当前位置:网站首页>Advantages, disadvantages and selection of activation function
Advantages, disadvantages and selection of activation function
2022-04-23 15:27:00 【moletop】
Activation function :
-
significance : Increase the nonlinear modeling ability of the network , If there is no activation function , Then the network can only express linear mapping , Even if there are more hidden layers , The whole network is also equivalent to the single-layer neural network
-
Characteristics required :1. Continuous derivable .2, As simple as possible , Improve network computing efficiency .3, The value range is in the appropriate range , Otherwise, it will affect the training efficiency and stability .
-
Saturation activation function :Sigmoid、Tanh. Unsaturated activation function :ReLu. And the output layer ( classifier ) Of softmax
-
The choice of activation function : In the hidden layer ReLu>Tanh>Sigmoid .RNN in :Tanh,Sigmoid. Output layer :softmax( Classification task ). Neuronal death occurs , It can be used PRelu.
1**.Sigmoid**:
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-yx52Vtvu-1649727884516)(D:\Download\picture666-master\img/20220319224913.png)]](/img/79/06a8bafd6694a03023a3532ca3980c.png)
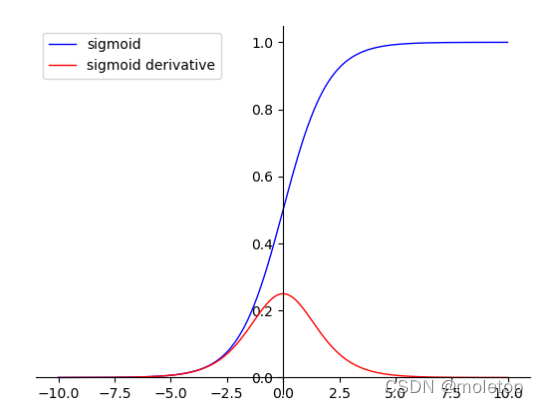
advantage :<1> Sigmoid The value range of is (0, 1), Coincidence probability , And monotonically increasing , Easier to optimize .
<2> Sigmoid Derivation is easier , It can be directly deduced that .
shortcoming :
<1> Sigmoid The function converges slowly .
<2> because Sigmoid It's soft saturation , It's easy to produce gradients that disappear , It is not suitable for deep network training, which is easy to cause the gradient to disappear .
<3> Sigmoid The function is not in the form of (0,0) For the center , Ring breaking data distribution .
2.Tanh function
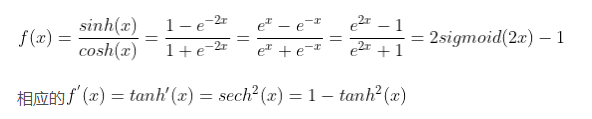
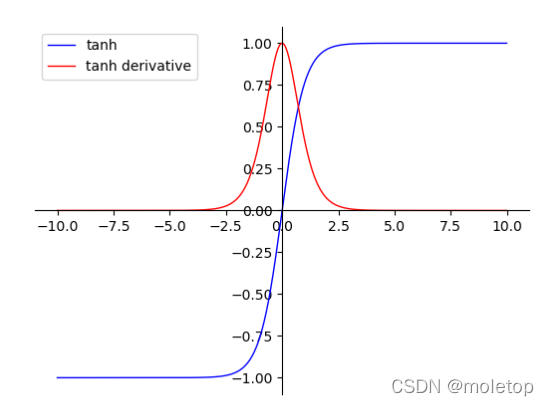
advantage :<1> The function outputs in (0,0) Centered .shortcoming :<1> tanh There is no solution sigmoid The problem of gradient disappearance .
3.ReLU function
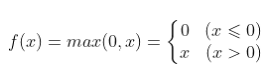
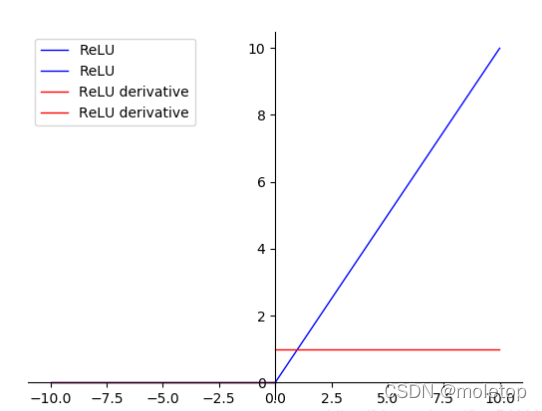
advantage :<1> stay SGD The convergence rate is faster than Sigmoid and tanh Much faster
<2> It effectively alleviates the problem of gradient disappearance .
shortcoming :
<1> Neuron disappointment is easy to appear in the process of training ( Negative half axis ), Then the gradient is always 0 The situation of , Cause irreversible death .
<2> The derivative is 1, Alleviate the problem of gradient disappearance , But it's easy to explode .
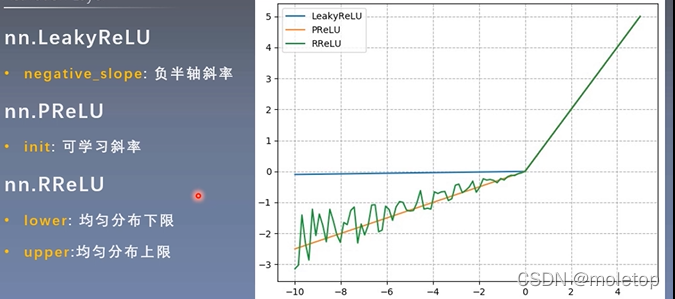
4.ReLu improvement
版权声明
本文为[moletop]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231523160750.html
边栏推荐
- SSH connects to the remote host through the springboard machine
- Mysql连接查询详解
- JS -- realize click Copy function
- Explanation 2 of redis database (redis high availability, persistence and performance management)
- Tun model of flannel principle
- X509 certificate cer format to PEM format
- 控制结构(一)
- G007-HWY-CC-ESTOR-03 华为 Dorado V6 存储仿真器搭建
- Mysql database explanation (VII)
- 机器学习——逻辑回归
猜你喜欢
Openstack theoretical knowledge
How to design a good API interface?
Mysql连接查询详解
UML learning_ Day2
Reptile exercises (1)
Basic operation of circular queue (Experiment)

My raspberry PI zero 2W toss notes to record some problems and solutions

群体智能自主作业智慧农场项目启动及实施方案论证会议
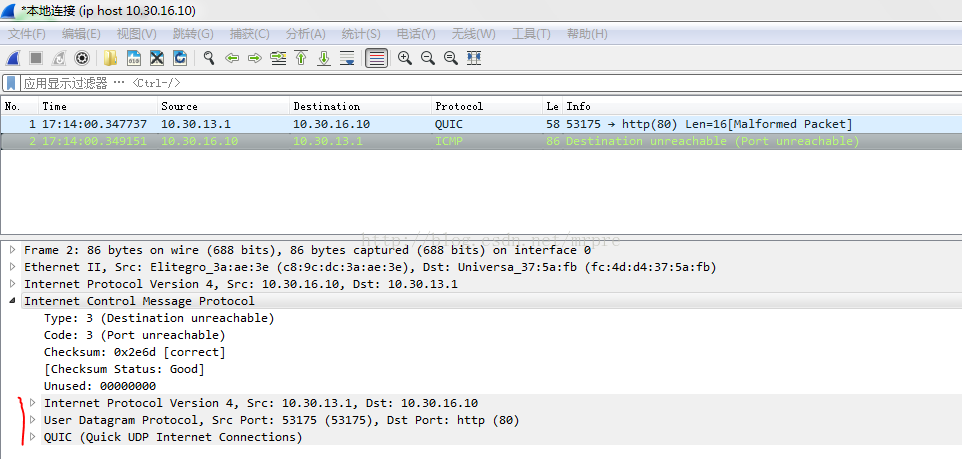
About UDP receiving ICMP port unreachable
Machine learning - logistic regression
随机推荐
控制结构(一)
Detailed explanation of MySQL connection query
X509 certificate cer format to PEM format
Compiling OpenSSL
Mysql database explanation (10)
Llvm - generate local variables
Educational codeforces round 127 A-E problem solution
Mysql database explanation (IX)
Detailed explanation of C language knowledge points -- first understanding of C language [1] - vs2022 debugging skills and code practice [1]
移动app软件测试工具有哪些?第三方软件测评小编分享
Connectez PHP à MySQL via aodbc
Kubernetes详解(九)——资源配置清单创建Pod实战
Explanation 2 of redis database (redis high availability, persistence and performance management)
PHP 的运算符
T2 icloud calendar cannot be synchronized
My raspberry PI zero 2W tossing notes record some problems encountered and solutions
MySQL InnoDB transaction
Common interview questions of operating system:
php函数
调度系统使用注意事项