当前位置:网站首页>Yolov4 pruning [with code]
Yolov4 pruning [with code]
2022-04-23 17:56:00 【Meat loving Peng】
This project is only responsible for building the framework , Where the training should be done or where the training should be fine tuned , I need to study myself
YOLOv4 Code reference :Pytorch Build your own YoloV4 Target detection platform (Bubbliiiing Deep learning course )_ Bili, Bili _bilibili
Paper:Pruning Filters for Efficient ConvNets
There are a lot of text , Please be patient with reading 【 Of course, you can also use code directly 】
Catalog
Instantiation of the model ( For the trained model )
For non monolayer convolution channel pruning ( Don't look 3.1)
Before pruning, count the parameters of the model
1. setup strategy (L1 Norm) Calculate the weight of each channel
2. Build dependency graph ( And torch.jit It's like )
3. Sub situation (1. Single convolution for pruning 2. Layer for pruning )
For single-layer pruning, the main steps are as follows [ I'm afraid there is a gap in my translation , So you can translate and understand ]:
1. For each filter  , calculate the sum of its absolute kernel weights
, calculate the sum of its absolute kernel weights  .
.
2. Sort the filters by  .
.
3. Prune m filters with the smallest sum values and their corresponding feature maps. The kernels in the next convolutional layer corresponding to the pruned feature maps are also removed.
4. A new kernel matrix is created for both the ith and i + 1th layers, and the remaining kernel weights are copied to the new model.
Generally speaking, for the filter you want to cut ( It's convolution ), Calculate the sum of the absolute values of the weights of each channel , Namely L1, Sort the calculation results , Then use a minimum value ( It can be understood as a threshold ) Of the characteristic layers associated with these convolution kernels m A channel for pruning , After pruning, a new convolution kernel will be generated , Assign the weight that has not been cut in the original convolution kernel to the new convolution kernel .
For example, your input feature layer Xi The size is hi,wi,c,c Number of channels . The number of input channels of convolution kernel is ni, This ni=c, The number of output channels is ni+1, Now you're going to ni+1 Cut off a passage at ( The blue part of the picture ), We know , When convolution , How many channels are output , So the next feature graph Xi+1 Accordingly, the same number of feature layers will be obtained , Now we remove a channel , So the corresponding , The number of feature layer channels will also be reduced ( namely Xi+1 The medium blue part will be removed ). Then the number of input channels for the next convolution ni+1 I'll be with you again Xi+1 The number of channels is the same , Therefore, the convolution kernel will also reduce the corresponding channel dimension . Prune a convolution , Then it will affect the dimensional change of the next convolution .
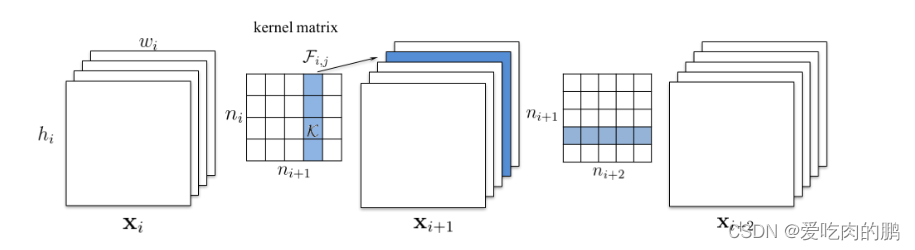
Single layer pruning
Multi layer pruning ( Two strategies ):
• Independent pruning determines which filters should be pruned at each layer independent of other layers.
• Greedy pruning accounts for the filters that have been removed in the previous layers. This strategy does not consider the kernels for the previously pruned feature maps while calculating the sum of absolute weights.
1. Independent pruning : Filter for each layer ( Convolution kernel ) Decide whether to prune Independent of other layers
2. Greedy pruning : consider Previous layer Filter removed from . When pruning and calculating the sum of absolute values of weights , There is no need to consider the kernel corresponding to the previously pruned characteristic graph
about Strategy 1 Independent pruning , The green part of the core is when calculating the sum of the absolute values of the output channels , This dimension of the previously removed feature layer is not considered ( The blue part ), That is, only consider the sum of the green channels ( Personal understanding here : The blue line is directly removed in single-layer pruning , That is, the yellow part in the picture is gone , But in multiple layers of independent pruning , stay ni+2 Remove only the blue area in the direction , But keep the yellow part ), Therefore, the weight of the yellow area in the core remains !
In the strategy 2 In the greedy pruning of , Do not count the channels to be cut off in the feature layer [ That is, consider the removed from the previous layer ]【 Personal understanding , That's why we don't consider the yellow part 】【 You can translate and understand :The greedy pruning strategy does not count kernels for the already pruned feature maps.】
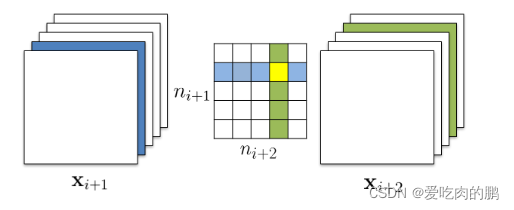
Multi layer pruning
Environmental Science :
The graphics card : Ying Wei Da 1650
pytorch 1.7.0( The lower version should also be possible )
torchvision 0.8.0
torch_pruning
install
pip install torch_pruning
Import package
import torch_pruning as tp
Instantiation of the model ( For the trained model )
model = torch.load(' Weight path ') model.eval()
For non monolayer convolution channel pruning ( Don't look 3.1)
Before pruning, count the parameters of the model
num_params_before_pruning = tp.utils.count_params(model)1. setup strategy (L1 Norm) Calculate the weight of each channel
strategy = tp.strategy.L1Strategy()2. Build dependency graph ( And torch.jit It's like )
DG = tp.DependencyGraph()
DG = DG.build_dependency(model, example_inputs=torch.randn(1, 3, input_size[0], input_size[1])) # input_size Is the input size of the network 3. Sub situation (1. Single convolution for pruning 2. Layer for pruning )
3.1 Single convolution ( The channel index to be pruned will be returned , This channel is indexed according to L1 Regular results )
pruning_idxs = strategy(model.conv1.weight, amount=0.4) # model.conv1.weigth Is to prune a particular convolution ,amount Is the pruning rate All affected layers will be collected from the dependency graph , Propagate them to the whole graph , Then provide a PruningPlan How to trim the model correctly .
pruning_plan = DG.get_pruning_plan( model.conv1, tp.prune_conv, idxs=pruning_idxs ) pruning_plan.exec()
torch.save(model, 'pru_model.pth')3.2 Layer pruning ( You need to filter out layers that don't need pruning , such as yolo You need to take out the prediction part of the head , This one doesn't need pruning )
excluded_layers = list(model.model[-1].modules())
for m in model.modules():
if isinstance(m, nn.Conv2d) and m not in excluded_layers:
pruning_plan = DG.get_pruning_plan(m,tp.prune_conv, idxs=strategy(m.weight, amount=0.4))
print(pruning_plan) # Perform pruning pruning_plan.exec()If you want to see the parameters after pruning , Can run :
num_params_after_pruning = tp.utils.count_params(model)
print( " Params: %s => %s"%( num_params_before_pruning, num_params_after_pruning))Save the model after pruning ( Do not use torch.save(model.state_dict(),...))
torch.save(model, 'pruning_model.pth')
In the code prunmodel.py It's right yolov4 Pruning code
If your weight is torch.save(model.state_dict()) The saved , Please reload the model and use torch.save(model) preservation [ Or call save_whole_model function ]
If you need to prune a single convolution , You can call Conv_pruning( Model weight path [ Including the network structure diagram ]), And then in k Modify a convolution where you want to prune
If you need to prune a part , You can call layer_pruning() function ,included_layers It's the part you want to prune [ I'm right here SPP The last three convolution pruning , If you need to prune somewhere else , Need modification list The parameters inside , Be careful not to head Partial pruning ]
Forecast part
Forecast part , Fill in the weight path after pruning in pruning_yolo.py Medium "model_path" It's about , The default is coco Class [ Because the graph structure has been saved in the pruned model , Therefore, there is no need to instantiate the model when predicting ]. And then run predict_pruning.py You can modify mode,'predict' It's a prediction image ,'video' It's video [ Turn on your own camera by default ] FPS test , take mode Change it to fps[ My hardware is NVIDIA 1650,cuda10.2] Yes SPP After pruning the last three convolution layers of the network ,FPS by 18 Before pruning FPS15 I tried to prune the trunk , It is found that the accuracy loss is serious , You can try which part you want to cut , I just set up the framework for everyone to use , There is no guarantee of the final effect , I need to refine pills myself . You can train your own model , After pruning, the model should be fine tuned with heavy training to improve the accuracy , I haven't added this part of the code yet , You can put the weight after pruning into the training code and fine tune it . Fine tuning training will be added later .

Prediction results after pruning
stay coco On dataset , The parameter output before and after pruning is as follows :
Params: 64363101 => 60438323
The correct pruning will print out the following information 【 If you have similar information, you can prune normally , If it doesn't show up , That means you cut it wrong 】:
[ <DEP: prune_conv => prune_conv on conv2.2.conv (Conv2d(615, 512, kernel_size=(1, 1), stride=(1, 1), bias=False))>, Index=[1, 2, 3, 4, 7, 9, 15, 16, 17, 18, 23, 24, 35, 39, 42, 45, 46, 53, 54, 58, 62, 63, 65, 70, 73, 75, 81, 84, 88, 90, 97, 101, 102, 106, 109, 111, 112, 113, 116, 119, 124, 127, 132, 133, 135, 138, 140, 141, 143, 145, 148, 149, 150, 157, 159, 161, 163, 166, 168, 169, 170, 172, 174, 176, 177, 179, 180, 181, 182, 185, 186, 187, 189, 191, 193, 196, 200, 202, 207, 210, 211, 216, 217, 220, 222, 223, 225, 226, 228, 233, 234, 236, 238, 242, 243, 245, 246, 247, 248, 249, 251, 253, 254, 255, 256, 257, 266, 267, 270, 271, 279, 280, 284, 287, 288, 291, 295, 299, 301, 302, 305, 306, 307, 309, 311, 314, 316, 319, 325, 326, 328, 331, 333, 341, 342, 344, 345, 346, 348, 349, 352, 355, 356, 357, 361, 371, 372, 374, 375, 379, 381, 385, 388, 391, 394, 395, 399, 401, 403, 406, 408, 410, 414, 415, 418, 421, 425, 430, 432, 433, 434, 438, 439, 440, 444, 445, 448, 449, 452, 453, 461, 465, 467, 468, 469, 473, 475, 479, 480, 481, 482, 485, 487, 492, 493, 495, 497, 499, 504, 505, 507, 508, 510, 511], NumPruned=125460]
[ <DEP: prune_conv => prune_batchnorm on conv2.2.bn (BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))>, Index=[1, 2, 3, 4, 7, 9, 15, 16, 17, 18, 23, 24, 35, 39, 42, 45, 46, 53, 54, 58, 62, 63, 65, 70, 73, 75, 81, 84, 88, 90, 97, 101, 102, 106, 109, 111, 112, 113, 116, 119, 124, 127, 132, 133, 135, 138, 140, 141, 143, 145, 148, 149, 150, 157, 159, 161, 163, 166, 168, 169, 170, 172, 174, 176, 177, 179, 180, 181, 182, 185, 186, 187, 189, 191, 193, 196, 200, 202, 207, 210, 211, 216, 217, 220, 222, 223, 225, 226, 228, 233, 234, 236, 238, 242, 243, 245, 246, 247, 248, 249, 251, 253, 254, 255, 256, 257, 266, 267, 270, 271, 279, 280, 284, 287, 288, 291, 295, 299, 301, 302, 305, 306, 307, 309, 311, 314, 316, 319, 325, 326, 328, 331, 333, 341, 342, 344, 345, 346, 348, 349, 352, 355, 356, 357, 361, 371, 372, 374, 375, 379, 381, 385, 388, 391, 394, 395, 399, 401, 403, 406, 408, 410, 414, 415, 418, 421, 425, 430, 432, 433, 434, 438, 439, 440, 444, 445, 448, 449, 452, 453, 461, 465, 467, 468, 469, 473, 475, 479, 480, 481, 482, 485, 487, 492, 493, 495, 497, 499, 504, 505, 507, 508, 510, 511], NumPruned=408]
[ <DEP: prune_batchnorm => _prune_elementwise_op on _ElementWiseOp()>, Index=[1, 2, 3, 4, 7, 9, 15, 16, 17, 18, 23, 24, 35, 39, 42, 45, 46, 53, 54, 58, 62, 63, 65, 70, 73, 75, 81, 84, 88, 90, 97, 101, 102, 106, 109, 111, 112, 113, 116, 119, 124, 127, 132, 133, 135, 138, 140, 141, 143, 145, 148, 149, 150, 157, 159, 161, 163, 166, 168, 169, 170, 172, 174, 176, 177, 179, 180, 181, 182, 185, 186, 187, 189, 191, 193, 196, 200, 202, 207, 210, 211, 216, 217, 220, 222, 223, 225, 226, 228, 233, 234, 236, 238, 242, 243, 245, 246, 247, 248, 249, 251, 253, 254, 255, 256, 257, 266, 267, 270, 271, 279, 280, 284, 287, 288, 291, 295, 299, 301, 302, 305, 306, 307, 309, 311, 314, 316, 319, 325, 326, 328, 331, 333, 341, 342, 344, 345, 346, 348, 349, 352, 355, 356, 357, 361, 371, 372, 374, 375, 379, 381, 385, 388, 391, 394, 395, 399, 401, 403, 406, 408, 410, 414, 415, 418, 421, 425, 430, 432, 433, 434, 438, 439, 440, 444, 445, 448, 449, 452, 453, 461, 465, 467, 468, 469, 473, 475, 479, 480, 481, 482, 485, 487, 492, 493, 495, 497, 499, 504, 505, 507, 508, 510, 511], NumPruned=0]
[ <DEP: _prune_elementwise_op => prune_related_conv on upsample1.upsample.0.conv (Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False))>, Index=[1, 2, 3, 4, 7, 9, 15, 16, 17, 18, 23, 24, 35, 39, 42, 45, 46, 53, 54, 58, 62, 63, 65, 70, 73, 75, 81, 84, 88, 90, 97, 101, 102, 106, 109, 111, 112, 113, 116, 119, 124, 127, 132, 133, 135, 138, 140, 141, 143, 145, 148, 149, 150, 157, 159, 161, 163, 166, 168, 169, 170, 172, 174, 176, 177, 179, 180, 181, 182, 185, 186, 187, 189, 191, 193, 196, 200, 202, 207, 210, 211, 216, 217, 220, 222, 223, 225, 226, 228, 233, 234, 236, 238, 242, 243, 245, 246, 247, 248, 249, 251, 253, 254, 255, 256, 257, 266, 267, 270, 271, 279, 280, 284, 287, 288, 291, 295, 299, 301, 302, 305, 306, 307, 309, 311, 314, 316, 319, 325, 326, 328, 331, 333, 341, 342, 344, 345, 346, 348, 349, 352, 355, 356, 357, 361, 371, 372, 374, 375, 379, 381, 385, 388, 391, 394, 395, 399, 401, 403, 406, 408, 410, 414, 415, 418, 421, 425, 430, 432, 433, 434, 438, 439, 440, 444, 445, 448, 449, 452, 453, 461, 465, 467, 468, 469, 473, 475, 479, 480, 481, 482, 485, 487, 492, 493, 495, 497, 499, 504, 505, 507, 508, 510, 511], NumPruned=52224]
[ <DEP: _prune_elementwise_op => _prune_concat on _ConcatOp([0, 512, 1024])>, Index=[513, 514, 515, 516, 519, 521, 527, 528, 529, 530, 535, 536, 547, 551, 554, 557, 558, 565, 566, 570, 574, 575, 577, 582, 585, 587, 593, 596, 600, 602, 609, 613, 614, 618, 621, 623, 624, 625, 628, 631, 636, 639, 644, 645, 647, 650, 652, 653, 655, 657, 660, 661, 662, 669, 671, 673, 675, 678, 680, 681, 682, 684, 686, 688, 689, 691, 692, 693, 694, 697, 698, 699, 701, 703, 705, 708, 712, 714, 719, 722, 723, 728, 729, 732, 734, 735, 737, 738, 740, 745, 746, 748, 750, 754, 755, 757, 758, 759, 760, 761, 763, 765, 766, 767, 768, 769, 778, 779, 782, 783, 791, 792, 796, 799, 800, 803, 807, 811, 813, 814, 817, 818, 819, 821, 823, 826, 828, 831, 837, 838, 840, 843, 845, 853, 854, 856, 857, 858, 860, 861, 864, 867, 868, 869, 873, 883, 884, 886, 887, 891, 893, 897, 900, 903, 906, 907, 911, 913, 915, 918, 920, 922, 926, 927, 930, 933, 937, 942, 944, 945, 946, 950, 951, 952, 956, 957, 960, 961, 964, 965, 973, 977, 979, 980, 981, 985, 987, 991, 992, 993, 994, 997, 999, 1004, 1005, 1007, 1009, 1011, 1016, 1017, 1019, 1020, 1022, 1023], NumPruned=0]
[ <DEP: _prune_concat => prune_related_conv on make_five_conv4.0.conv (Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False))>, Index=[513, 514, 515, 516, 519, 521, 527, 528, 529, 530, 535, 536, 547, 551, 554, 557, 558, 565, 566, 570, 574, 575, 577, 582, 585, 587, 593, 596, 600, 602, 609, 613, 614, 618, 621, 623, 624, 625, 628, 631, 636, 639, 644, 645, 647, 650, 652, 653, 655, 657, 660, 661, 662, 669, 671, 673, 675, 678, 680, 681, 682, 684, 686, 688, 689, 691, 692, 693, 694, 697, 698, 699, 701, 703, 705, 708, 712, 714, 719, 722, 723, 728, 729, 732, 734, 735, 737, 738, 740, 745, 746, 748, 750, 754, 755, 757, 758, 759, 760, 761, 763, 765, 766, 767, 768, 769, 778, 779, 782, 783, 791, 792, 796, 799, 800, 803, 807, 811, 813, 814, 817, 818, 819, 821, 823, 826, 828, 831, 837, 838, 840, 843, 845, 853, 854, 856, 857, 858, 860, 861, 864, 867, 868, 869, 873, 883, 884, 886, 887, 891, 893, 897, 900, 903, 906, 907, 911, 913, 915, 918, 920, 922, 926, 927, 930, 933, 937, 942, 944, 945, 946, 950, 951, 952, 956, 957, 960, 961, 964, 965, 973, 977, 979, 980, 981, 985, 987, 991, 992, 993, 994, 997, 999, 1004, 1005, 1007, 1009, 1011, 1016, 1017, 1019, 1020, 1022, 1023], NumPruned=104448]
282540 parameters will be prunedCode
Code address :https://github.com/YINYIPENG-EN/Pruning_for_yolov4.git
Weight Links : link : Baidu cloud disk Extraction code :yypn
版权声明
本文为[Meat loving Peng]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231753583014.html
边栏推荐
- 一些问题一些问题一些问题一些问题
- 2021长城杯WP
- ES6 face test questions (reference documents)
- Anchor location - how to set the distance between the anchor and the top of the page. The anchor is located and offset from the top
- 云原生虚拟化:基于 Kubevirt 构建边缘计算实例
- An example of linear regression based on tensorflow
- 2022江西储能技术展会,中国电池展,动力电池展,燃料电池展
- Cross domain settings of Chrome browser -- including new and old versions
- Gaode map search, drag and drop query address
- Welcome to the markdown editor
猜你喜欢






随机推荐
Go语言JSON包使用
Click Cancel to return to the previous page and modify the parameter value of the previous page, let pages = getcurrentpages() let prevpage = pages [pages. Length - 2] / / the data of the previous pag
土地覆盖/利用数据产品下载
Add drag and drop function to El dialog
Halo open source project learning (II): entity classes and data tables
云原生虚拟化:基于 Kubevirt 构建边缘计算实例
How to read literature
Add animation to the picture under V-for timing
_ FindText error
Cloud native Virtualization: building edge computing instances based on kubevirt
122. 买卖股票的最佳时机 II-一次遍历
2022江西光伏展,中國分布式光伏展會,南昌太陽能利用展
Listen for click events other than an element
394. 字符串解码-辅助栈
Where is the configuration file of tidb server?
Transfer learning of five categories of pictures based on VGg
In JS, t, = > Analysis of
2022江西光伏展,中国分布式光伏展会,南昌太阳能利用展
Go file operation
587. 安装栅栏 / 剑指 Offer II 014. 字符串中的变位词