当前位置:网站首页>Flink CDC介绍和个人理解
Flink CDC介绍和个人理解
2022-08-10 03:29:00 【bigdata王一】
简介
CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
种类
基于查询和基于binlog
基于日志的 CDC 方案介绍
从 ETL 的角度进行分析,一般采集的都是业务库数据,这里使用 MySQL 作为需要采集的数据库,通过 Debezium 把 MySQL Binlog 进行采集后发送至 Kafka 消息队列,然后对接一些实时计算引擎或者 APP 进行消费后把数据传输入 OLAP 系统或者其他存储介质。
Flink 希望打通更多数据源,发挥完整的计算能力。我们生产中主要来源于业务日志和数据库日志,Flink 在业务日志的支持上已经非常完善,但是在数据库日志支持方面在 Flink 1.11 前还属于一片空白,这就是为什么要集成 CDC 的原因之一。
Flink SQL 内部支持了完整的 changelog 机制,所以 Flink 对接 CDC 数据只需要把CDC 数据转换成 Flink 认识的数据,所以在 Flink 1.11 里面重构了 TableSource 接口,以便更好支持和集成 CDC。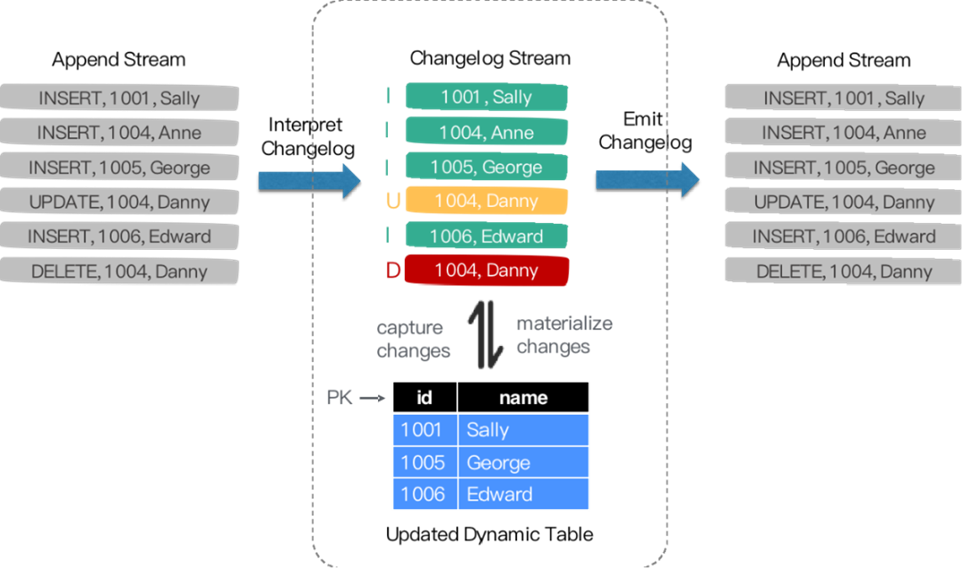

重构后的 TableSource 输出的都是 RowData 数据结构,代表了一行的数据。在RowData 上面会有一个元数据的信息,我们称为 RowKind 。RowKind 里面包括了插入、更新前、更新后、删除,这样和数据库里面的 binlog 概念十分类似。通过 Debezium 采集的 JSON 格式,包含了旧数据和新数据行以及原数据信息,op 的 u表示是 update 更新操作标识符,ts_ms 表示同步的时间戳。因此,对接 Debezium JSON 的数据,其实就是将这种原始的 JSON 数据转换成 Flink 认识的 RowData。
flink作为etl工具
原工作原理
优化后
Flink SQL 采集+计算+传输(ETL)一体化优点:
开箱即用,简单易上手
减少维护的组件,简化实时链路,减轻部署成本
减小端到端延迟
Flink 自身支持 Exactly Once 的读取和计算
数据不落地,减少存储成本
支持全量和增量流式读取
binlog 采集位点可回溯
应用场景
实时数据同步,数据备份,数据迁移,数仓构建
优势:丰富的上下游(E & L),强大的计算(T),易用的 API(SQL),流式计算低延迟
数据库之上的实时物化视图、流式数据分析
索引构建和实时维护
业务 cache 刷新
审计跟踪
微服务的解耦,读写分离
基于 CDC 的维表关联
开源地址
https://github.com/ververica/flink-cdc-connectors
最新flink cdc官方文档分享
https://flink-learning.org.cn/article/detail/eed4549f80e80cc30c69c406cb08b59a
流程图
个人理解作图
1.X痛点
 所以设计目标
所以设计目标
设计实现上:
在对于有主键的表做初始化模式,整体的流程主要分为5个阶段:
1.Chunk切分;2.Chunk分配;(实现并行读取数据&CheckPoint)
3.Chunk读取;(实现无锁读取)
4.Chunk汇报;
5.Chunk分配。
对于并发线程
会对比各个读取切分的最高和最低的位置区间,超过区间进行更新
目前支持开发方式
个人理解作图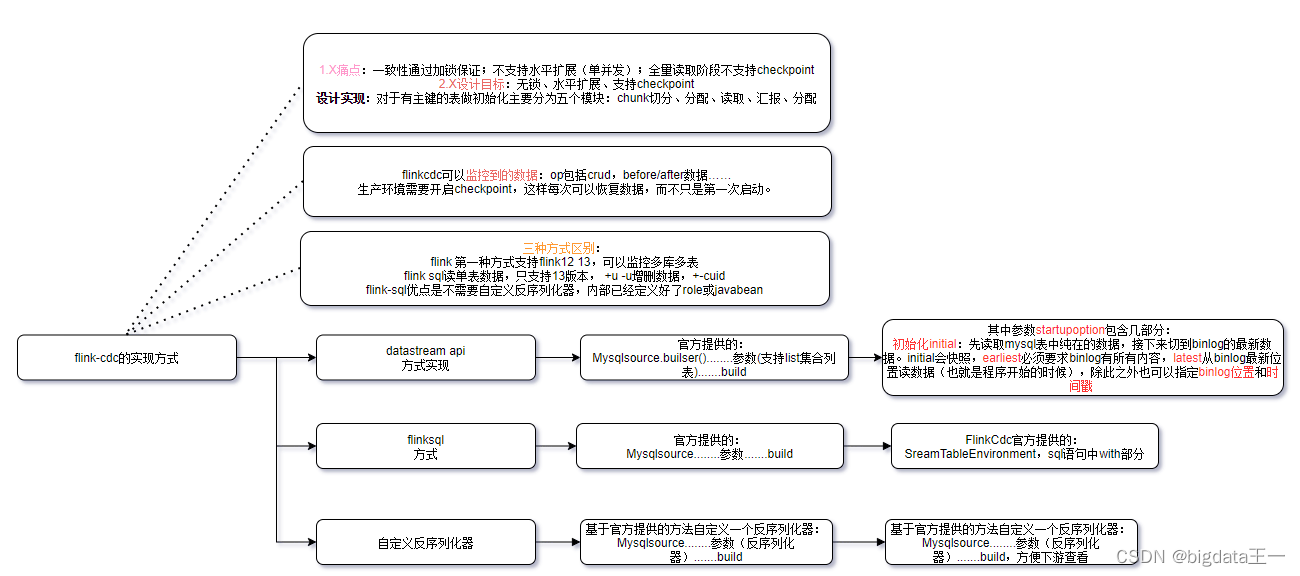
开发测试大致流程
个人理解作图
边栏推荐
猜你喜欢
js原型和原型链以及原型继承

Do you know these basic types of software testing?
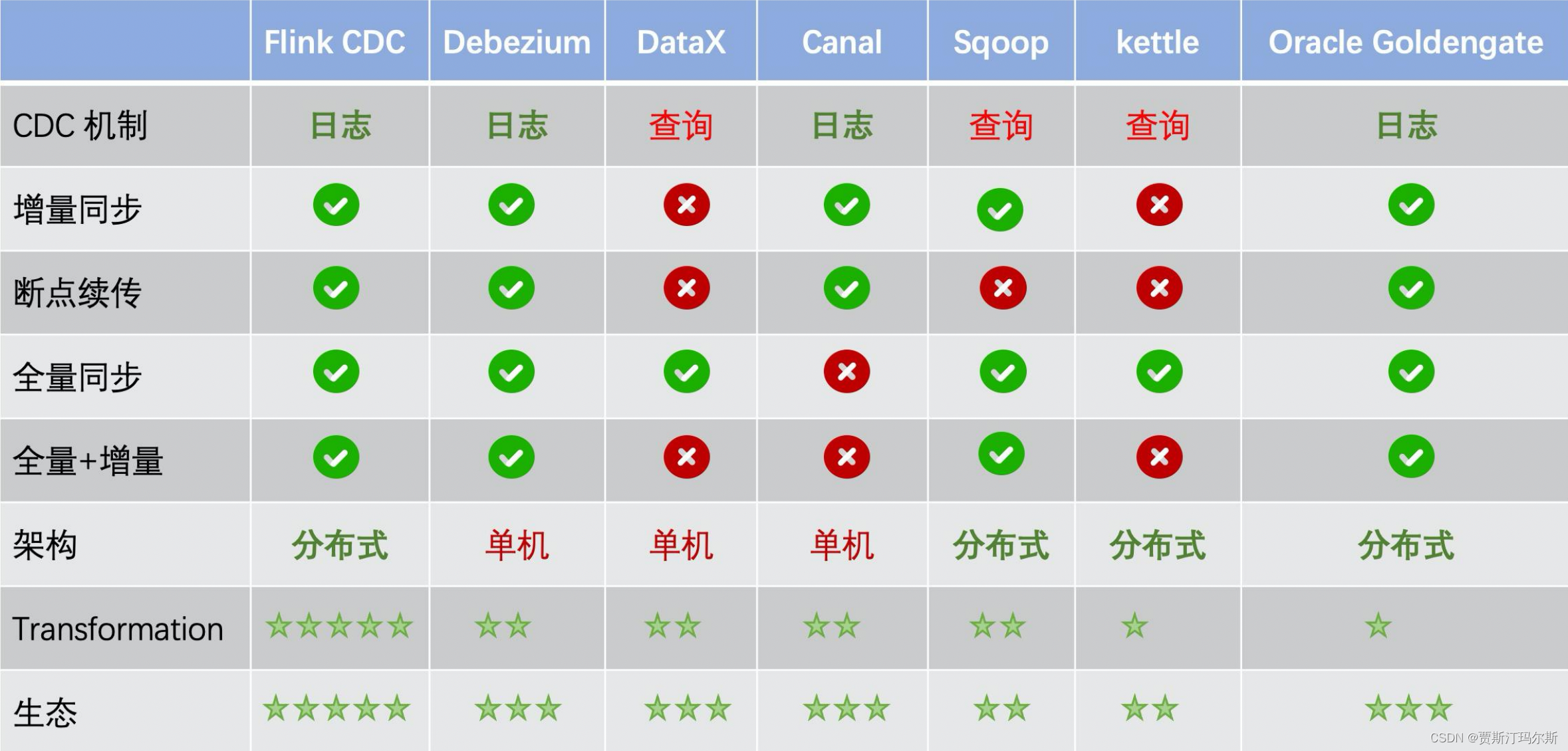
Flink CDC 2.0及其他数据同步工具对比
Dynamic Web Development Fundamentals
Software life cycle (the work of each phase of software engineering)

【mindspore】【Categorical】softmax数据放入Categorical类出现和不为1的错误

一个刚入行的测试员怎么样做好功能测试?测试思维真的很重要

goland console shows overlapping problem solution
zabbix添加监控主机和自定义监控项
c语言进阶篇:动态内存管理(相关函数、常见错误、笔试题)
随机推荐
golang:base64编解码(转)
国能准能集团研发矿山数字孪生系统 填补国内采矿行业空白
goland console shows overlapping problem solution
TCP协议之《MTU探测功能》
leetcode-218.天际线问题
什么是Jmeter?Jmeter使用的原理步骤是什么?
Take you to an in-depth understanding of the version update of 3.4.2, what does it bring to users?
学习总结week4_1json
模型部署ONNX学习
测试工作管理与规范
shell三剑客之sed命令
Pytorch中的torch.index_select对应MindSpore哪个方法
转:不忧、不惧——成功领导者的自我成长和实现
uniapp 路由与页面跳转
Flink Table&Sql API使用遇到的问题总结
TCP协议之《ACK状态4种详解》
The so-called software testing ability is actually these 5 points
Difference between netstat and ss command
Basic understanding of network models
uva1481