当前位置:网站首页>预览CSV文件
预览CSV文件
2022-04-23 14:07:00 【ジ你是我永远のbugグ】
UnicodeReader工具类
package com.example.file.file;
/** version: 1.1 / 2007-01-25 - changed BOM recognition ordering (longer boms first) Original pseudocode : Thomas Weidenfeller Implementation tweaked: Aki Nieminen http://www.unicode.org/unicode/faq/utf_bom.html BOMs: 00 00 FE FF = UTF-32, big-endian FF FE 00 00 = UTF-32, little-endian EF BB BF = UTF-8, FE FF = UTF-16, big-endian FF FE = UTF-16, little-endian Win2k Notepad: Unicode format = UTF-16LE ***/
import java.io.*;
/** * Generic unicode textreader, which will use BOM mark * to identify the encoding to be used. If BOM is not found * then use a given default or system encoding. */
public class UnicodeReader extends Reader {
PushbackInputStream internalIn;
InputStreamReader internalIn2 = null;
String defaultEnc;
private static final int BOM_SIZE = 4;
/** * @param in inputstream to be read * @param defaultEnc default encoding if stream does not have * BOM marker. Give NULL to use system-level default. */
public UnicodeReader(InputStream in, String defaultEnc) {
internalIn = new PushbackInputStream(in, BOM_SIZE);
this.defaultEnc = defaultEnc;
}
public String getDefaultEncoding() {
return defaultEnc;
}
/** * Get stream encoding or NULL if stream is uninitialized. * Call init() or read() method to initialize it. */
public String getEncoding() {
if (internalIn2 == null) return null;
return internalIn2.getEncoding();
}
/** * Read-ahead four bytes and check for BOM marks. Extra bytes are * unread back to the stream, only BOM bytes are skipped. */
protected void init() throws IOException {
if (internalIn2 != null) return;
String encoding;
byte bom[] = new byte[BOM_SIZE];
int n, unread;
n = internalIn.read(bom, 0, bom.length);
if ((bom[0] == (byte) 0x00) && (bom[1] == (byte) 0x00) &&
(bom[2] == (byte) 0xFE) && (bom[3] == (byte) 0xFF)) {
encoding = "UTF-32BE";
unread = n - 4;
} else if ((bom[0] == (byte) 0xFF) && (bom[1] == (byte) 0xFE) &&
(bom[2] == (byte) 0x00) && (bom[3] == (byte) 0x00)) {
encoding = "UTF-32LE";
unread = n - 4;
} else if ((bom[0] == (byte) 0xEF) && (bom[1] == (byte) 0xBB) &&
(bom[2] == (byte) 0xBF)) {
encoding = "UTF-8";
unread = n - 3;
} else if ((bom[0] == (byte) 0xFE) && (bom[1] == (byte) 0xFF)) {
encoding = "UTF-16BE";
unread = n - 2;
} else if ((bom[0] == (byte) 0xFF) && (bom[1] == (byte) 0xFE)) {
encoding = "UTF-16LE";
unread = n - 2;
} else {
// Unicode BOM mark not found, unread all bytes
encoding = defaultEnc;
unread = n;
}
//System.out.println("read=" + n + ", unread=" + unread);
if (unread > 0) internalIn.unread(bom, (n - unread), unread);
// Use given encoding
if (encoding == null) {
internalIn2 = new InputStreamReader(internalIn);
} else {
internalIn2 = new InputStreamReader(internalIn, encoding);
}
}
public void close() throws IOException {
init();
internalIn2.close();
}
public int read(char[] cbuf, int off, int len) throws IOException {
init();
return internalIn2.read(cbuf, off, len);
}
}
主程序类
package com.example.file.file;
import com.csvreader.CsvReader;
import java.io.*;
import java.util.ArrayList;
public class PreviewChunkCSV {
public static void main(String[] args) throws IOException {
// 文件的路径
File file = new File("C:\\Users\\86130\\Desktop\\仙启产品工具包\\工作簿1.csv");
// 用来保存数据
ArrayList<String[]> csvFileList = new ArrayList<>();
// 文件编码格式
String filecharset = getFilecharset(new FileInputStream(file));
// 定义一个CSV路径
UnicodeReader breader = new UnicodeReader(new FileInputStream(file), filecharset);
CsvReader csvReader = new CsvReader(breader);
// 若只获得 数据的BODY(字节码文件)
// InputStream inputStream = new //ByteArrayInputStream(fileDescriptor.getBody().toByteArray());
// BufferedReader breader = new BufferedReader(new InputStreamReader(inputStream, "UTF-8"), 8192);
// 跳过表头 需要表头 忽略这一句
csvReader.readHeaders();
// 获取 表头
String[] headers = csvReader.getHeaders();
ArrayList<String> mRowList = new ArrayList<>();
// 获取 最多40列表头、200行数据
int headCount = 40;
int rowCount = 200;
if (headers.length < headCount){
headCount = headers.length;
}
// 全部表头
String[] mHeadArray = new String[headers.length];
// 展示的表头
String[] showHeadArray = new String[headCount];
for(int i = 0; i < headers.length; i++){
mHeadArray[i] = headers[i];
}
for (int i = 0; i < headCount; i++){
showHeadArray[i] = headers[i];
}
// 逐行读取除表头的数据
while (csvReader.readRecord()){
csvFileList.add(csvReader.getValues());
}
csvReader.close();
if (csvFileList.size() < 200){
rowCount = csvFileList.size();
}
// 遍历读取CSV文件
for (int row = 0; row < rowCount; row++){
String rowItem = "";
for (int i = 0; i < headCount; i++){
// 获取第 row 行 第0列的数据
String cell = "";
if (i < headCount-1){
cell = csvFileList.get(row)[i] + ",";
}else {
cell = csvFileList.get(row)[i];
}
rowItem = rowItem + cell;
}
mRowList.add(rowItem);
}
System.out.println("==================表头===========================");
System.out.println(mHeadArray);
System.out.println("==================展示的表头======================");
System.out.println(showHeadArray);
System.out.println("==================mRowList======================");
System.out.println(mRowList);
System.out.println("==================展示的行数======================");
System.out.println(mRowList.size());
}
private static String getFilecharset(InputStream inputStream) {
//默认GBK
String charset = "GBK";
byte[] first3Bytes = new byte[3];
try (BufferedInputStream bis = new BufferedInputStream(inputStream)) {
bis.mark(0);
int read = bis.read(first3Bytes, 0, 3);
// 文件编码为 ANSI
if (read == -1) {
return charset;
}
// 文件编码为 Unicode
if (first3Bytes[0] == (byte) 0xFF && first3Bytes[1] == (byte) 0xFE) {
return "UTF-16LE";
}
// 文件编码为 Unicode big endian
if (first3Bytes[0] == (byte) 0xFE && first3Bytes[1] == (byte) 0xFF) {
return "UTF-16BE";
}
// 文件编码为 UTF-8
if (first3Bytes[0] == (byte) 0xEF && first3Bytes[1] == (byte) 0xBB && first3Bytes[2] == (byte) 0xBF) {
return "UTF-8";
}
bis.reset();
int loc = 0;
while ((read = bis.read()) != -1) {
loc++;
if (read >= 0xF0) {
break;
}
// 单独出现BF以下的,也算是GBK
if (0x80 <= read && read <= 0xBF) {
break;
}
if (0xC0 <= read && read <= 0xDF) {
read = bis.read();
// 双字节 (0xC0 - 0xDF)
if (0x80 <= read && read <= 0xBF) {
// (0x80
// - 0xBF),也可能在GB编码内
continue;
}
break;
}
// 也有可能出错,但是几率较小
if (0xE0 <= read && read <= 0xEF) {
read = bis.read();
if (0x80 <= read && read <= 0xBF) {
read = bis.read();
if (0x80 <= read && read <= 0xBF) {
charset = "UTF-8";
}
}
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
return charset;
}
}
版权声明
本文为[ジ你是我永远のbugグ]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_47848696/article/details/120077463
边栏推荐
- 数据库DbVisualizer Pro报文件错误,导致数据连接失败
- 云容灾是什么意思?云容灾和传统容灾的区别?
- Easyexcel读取excel表地理位置数据,按中文拼音排序
- mysql 5.1升级到5.66
- 政务云迁移实践 北明数科使用HyperMotion云迁移产品为某政府单位实施上云迁移项目,15天内完成近百套主机迁移
- Win10 comes with groove music, which can't play cue and ape files. It's a curvilinear way to save the country. It creates its own aimpack plug-in package, and aimp installs DSP plug-in
- Wechat applet communicates with esp8266 based on UDP protocol
- leetcode--357. Count the number of different figures
- RobotFramework 之 用例执行
- RecyclerView高级使用(二)-垂直拖拽排序的简单实现
猜你喜欢

Prediction of tomorrow's trading limit of Low Frequency Quantization

DeepinV20安装Mariadb

Chapter I review of e-commerce spike products
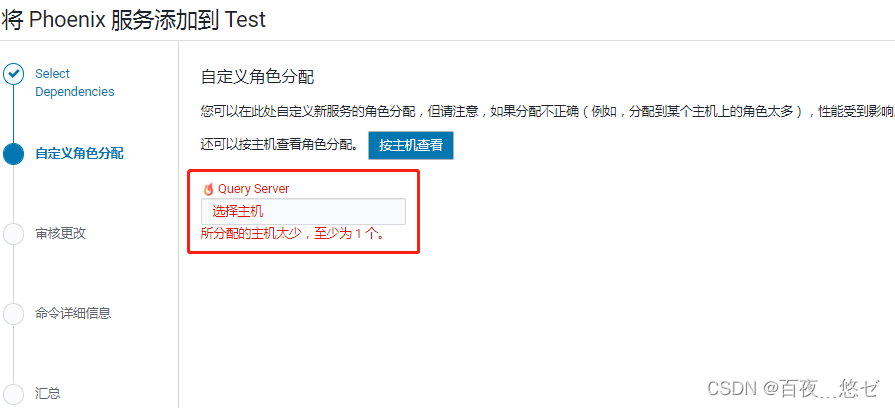
CDH cluster integration Phoenix based on CM management
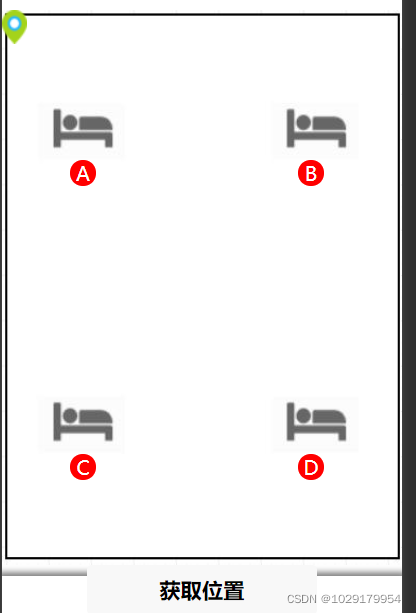
室内外地图切换(室内基于ibeacons三点定位)

微信小程序setInterval定时函数使用详细教程
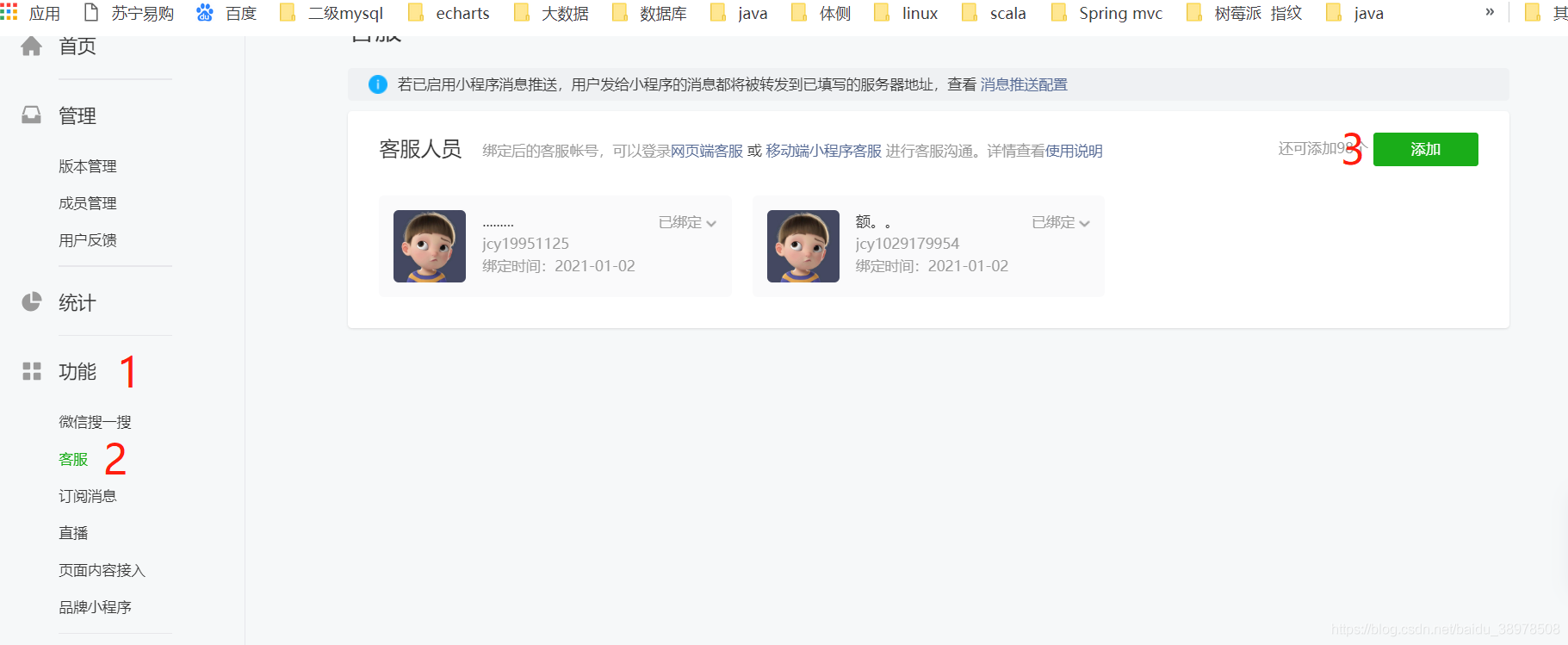
微信小程序调用客服接口
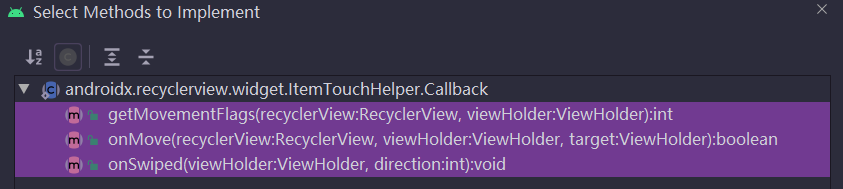
Recyclerview advanced use (I) - simple implementation of sideslip deletion
Use of WiFi module based on wechat applet

烟雾传感器(mq-2)使用详细教程(基于树莓派3b+实现)

随机推荐
mysql 5.1升级到5.610
Research on recyclerview details - Discussion and repair of recyclerview click dislocation
sql中出现一个变态问题
关于密匙传递的安全性和数字签名
Algorithem_ReverseLinkedList
Kettle -- control parsing
基于CM管理的CDH集群集成Phoenix
Three point positioning based on ibeacons (wechat applet)
log4j 输出日志信息到文件中
redis数据库讲解二(redis高可用、持久化、性能管理)
不同时间类型的执行计划计算
Visio installation error 1:1935 2: {XXXXXXXX
倒计时1天~2022云容灾产品线上发布会即将开始
Postman的安装使用及填坑心得
全局变量能否放在头文件中定义
微信小程序的订阅号开发(消息推送)
教育行业云迁移最佳实践:海云捷迅使用HyperMotion云迁移产品为北京某大学实施渐进式迁移,成功率100%
烟雾传感器(mq-2)使用详细教程(基于树莓派3b+实现)
室内外地图切换(室内基于ibeacons三点定位)
Promtail + Loki + Grafana 日志监控系统搭建