当前位置:网站首页>elk安装
elk安装
2022-04-23 14:08:00 【阿闰】
参考 谢谢 https://zhuanlan.zhihu.com/p/107346014?from_voters_page=true
其他问题修改容器内存:https://www.cnblogs.com/xiaohanlin/p/11800337.html
查看容器日志:docker attach --sig-proxy=false 容器id
docker pull filebeat:7.6.0没装上
ELK是Elasticsearch、Logstash、Kibana的简称,这三者是核心套件,但并非全部。
Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
Logstash是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch。
Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据
一、参考资料
- 官网地址
- http://mirrors.aliyun.com/centos
- https://github.com/medcl/elasticsearch-analysis-ik/releases
- https://www.cnblogs.com/William-Guozi/p/elk-docker.html
- https://www.cnblogs.com/peterpoker/p/9573720.html
- https://www.cnblogs.com/just-coder/p/11017050.html
二、下载相关的docker镜像
docker pull elasticsearch:7.6.0
docker pull kibana:7.6.0
docker pull logstash:7.6.0
docker pull filebeat:7.6.0
docker pull mobz/elasticsearch‐head:5三、搭建ELK日志系统
创建一个elk文件夹, 后面的配置文件都放在里面
mkdir /home/elk3.1 安装elasticsearch
创建一个elasticsearch.yml文件
vi /home/elk/elasticsearch.yml在里面添加如下配置:
cluster.name: "docker-cluster"
network.host: 0.0.0.0
# 访问ID限定,0.0.0.0为不限制,生产环境请设置为固定IP
transport.host: 0.0.0.0
# elasticsearch节点名称
node.name: node-1
# elasticsearch节点信息
cluster.initial_master_nodes: ["node-1"]
# 下面的配置是关闭跨域验证
http.cors.enabled: true
http.cors.allow-origin: "*"创建并启动elasticsearch容器
docker run -di -p 9200:9200 -p 9300:9300 --name=elasticsearch -v /home/elk/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch:7.6.0之后通过9200端口在浏览器上范围,有信息返回则成功
注意:如果需要添加插件将容器的插件目录映射到实际的路径中或者通过命令(如安装ik分词器:
docker cp ik elasticsearch:/usr/share/elasticsearch/plugins/)将其拷贝到容器中
可能遇到的问题
1.启动成功后,过了一会就停止
这与我们刚才修改的配置有关,因为elasticsearch在启动的时候会进行一些检查,比如最多打开的文件的个数以及虚拟内存
区域数量等等,如果你放开了此配置,意味着需要打开更多的文件以及虚拟内存,所以我们还需要系统调优。
- 修改/etc/security/limits.conf ,添加如下内容:
* soft nofile 65536 - * hard nofile 65536
nofile是单个进程允许打开的最大文件个数 soft nofile 是软限制 hard nofile是硬限制
- 修改/etc/sysctl.conf,追加内容
vm.max_map_count=655360
限制一个进程可以拥有的VMA(虚拟内存区域)的数量
执行下面命令 修改内核参数马上生效,之后重启服务器和docker服务
sysctl ‐p2. 启动失败显示如下日志信息
ERROR: [1] bootstrap checks failed
[1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured这个是由于elasticsearch7是集群多节点的版本,需要在elasticsearch.yml中添加如下配置:
# elasticsearch节点名称
node.name: node-1
# elasticsearch节点信息
cluster.initial_master_nodes: ["node-1"]3. 外网上已经可以通过9200端口推送数据和查询数据,但是后面安装的kibana等组件却无法连
查看日志发现如下错误
error=>"Elasticsearch Unreachable: [http://192.168.6.128:9200/][Manticore::...这个问题通常是由于安装在一台机器上的docker容器,防火墙开启的状态下,docker容器内部无法访问宿主机服务(能够访问非宿主机的其他局域网计算机的服务),解决方法:
- 配置防火墙规则firewall-cmd --zone=public --add-port={port}/tcp --permanent,并重载防火墙规则firewall-cmd --reload
- 启动容器时使用--net host模式(docker的4种网络模式:https://www.jianshu.com/p/22a7032bb7bd)
- 关闭防火墙
安装elasticsearch‐head插件做调试使用(可以不安装)
docker run ‐di ‐‐name=es-head ‐p 9100:9100 mobz/elasticsearch‐head:5启动成功后访问9100端口即可使用界面化进行管理elasticsearch。
在本地电脑上安装
- 下载head插件:https://github.com/mobz/elasticsearch-head
- 将grunt安装为全局命令 。Grunt是基于Node.js的项目构建工具。它可以自动运行你所 设定的任务
npm install ‐g grunt‐cli - 安装依赖
npm install - 启动
grunt server
打开浏览器,输入 http://localhost:9100
3.2 安装kibana
kibana主要用于对elasticsearch的数据进行分析查看。注意选择的版本必须和elasticsearch的版本相同或者低,建议和elasticsearch的版本相同,否则会无法将无法使用kibana。
创建一个kibana.yml配置文件,在里面编写如下配置:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://elasticsearch的IP:9200"]
# 操作界面语言设置
i18n.locale: "zh-CN"创建并启动kibana容器
docker run -di --name kibana -p 5601:5601 -v /home/elk/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.6.0启动成功后访问5601端口即可进入kibana管理界面。(进入后要求选择配置,直接选择自己浏览即可)
添加索引配置
这个先安装logstash后再回过来操作;输入log*即可选择logstash的日志信息,创建成功后即可查看日志信息
3.3 安装logstash
创建一个logstash.conf配置文件,在里面添加如下配置:
input {
tcp {
port => 5044
codec => "plain"
}
}
filter{
}
output {
# 这个是logstash的控制台打印(进行安装调试的开启,稍后成功后去掉这个配置即可)
stdout {
codec => rubydebug
}
# elasticsearch配置
elasticsearch {
hosts => ["elasticsearch的IP:9200"]
}
}创建和启动logstash容器
docker run -di -p 5044:5044 -v /home/elk/logstash.conf:/usr/share/logstash/pipeline/logstash.conf --name logstash logstash:7.6.0将微服务的日志推送到logstash中
添加maven依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.3</version>
</dependency>下面以springboot中logback作为日志处理,配置文件(logback-spring.xml)配置信息如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 控制台输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %highlight(%-5level) %cyan(%logger{50}.%M.%L) - %highlight(%msg) %n</pattern>
</layout>
</appender>
<!--logback输出-->
<appender name="STASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.6.128:5044</destination>
<includeCallerData>true</includeCallerData>
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<includeCallerData>true</includeCallerData>
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{80}.%M.%L - %msg %n</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<!--本地开发调试将控制台输出打开,同时将日志文件输出关闭,提高日志性能;线上部署请务必将控制台输出关闭-->
<appender-ref ref="STDOUT"/>
<appender-ref ref="STASH"/>
</root>
</configuration>
版权声明
本文为[阿闰]所创,转载请带上原文链接,感谢
https://blog.csdn.net/wasd986523/article/details/117162478
边栏推荐
猜你喜欢
RobotFramework 之 用例执行
MySQL数据库讲解(十)
Pycharm连接远程服务器并实现远程调试

On the multi-level certificate based on OpenSSL, the issuance and management of multi-level Ca, and two-way authentication

帆软分割求解:一段字符串,只取其中某个字符(所需要的字段)
使用DialogFragment的一些感受及防踩坑经验(getActivity、getDialog为空,cancelable无效等)
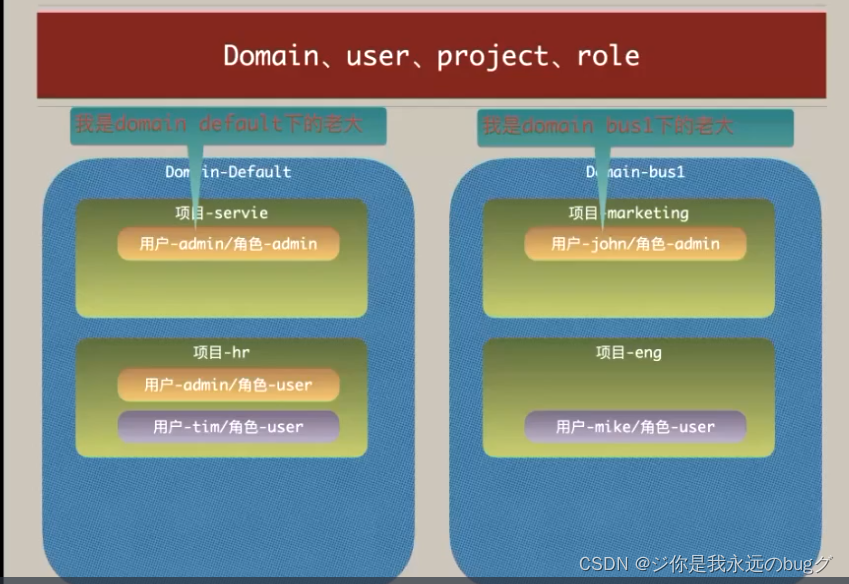
openstack理论知识
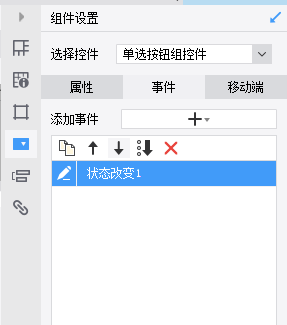
帆软实现一个单选按钮,可以统一设置其他单选按钮的选择状态
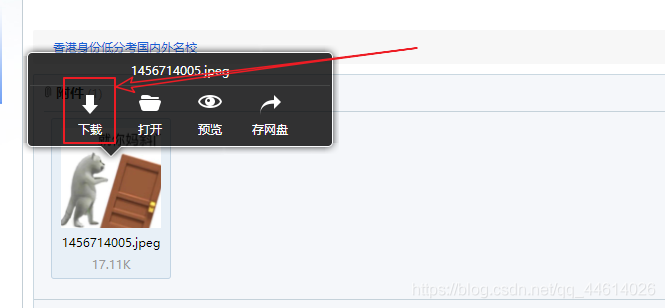
RobotFramework 之 文件上传和下载
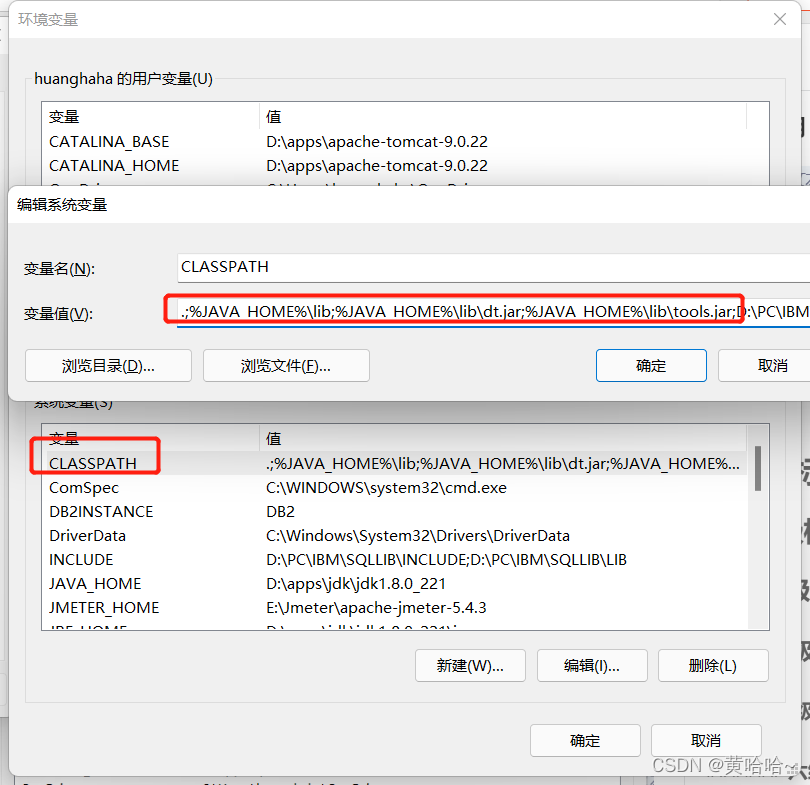
Jmeter安装教程以及我遇到的问题的解决办法
随机推荐
1到100号的灯开关问题
Storage path of mod subscribed by starbound Creative Workshop at Star boundary
logback-logger和root
redis数据库讲解(四)主从复制、哨兵、Cluster群集
Essential difference between restful WebService and gSOAP webservice
redis数据库讲解二(redis高可用、持久化、性能管理)
dp-[NOIP2000]方格取数
Wechat applet positioning and ranging through low-power Bluetooth device (2)
VMware installation 64 bit XP Chinese tutorial
redis数据库讲解(三)redis数据类型
星界边境文本自动翻译机使用说明
sql中出现一个变态问题
Wechat applet initializes Bluetooth, searches nearby Bluetooth devices and connects designated Bluetooth (I)
POI operation word template replaces data and exports word
连接公司跳板机取别名
困扰多年的系统调研问题有自动化采集工具了,还是开源免费的
Use of WiFi module based on wechat applet
Installation and use of postman pit
RecyclerView细节研究-RecyclerView点击错位问题的探讨与修复
Recyclerview advanced use (I) - simple implementation of sideslip deletion