当前位置:网站首页>构建面向特征工程的数据生态 ——拥抱开源生态,OpenMLDB全面打通MLOps生态工具链
构建面向特征工程的数据生态 ——拥抱开源生态,OpenMLDB全面打通MLOps生态工具链
2022-08-11 05:26:00 【第四范式开发者社区】
引言:随着业务的发展,模型应用场景的增加,AI 工程化落地成为了不少企业面对的切实挑战。近几年,应对这个痛点的新概念——MLOps 逐渐成为了机器学习领域的热门话题。OpenMLDB 提供FeatureOps 全栈解决方案,积极打通 MLOps工具链,建立起一个标准化的模型开发、部署与运维流程,降低开发者落地 AI 的门槛,使得企业组织能够更好地利用机器学习的能力来促进业务增长。
关于OpenMLDB
OpenMLDB 是一个开源机器学习数据库,致力于闭环解决 AI 工程化落地的数据治理难题。自2021 年 6 月开源以来,OpenMLDB 优先开源了特征数据治理能力,依托 SQL 的开发能力,为企业提供全栈功能的、低门槛特征数据计算和管理平台。
OpenMLDB 包含 Feature Store 的全部功能,并且提供更为完整的 FeatureOps 全栈方案。除了提供特征存储功能,还具有基于 SQL 的低门槛数据库开发体验、面向特征计算优化的 OpenMLDB Spark 发行版,针对实时特征计算优化的索引结构,特征上线服务、企业级运维和管理等功能,让特征工程开发回归于本质——专注于高质量的特征计算脚本开发,不再被工程化效率落地所羁绊。 MLOps完整生命周期
在机器学习解决方案的开发、测试、部署、支持过程中,分工合作的多学科专家或团队会在协作中遇到许多沟通难题和技术障碍,这些痛难点不仅延长了产品工程化落地的时间,还增加了成本、减少了价值空间。
为了消除这些障碍,MLOps这一概念应运而生,并在近几年承接了广泛的关注和极大的期待,MLOps旨在统一 ML 系统开发(dev)和 ML 系统部署(ops),以标准化过程生产高性能模型的持续交付,达到更快试验和开发模型、更快将模型部署到生产环境、保证质量的目的。
在MLOps 运作的闭环流程中,MLOps常被分为离线开发和线上服务两个部分,对应着机器学习相关开发中,模型训练和模型上线的两个部分。当我们把这离线开发和线上服务放置在企业级的生产场景当中,它们又可以进一步地拆解为 DataOps、FeatureOps 和 ModelOps 三个环节。
在离线开发中,DataOps 承担数据采集、存储的工作,FeatureOps 进行特征的储存、共享和离线特征计算,ModelOps 负责模型训练以及超参数调优
在线上服务时,DataOps 承担在线推理、结果数据回流的工作,FeatureOps 进行实时特征计算与特征服务 ,ModelOps 负责实时数据流接入以及处理实时请求
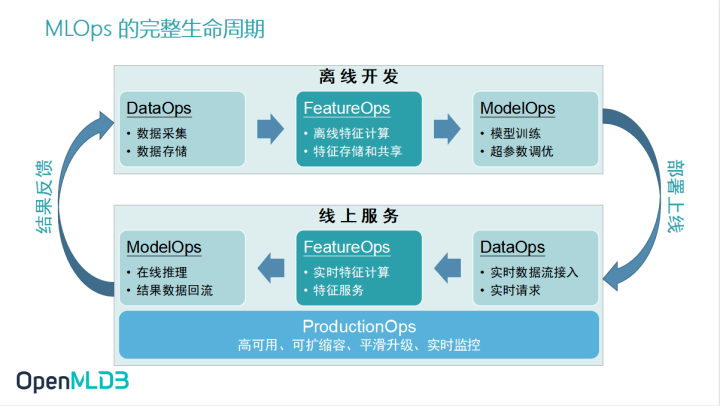
为满足企业级生产需求,ProductionOps作为企业人工智能工程化落地中的另外一个关键环节,值得引起开发者的关注和重视。在生产环境之下,企业会非常看重高可用、可扩缩容、平滑升级、实时监控等等企业级核心需求。所以 ProductionOps 也是 OpenMLDB 作为 FeatureOps 优化升级过程中备受关注的一环。
OpenMLDB 面向 MLOps 的生态工具链
将OpenMLDB投射到包含DataOps、FeatureOps 和 ModelOps三大板块的MLOps中,可以看到OpenMLDB占据着其中FeatureOps的位置,主要是承担特征计算的职能。
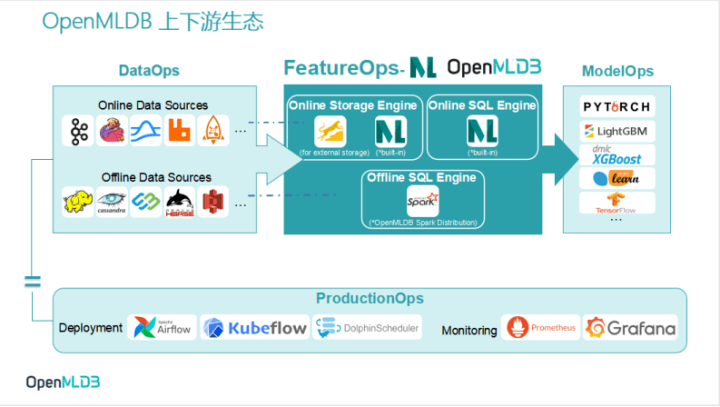
1、OpenMLDB内部框架
OpenMLDB的内部架构可简单分为在线引擎和离线引擎两部分,分别支持在线特征计算和离线特征计算。
- 在线引擎:分为在线执行引擎和在线储存引擎。
在线执行引擎,即 Online SQL Engine,是 OpenMLDB 的自研引擎,被用于高性能的 SQL 计算。 在线存储引擎,出于储存最新实时数据的需要,OpenMLDB 在 SQL 执行层面创建了一个 Storage engine,于默认情况下会有 in memory storage(build in)。Storage engine 可以被理解为一个非常高效的、专门面向时序数据库进行优化的一个内存数据库。
(Tips:除自研的在线存储引擎外,OpenMLDB 也支持磁盘数据,即将上新的 OpenMLDB v 0.5.0的版本将提供两种不同的 Storage Engine。对性能要求高,可以选择 in memory storage engine;更重视成本,那么可以使用基于磁盘的存储,如 RocksDB。)
- 离线引擎:即Offline SQL Engine。是基于原版Spark做了合理的优化升级,可以更高效地应用于离线特征计算。
2、OpenMLDB 上游生态——DataOps(即 Data sources)
DataOps 是 OpenMLDB 的数据获取源,即生态上游。在 Online data sources 板块,OpenMLDB社区于前不久发布了 OpenMLDB Pulsar connector, 支持 Pulsar 数据的接入。
OpenMLDB Pulsar Connector 下载地址
https://github.com/4paradigm/OpenMLDB/releases/download/v0.4.4/pulsar-io-jdbc-openmldb-2.11.0-SNAPSHOT.nar 未来新发布的版本中,OpenMLDB Kafka connector 也将与大家见面,为用户增加数据接入的多种选择,提供便利。在 Offline data sources板块,OpenMLDB 现支持 HDFS、S3 数据的直接接入,未来也会扩展更多的数据源。
3、OpenMLDB下游生态——ModelOps
ModelOps是OpenMLDB的下游模型生态。下游模型通过一些标准输出格式,就能直接接入。在5月初即将发布的v0.5.0版本中,OpenMLDB将整合模型特征功能,通过输出标准的 LIBSVM 或者 CSV 的格式,可直接供 PyTorch 等计算框架使用。
4、OpenMLDB部署生态——ProductionOps
ProductionOps层面的部署编排也在OpenMLDB的规划当中。目前,OpenMLDB 已经和 Airflow 和 Kubeflow 进行了对接,有望在近期完成与 Airflow 的合作内容。监控方面,OpenMLDB 已经和 Prometheus 和 Grafana 做了对接。
结语:
作为国内首个开源机器学习数据库,OpenMLDB始终坚持研发创新,全面提升产品性能和易用性;作为生产级 FeatureOps 全栈解决方案的提供者,OpenMLDB一直积极构建MLOps生态工具链,不断加强开源上下游合作共建。 获取更多OpenMLDB产品及生态内容,欢迎关注社区的官网、Github主页、知乎账号。
OpenMLDB - 生产级特征开发全栈解决方案
GitHub - 4paradigm/OpenMLDB: OpenMLDB is an open-source machine learning database that provides a full-stack FeatureOps solution for production.
4PD开发者社区 - 知乎
边栏推荐
- C语言实现简易扫雷(附带源码)
- Mei cole studios - sixth DjangoWeb application framework + MySQL database training
- Wisdom construction site safety helmet identification system
- Maykel Studio - Django Web Application Framework + MySQL Database Third Training
- CMT2380F32模块开发10-高级定时器例程
- swin-transformer训练自己的数据集<自留>
- 关于接口响应内容的解码
- 产品经理人物推荐
- STM32学习笔记(白话文理解版)—按键控制
- Generic kernel and userspace Makefiles
猜你喜欢
音乐竞品分析:酷狗、QQ音乐、网易云、酷我、汽水音乐
weex入门踩坑
Severe Weather 3D Object Detection Dataset Collection
华为IOT设备消息上报和消息下发验证
Maykle Studio - HarmonyOS Application Development Third Training

Hard hat identification

Hard hat recognition algorithm
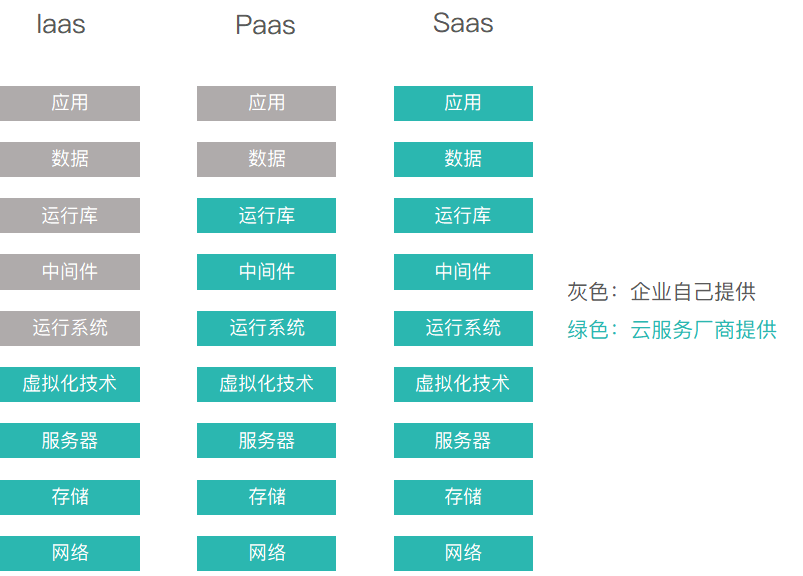
aPaaS和iPaaS的区别
Node-3.构建Web应用(二)
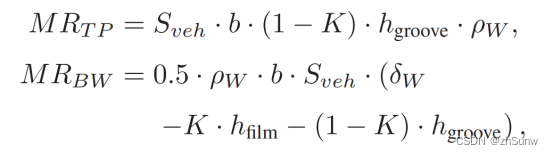
Reconstruction and Synthesis of Lidar Point Clouds of Spray
随机推荐
CMT2380F32模块开发3-GPIO例程
CMT2380F32模块开发2-IDE软件配置
umi约定式路由规则修改
Argparse模块 学习
Promise 中状态改变和回调执行先后顺序 和promise多次回调
MSP430学习总结(二)——GPIO
net6 的Web MVC项目中事务功能的应用
Node-2.垃圾回收机制
CNN-based Point Cloud De-Noising
Maykle Studio - HarmonyOS Application Development Fourth Training
2021-09-11 C语言 变量与内存分配
The latest safety helmet wearing recognition system in 2022
物联网IOT 固件升级
产品如何拟定优化方案?
Maykle Studio - HarmonyOS Application Development First Training
vim 编辑解决中文乱码问题
华为IOT平台温度过高时自动关闭设备场景试用
论文解读:GAN与检测网络多任务/SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
产品经理的基础知识
产品版本号是如何确定的