, list):
add_test(cls,test_name,test_data_docstring,func,*v)
else:
# unpack dictionary
add_test(cls,test_name,test_data_docstring,func,**v)
else:
add_test(cls, test_name, test_data_docstring, func, v)
delattr(cls, name)
elif hasattr(func, FILE_ATTR):
file_attr = getattr(func, FILE_ATTR)
process_file_data(cls, name, func, file_attr)
delattr(cls, name)
return cls
不推荐在 ddt这个py文件里直接改源码,如果这样直接修改了,会造成 ddt 只符合这一个测试用例的场景,如果其他的测试用例数据内容不是这样的,可能就会产生报错
找到ddt这个py文件所在的目录(一般都在 python环境变量下的 site-packages 目录下),将其复制一份,放到项目路径下的 Common目录下,然后对Common目录下ddt.py文件进行修改
在测试用例py文件下,修改ddt的导入方式 :from Common import ddt 这样,使用的ddt功能,就是符合个测试用例场景的功能了
生成报告
版权声明
本文为[沉觞流年]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_44614026/article/details/118878105
边栏推荐
猜你喜欢
Elmo (bilstm-crf + Elmo) (conll-2003 named entity recognition NER)
基於CM管理的CDH集群集成Phoenix
JDBC入门
UML Unified Modeling Language
基于Ocelot的gRpc网关
crontab定时任务输出产生大量邮件耗尽文件系统inode问题处理

Lin Lin, product manager of Lenovo: network failure of local network operator in Tianjin. The background server of Zui system can't work normally for the time being
程序编译调试学习记录
visio安装报错 1:1935 2:{XXXXXXXX...

3300万IOPS、39微秒延迟、碳足迹认证,谁在认真搞事情?
随机推荐
浅谈基于openssl的多级证书,Multi-level CA的签发和管理,以及双向认证
How does redis solve the problems of cache avalanche, cache breakdown and cache penetration
Android: answers to the recruitment and interview of intermediate Android Development Agency in early 2019 (medium)
PATH环境变量
力扣刷题 101. 对称二叉树
smart-doc + torna生成接口文档
Quartus prime hardware experimental development (de2-115 board) experiment 1 CPU instruction calculator design
收藏博客贴
Atcoder beginer contest 248c dice sum (generating function)
Decimal 格式化小数位/DateTime 转换处理
可否把模板的头文件和源文件分开编译
websocket
JS 力扣刷题 102. 二叉树的层序遍历
Go语言 RPC通讯
微信小程序进行蓝牙初始化、搜索附近蓝牙设备及连接指定蓝牙(一)
Oracle告警日志alert.log和跟踪trace文件中文乱码显示
[code analysis (7)] communication efficient learning of deep networks from decentralized data
crontab定时任务输出产生大量邮件耗尽文件系统inode问题处理
程序编译调试学习记录
Spark入门基本操作