当前位置:网站首页>Node-3.构建Web应用(二)
Node-3.构建Web应用(二)
2022-08-11 05:23:00 【想要成为程序媛的DUDUfine】
文章目录
前言
在Web应用的整个构建过程中,随着框架和库的成型,我们往往迷糊地知道应用框架和库,而不知道细节的实现。这篇文章简要介绍在Web应用中设计的原理性知识及技术,对认识一个Web应用的具体实现有相对具体而全面的了解,可以帮助我们去学习和思考其他框架和库的实现、
一、数据上传
Node的HTTP请求在HTTP_Parser解析报文头结束后,报文内容部分会通过data事件触发,我们只需要以流的方式处理即可。
表单数据
默认的表单提交,请求头中的Content-Type字段值为application/x-www-form-urlencoded
其他格式
JSON类型请求头中的Content-Type字段的值为application/json;
XML类型请求头中的Content-Type字段的值为application/xml;
在Content-Type中可以附带编码信息。Content-Type: application/json; charset=utf-8
附件上传
通常的表单,其内容可以通过urlencoded的方式编码内容形成报文体,再发送给服务器端,
特殊表单可以含有file类型的控件,以及需要指定表单属性enctype为multipart/form-data;
浏览器在遇到multipart/form-data表单提交时,构造的请求报文与普通表单完全不同。
Content-Type: multipart/form-data; boundary=AaB03x
Content-Length: 18231
它代表本次提交的内容是由多部分构成的,其中boundary=AaB03x指定的是每部分内容的分界符,AaB03x是随机生成的一段字符串,报文体的内容将通过在它前面添加–进行分割,报文结束时在它前后都加上–表示结束。另外,Content-Length的值必须确保是报文体的长度。
数据上传与安全
内存限制
在解析表单、JSON、XML部分,如果使用先保存用户提交的所有数据,然后再进行解析处理,最后才传递给业务逻辑的策略,一旦数据量过大,将发生内存被占光的情况,这种策略存在的潜在问题是它仅适合数据量小的提交数据。
攻击者通过客户端能够十分容易地模拟伪造大量数据,如果攻击者每次提交1 MB的内容,那么只要并发请求数量一大,内存就会很快地被吃光。
要文件上传会导致内存占光的问题,可以。
- 限制上传内容的大小,一旦超过限制,停止接收数据,并响应400状态码。
- 通过流式解析,将数据流导向到磁盘中,Node只保留文件路径等小数据。
采用的上传数据量进行限制可以通过Content-Length进行判断:
数据是由包含Content-Length的请求报文判断是否长度超过限制的,超过则直接响应413状态码;
对于没有Content-Length的请求报文,略微简略一点,在每个data事件中判定即可。一旦超过限制值,服务器停止接收新的数据片段。
如果是JSON文件或XML文件,极有可能无法完成解析。
对于上线的Web应用,添加一个上传大小限制十分有利于保护服务器,在遭遇攻击时,能镇定从容应对。
CSRF(跨站请求伪造)
CSRF(Cross-Site Request Forgery) 中文意思为跨站请求伪造。
以一个留言的例子来说明。假设某个网站有这样一个留言程序,提交留言的接口如下所示:
http://domain_a.com/guestbook
用户通过POST提交content字段就能成功留言。服务器端会自动从Session数据中判断是谁提交的数据,补足username和updatedAt两个字段后向数据库中写入数据,正常的情况下,谁提交的留言,就会在列表中显示谁的信息。
如果某个攻击者发现了这里的接口存在CSRF漏洞,那么他就可以在另一个网站(http://domain_b.com/attack)上构造了一个表单提交,如下所示:
<form id="test" method="POST" action="http://domain_a.com/guestbook">
<input type="hidden" name="content" value="vim是这个世界上最好的编辑器" />
</form>
<script type="text/javascript">
$(function () {
$("#test").submit();
});
</script>
这种情况下,攻击者只要引诱某个domain_a的登录用户访问这个domain_b的网站,就会自动提交一个留言。由于在提交到domain_a的过程中,浏览器会将domain_a的Cookie发送到服务器,尽管这个请求是来自domain_b的,但是服务器并不知情,用户也不知情。
以上过程就是一个CSRF攻击的过程。而这里的示例仅仅是一个留言的漏洞,如果出现漏洞的是转账的接口,那么其危害程度可想而知。
解决CSRF攻击可以添加随机值,在后端渲染的时候后台产生一个随机值,存放在表单中隐藏的input框,提交数据的时候一起提交到后台进行校验。
二、路由解析
文件路径型
静态文件
URL的路径与网站目录路径一致,无需转换,也非常直观。
这种路由的处理也很简单,将请求路径对于的文件发送给客户端即可。动态文件
在MVC流行起来前,Web服务器根据URL路径找到对应的文件,然后服务器根据文件后缀名寻找脚本解析器,并传入HTTP请求上下文(动态生成HTML页面)。
MVC
MVC模型的主要思想是将业务逻辑按职责分离,主要有:
- 控制器(Controller),一组行为的集合
- 模型(Model),数据相关的操作和封装
- 视图(View),视图的渲染
这是目前最为经典的分层模式,它的工作模式如下:
- 路由解析,根据URL寻找对应的控制器和行为;
- 行为调用相关的模型,进行数据操作
- 数据操作结束后,调用视图和相关数据进行页面渲染,输出到客户端
如何根据URL做路由映射?可以有两种实现方式:
- 手工关联映射(适合小项目),由对应的路由文件来将URL映射到对应的控制器,手工映射对URL比较灵活,可以通过正则匹配、参数解析等手动指定对应路径映射的控制器
缺点:如果URL变动,需要改动路由的映射。 - 通过自然关联映射,路由按照一种约定的方式自然而然地实现了路由,无须维护路由映射,如
/controller/action/param1/param2/param3
以/user/setting/12/1987为例,它会按约定去找controllers目录下的user文件,将其require出来,调用这个文件模块的setting()方法,而其余的值作为参数直接传递给这个方法。
这种自然映射的方式没有指明参数的名称,所以不能采用req.params的方式提取,直接通过路径上的参数获取。
RESTful
REST的全称是Representational State Transfer,表现状态转化。符合REST规范的设计,我们称为RESTful设计。
它的设计哲学主要将服务器端提供的内容实体看作一个资源,并表现在URL上。
地址代表一个资源,对资源的操作主要体现在HTTP请求方法上,而不是URL。
原来对用户增删查改的URL可能如下,操作行为主要体现在URL上,主要使用的请求方法是POST和GET:
POST /user/add?username=jacksontian
GET /user/remove?username=jacksontian
POST /user/update?username=jacksontian
GET /user/get?username=jacksontian
在RESTful的设计中是如下:
POST /user/jacksontian
DELETE /user/jacksontian
PUT /user/jacksontian
GET /user/jacksontian
它的设计引入了DELETE和PUT请求方法来参与资源的操作和更改资源的状态。
在RESTful设计中,资源的具体格式由请求报头中的Accept字段和服务器端的支持情况来决定。
如果客户端同时接受JSON和XML格式的响应,它的Accept字段值为:
Accept: application/json,application/xml
服务器端根据客户端请求头中Accept这个字段,再根据自身能响应的格式做出响应。
响应报文中通过Content-type字段告知客户端是什么格式。具体的格式,我们称之为具体的表现。
REST设计就是通过URL设计资源、请求方法定义资源的操作,通过Accept决定资源的表现形式。
RESTful与MVC的设计并不冲突,而是更好的改进。
相比MVC,RESTful只是将HTTP请求方法也加入了路由的过程,以及在URL路径上体现得更资源化。
三、中间件
在最早的中间件的定义中,它是一种在操作系统上为应用软件提供服务的计算机软件。它既不是操作系统的一部分,也不是应用软件的一部分,它处于操作系统与应用软件之间,让应用软件更好、更方便地使用底层服务。
如今中间件的含义借指了这种封装底层细节,为上层提供更方便服务的意义。
在Web应用中指的中间件,就是封装了HTTP请求细节处理的中间件,简化和隔离这些基础设施与业务逻辑之间的细节,开发者可以脱离这部分细节而专注在业务上。
中间件的行为类似Java中的过滤器(filter)的工作原理,在进入具体的业务处理之前,先让过滤器处理。工作模型如下图: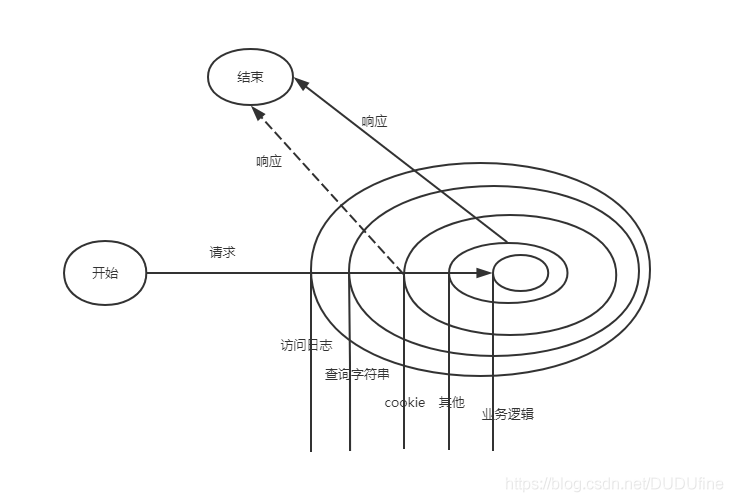
从HTTP请求到具体业务逻辑之间,其实有很多细节要处理。
Node的http模块提供了应用层协议网络的封装,对具体业务并没有支持(比如日志、请求处理、鉴权等等),在业务逻辑下,必须有开发框架对业务提供支持。
通过中间件的形式搭建开发框架,这个开发框架用来组织各个中间件。对于Web应用的各种基础功能,通过中间件处理相对简单的逻辑最终汇成强大的基础框架。
由于Node是异步的原因,需要提供一种机制,可以在当前中间件中处理完成后,通知下一个中间件执行。可以采用Connect的设计,通过尾触发的方式实现。如:
var middleware = function (req, res, next) {
// TODO
next();
}
通过框架支持,可以将所有的基础功能支持串联起来,如下:
app.use('/user/:username', querystring, cookie, session, function (req, res) {
// TODO
});
use()中将中间件都存进stack数组中保存,等待匹配后触发执行。
每个中间件执行完成后,按照约定调用传入next()方法触发下一个中间件执行(或直接响应),直到最后的业务逻辑。
为每个路由都配置中间件看起来并不是很友好,如:
app.get('/user/:username', querystring, cookie, session, getUser);
app.put('/user/:username', querystring, cookie, session, updateUser);
//更多路由
中间件既然是对业务逻辑的封装,那中间件和业务逻辑是等价的,我们可以将路由和中间件进行结合,这样的设计看起来会更加简洁友好 ,如上面的配置可以写成:
app.use(querystring);
app.use(cookie);
app.use(session);
app.get('/user/:username', getUser);
app.put('/user/:username', authorize, updateUser)
中间件和路由的协作,可以将复杂的处理过程进行简化,让Web应用开发者可以只关注业务开发就可以完成整个复杂的开发工作。
异常处理
为了保证Web应用的稳定性和健壮性,如果中间件出现错误,应该要进行处理捕获。
由于中间件是使用尾调用的方式实现 ,我们可以为next()方法添加err参数,并捕获中间件直接抛出的同步异常。
由于异步方法的异常不能直接捕获,所以对于中间件异步产生的异常需要自己传递出来,如下:
var session = function (req, res, next) {
var id = req.cookies.sessionid;
store.get(id, function (err, session) {
if (err) {
// 将异常通过next()传递
return next(err);
}
req.session = session;
next();
});
};
Next()方法接到异常对象后,会将其交给handle500()进行处理。
为了延续中间件的思想,异常处理的中间件也是可以采用数组式进行处理。
因为要同时传递异常,所以用于处理异常的中间件的设计与普通中间件略有区别。它的参数有4个:
var middleware = function (err, req, res, next) {
// TODO
next();
};
通过use()可以将所有异常处理的中间件注册起来,如下:
app.use(function (err, req, res, next) {
// TODO
});
为了区分普通中间件和异常处理中间件,handle500()方法将会对中间件按参数进行进行选取,然后递归执行。
var handle500 = function (err, req, res, stack) {
// 选取异常处理中间件
stack = stack.filter(function (middleware) {
return middleware.length === 4;
});
var next = function () {
// 从stack数组中取出中间件并执行
var middleware = stack.shift();
if (middleware) {
// 传递异常对象
middleware(err, req, res, next);
}
};
// 启动执行
next();
};
中间件与性能
在中间件中我们的业务逻辑 往往是最后才执行的,为了可以让业务逻辑尽早提前执行响应给终端用户,所以中间件的编写和使用需要进行考究,主要从两个方面进行提升:
一. 编写高效的中间件
高效的中间件就是提升单个处理单元的处理速度,以尽早调用next() 执行后续逻辑。一旦中间件被匹配,那个每个请求都会使该中间件执行一次,即使只耗费1豪秒的执行时间,也会使QPS显著下降。
- 使用高效的方法,必要时通过jsperf.com测试基准性能
- 缓存需要重复计算的结果(需要控制缓存用量,防止内存达到限制)
- 避免不必要的计算,比如HTTP报文体的解析 ,对GET方法完全不需要。
二. 合理利用路由,避免不必要的中间件执行
合理使用路由,不必要的路由不参与请求处理过程,比如
我们有一个静态文件的中间件,它会对请求进行判断,如果磁盘上存在对应文件就会响应对应的静态文件,否则就交由下游中间件处理,
如果使用如下方式注册路由:app.use(staticFile);
那么意味着对 / 路径下的所有URL请求都会进行判断,对于没不能成功匹配的更是造成了性能的浪费,使QPS直线下降。
所以需要提高匹配成功率,不能使用默认的 / 路径来匹配,这个不匹配造成的性能 浪费代价太高,可以添加一个更好的路由路径,如下:app.use('/public',staticFile);
这样 只有/public路径会匹配上,其余路径不会涉及该中间件。
所以,对于中间件来说,它是对及基础功能收敛成规整的组织形式。对于单个中间件来说,它应该足够简单,职责单一,具备更好的可测试性。
中间件机制使得Web应用具备良好的可扩展性和可组合性。中间件是Connect的经典模式。
四、内容响应和页面渲染
服务器端的响应有可能是一个HTML网页、CSS、JS文件,或者其他多媒体文件。
对于过去流行的ASP、PHP、JSP等动态网页技术,页面渲染是一种内置的功能。但对于Node来说并没有这样的内置功能。
内容响应
http模块封装了对请求报文和响应报文的操作。服务器端响应的报文,最终都要被终端处理。这个终端可能是命令行终端,也可能是代码终端,也可能是浏览器。
服务器端的响应从一定程度上决定或指示了客户端该如何处理响应的内容。
内容响应的过程,响应报头中的Content-*字段十分重要。如下的响应报文中,服务端告诉客户端内容是以gzip编码的,其内容长度为21170个字节,内容类型为JavaScript,字符集为UTF-8:
Content-Encoding: gzip
Content-Length: 21170
Content-Type: text/javascript; charset=utf-8
客户端在接受到这个报文后,会通过gzip来解码报文体中的内容,用长度校验报文体内容是否正确,然后再以字符集UTF-8将解码后的脚本插入到文档节点中。
MIME
浏览器通过不同的Content-Type的值来决定采用不同的渲染方式,这个值简称为MIME值。
MIME的全称是Multipurpose Internet Mail Extensions(多功能互联网邮件扩展),从名字可以看出最早用于电子邮件,后来也应用到浏览器中。
不同的文件类型具有不同的MIME值,如:
JSON文件的值为application/json、
XML文件的值为application/xml、
PDF文件的值为application/pdf
除了MIME值外,Content-Type的值中还可以包含一些参数,如字符集:
Content-Type: text/javascript; charset=utf-8
社区有专用的mime模块可以用来判断文件类型。
附件下载
在一些场景下,无论响应的内容是什么样的MIME值,需求中并不要求客户端去打开它,只需要弹出并下载它即可。
Content-Disposition字段正是为了满足这种需求,该字段影响的行为是客户端会根据它的值判断是应该将报文数据当做即时浏览的内容,还是可以下载的附件。
Content-Disposition: inline // 内容只需即时查看
Content-Disposition: attachment //数据可以存为附件
另外,Content-Disposition字段还能通过参数指定保存时应该使用的文件名。示例如下:
Content-Disposition: attachment; filename="filename.ext"
如果要设计一个响应附件下载的API(res.sendfile),方法大致是如下这样的:
res.sendfile = function (filepath) {
fs.stat(filepath, function(err, stat) {
var stream = fs.createReadStream(filepath);
// 设置内容
res.setHeader('Content-Type', mime.lookup(filepath));
// 设置长度
res.setHeader('Content-Length', stat.size);
// 设置为附件
res.setHeader('Content-Disposition' 'attachment; filename="' + path.basename(filepath) + '"');
res.writeHead(200);
stream.pipe(res);
});
};
响应JSON
为了快捷地响应JSON数据,我们也可以如下这样进行封装:
res.json = function (json) {
res.setHeader('Content-Type', 'application/json');
res.writeHead(200);
res.end(JSON.stringify(json));
};
响应跳转
当我们的URL因为某些问题(譬如权限限制)不能处理当前请求,需要将用户跳转到别的URL时,我们也可以封装出一个快捷的方法实现跳转,如下所示:
res.redirect = function (url) {
res.setHeader('Location', url);
res.writeHead(302);
res.end('Redirect to ' + url);
};
视图渲染
Web的响应有很多种,包括附件和跳转等,而对于普通HTML内容响应,最终呈现在界面上的内容,称为视图渲染。
在动态页面技术中,最终的视图是由模板和数据共同生成出来的。
模板是带有特殊标签的HTML片段,通过与数据的渲染,将数据填充到这些特殊标签中,最后生成普通的带数据的HTML片段。
通常我们将渲染方法设计为render(),参数就是模板路径和数据,如下所示:
res.render = function (view, data) {
res.setHeader('Content-Type', 'text/html');
res.writeHead(200);
// 实际渲染
var html = render(view, data);
res.end(html);
};
在Node中,数据自然是以JSON为首选,但是模板却有太多选择可以使用了。上面代码中的render()我们可以将其看成是一个约定接口,接受相同参数,最后返回HTML片段。这样的方法我们都视作实现了这个接口。
模板
最早的服务器端动态页面开发,是在CGI程序或servlet中输出HTML片段,通过网络流输出到客户端,客户端将其渲染到用户界面上。
这种逻辑代码与HTML输出的代码混杂在一起的开发方式,导致一个小小的UI改动都要大动干戈,甚至需要重新编译。
为了改良这种情况,使HTML与逻辑代码分离开来,催生出一些服务器端动态网页技术,如ASP、PHP、JSP。它们将动态语言部分通过特殊的标签(ASP和JSP以<% %>作为标志,PHP则以<? ?>作为标志)包含起来,通过HTML和模板标签混排,将开发者从输出HTML的工作中解脱出来。它们其实就是最早的模板技术。
这样的方法虽然一定程度上减轻了开发维护的难度,但是页面里还是充斥着大量的逻辑代码。这催生了MVC在动态网页技术中的发展,MVC将逻辑、显示、数据分离开来的方式,大大提高了项目的可维护性。其中模板技术就在这样的发展中逐渐成熟起来的。
模板技术的实质就是将模板文件和数据通过模板引擎生成最终的HTML代码。
形成模板技术的有如下4个要素。
- 模板语言。
- 包含模板语言的模板文件。
- 拥有动态数据的数据对象。
- 模板引擎。
由于各种语言采用的模板语言不同,包含各种特殊标记,导致移植性较差。
早期的企业一旦选定编程语言就不会轻易地转换环境,所以较少有开发者去开发新的模板语言和模板引擎来适应不同的编程语言。如今异构系统越来越多,模板能够应用到多门编程语言中的这种需求也开始呈现出来。
破局者是Mustache,它宣称自己是弱逻辑的模板(logic-less templates),定义了以{ {}}为标志的一套模板语言。
随着Node在社区的发展,与模板引擎相关模块的实现多不胜数,并且由于Node与前端都采用相同的执行语言JavaScript,所以一套模板语言也无须为它编写两套不同的模板引擎就能轻松地跨前后端共用。
模板和数据与最终结果相比,这里有一个静态、动态的划分过程,相同的模板和不同的数据可以得到不同的结果,不同的模板与相同的数据也能得到不同的结果。
模板技术使得网页中的动态内容和静态内容变得不互相依赖,数据开发者与模板开发者只要约定好数据结构,两者就不用互相影响了。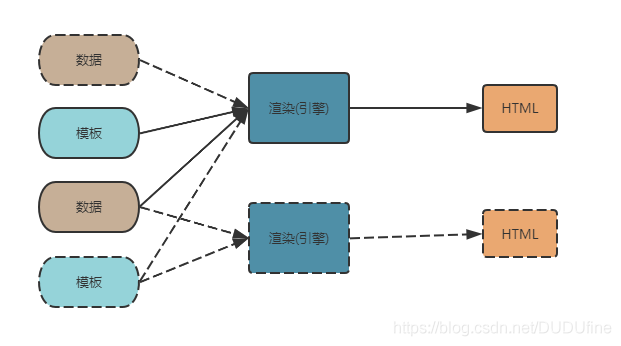
模板技术干的实际上是拼接字符串这样很底层的活,只是各种模板有着各自的优缺点和技巧。我们要的就是模板加数据,通过模板引擎的执行就能得到最终的HTML字符串这样结果。
假设我们的模板是如下这样,<% =%>就是我们制定的模板标签
Hello <%= username%>
如果我们的数据是{username: “JacksonTian”},那么我们期望的结果就是Hello JacksonTian。
具体实现的过程是模板分为Hello和<%= username%>两个部分,前者为普通字符串,后者是表达式。表达式需要继续处理,与数据关联后成为一个变量值,最终将字符串与变量值连成最终的字符串。
渲染过程为: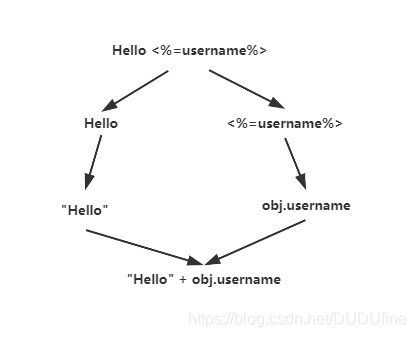
模板引擎
模板引擎的流程大致为:
- 语法分解。提取出普通字符串和表达式,这个过程通常用正则表达式匹配出来,<%=%>的正则表达式为/<%=([\s\S]+?)%>/g。
- 处理表达式。将标签表达式转换成普通的语言表达式。
- 生成待执行的语句。
- 与数据一起执行,生成最终字符串。
模板编译
与数据一起执行,生成最终字符串,这个过程称为模板编译,生成的中间函数只与模板字符串相关,与具体的数据无关。
如果每次都生成这个中间函数,就会浪费CPU。为了提升模板渲染的性能速度,我们通常会采用模板预编译的方式。
通过预编译缓存模板编译后的结果,实际应用中就可以实现一次编译,多次执行,而原始的方式每次执行过程中都要进行一次编译和执行。
with的应用
模板安全
模板编译会把普通字符串直接输出,变量标签替换成变量如obej[code], 如果变量是恶意脚本字符串就会构成XSS漏洞,在执行脚本的时候产生安全问题。
为了提高安全性,所以大多数模板会提供转义功能,将能形成HTML标签的字符串转换成安全的字符,这些字符主要有&、<、>、"、 ’ 等 ,把这些字符进行转义。
不确定要输出HTML标签的字符最好都转义,特别是用户的输入内容。
可以使用不同的标签区别表示转义和非转义,比如:<%=%>和<%-%>
模板逻辑
尽管模板技术将业务逻辑与视图部分分离开来,但是在视图上允许使用一些逻辑来控制页面的最终渲染,可以让模板变得更强大。
集成文件系统
对于客户端的请求我们如果每次都需要对对应的文件进行编译然后再渲染,这样会造成:
- 每次请求都需要反复读磁盘上的模板文件
- 从每次请求都需要编译
- 调用繁琐
所以我们需要更简洁、性能更好的render()函数。可以使用缓存将请求编译过的文件缓存起来,这样就不会再反复地读取和编译文件了,调用起来也很轻松。
这样与文件系统集成并且引入缓存,可以很好地解决性能问题,接口也可以得到简化,而且模板文件内容不大,也不属于动态改动,所以使用进程内存缓存编译结果,并不会引起太大的垃圾回收问题。
子模版
有时候模板文件太大,太过复杂,会增加维护难度,而且有些模板是可以重用的,所以产生了子模版。
子模版可以嵌套在别的模板中,维护多个子模版比维护完整而复杂的大模板容易一些,可以将复杂的问题降解为多个小而简单的问题。
布局视图
布局视图又称母版页,它与子模版的原理相同,当页面内容有所差别,但是页面布局相同,就可以将布局模板重用起来,子模版嵌入布局模板中使用。
模板性能
模板引擎的优化主要有以下几种:
- 缓存模板文件
- 缓存模板文件编译后的函数
- 优化模板中的执行表达式
在完成前面两步后,渲染的性能就与生成的函数直接相关,这个函数与模板字符串的复杂度*有直接关系。
如果在模板中编写了执行表达式,执行表达式的性能将直接影响模板的性能。优化执行表达式就是对模板性能的优化。
模板引擎的实现方式也会影响到性能。比如用new Function()生成函数,还可以用eval();
对于字符串的处理,可以使用字符串直接相加,也可以采用数组存储的 方式,最后将所有字符串直接相连;
对于变量的查找,有的使用with形成作用域的方式实现查找,也可以使用变量名进行查找,这样相比with不用切换上下文。
这些都是影响模板的速度的因素。
Bigpipe
Bagpipe的翻译为风笛,是用于调用限流。它是产生于Facebook公司的前端加载技术,它的提出主要是为了解决重数据页面的加载速度问题。
举个例子,当我们要获取用户主页的时候,需要获取用户的数据和用户历史文章列表,那可以同时异步并行请求多个接口的数据,拿到相关数据后再填充到模板上返回客户端。但是在页面组装好数据返回到客户端之前,用户看到的都是空白的页面,这样是十分不友好的体验。
Bigpipe的解决思路是将页面分割成多个部分(pagelet),先向用户输出没有数据的布局(框架),将每个部分逐步输出到前端,在最终渲染填充框架,完成整个页面的渲染。这个过程需要前端JavaScript的参与,它负责将后续输出的数据渲染到页面上。
Bigpipe是一个需要前后端配合实现的优化技术,这个技术有几个重要点:
页面布局框架(无数据的)
在布局文件中需要引入必要的前端脚本,以及需要到的库,其次要引入我们重要的前端脚本,命名为Bigpipe.js,文件内容大致为:var Bigpipe=function(){ this.callbacks={}; } Bigpipe.prototype.ready=function(key,callback){ if(!this.callbacks[key]){ this.callbacks[key]=[]; } this.callbacks[key].push(callback); } Bigpipe.prototype.set=function(key,data){ var callbacks=this.callbacks[key]||[]; for(var i=0;i<callbacks.length;i++){ callbacks[i].call(this, data); } }后端持续性的数据输出
在模板输出后,整个页面的渲染并没有结束,但用户已经可以看到整个页面大体的样子,然后再继续数据输出。数据异用调用后先返回的数据可以先推送到页面上,不过和普通数据输出不同,这里的数据输出之后需要被前端脚本处理,所以需要对它进行封装处理。把数据用js脚本的形式返回页面执行,然后bigpipe对象拿到对应的数据再渲染到页面上。db.getData('sql1', function (err, data) { data = err ? {} : data; res.write('<script>bigpipe.set("articles", ' + JSON.stringify(data) + ');</script>'; });前端渲染
Bigpipe.ready()和Bigpipe.set()是整个前端的渲染机制,前者用一个key注册时间,后者则触发一个事件,以此完成页面的渲染机制。
Bigpipe这样一个逐步渲染页面的过程,其实通过Ajax也能完成,但是Ajax背后是HTTP调用,要耗费更多的网络连接,而Bigpipe获取数据则与当前页面共用相同的网络连接,开销十分小。
不过完成Bigpipe要设计的细节比较多,比MVC中的直接渲染要复杂许多,所以建议在重要且数据请求时间比较长的页面中使用。
边栏推荐
- 关于安全帽识别系统,你需要知道的选择要点
- LiDAR Snowfall Simulation for Robust 3D Object Detection
- 跳转到微信小程序方法
- 【高德地图】易采坑合集
- The working principle and industry application of AI intelligent image recognition
- 【docker-compose】mysql安装
- CVPR2022——A VERSATILE MULTI-VIEW FRAMEWORK
- GBase 8s分片技术介绍
- 基于ijkplayer 0.8.8编译的完整so. libijkffmpeg.so等,支持ssl h265, rm, rmvb
- 梅科尔工作室-HarmonyOS应用开发的第二次培训
猜你喜欢
MPLS 实验
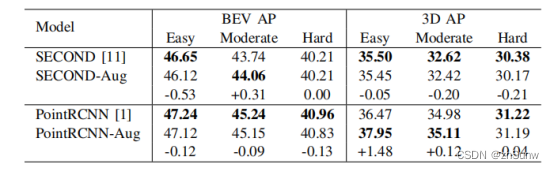
Robust 3D Object Detection in Cold Weather Conditions
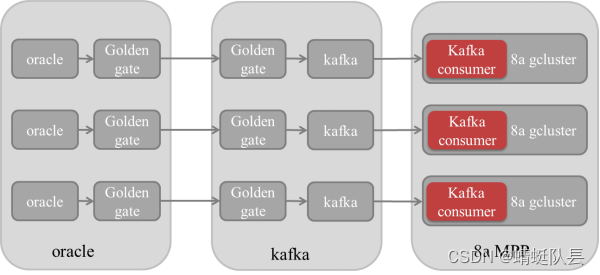
GBase 8a MPP Cluster产品高级特性
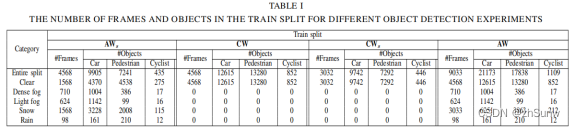
Rethinking LiDAR Object Detection in adverse weather conditions
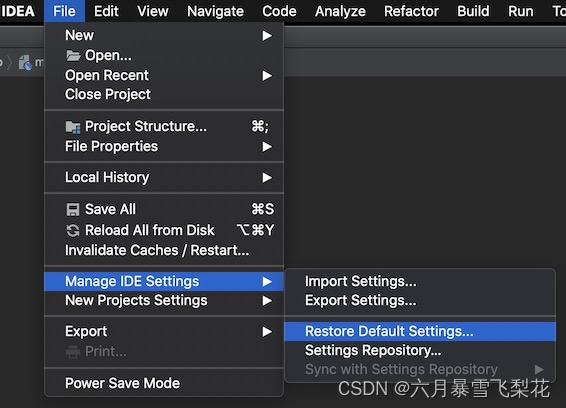
>>开发工具:IDEA格式化代码无效
Mei cole studios - fifth training DjangoWeb application framework + MySQL database

CNN-based Point Cloud De-Noising
CVPR2022——A VERSATILE MULTI-VIEW FRAMEWORK
【sqlyog】【mysql】csv导入问题
Introduction of safety helmet wearing recognition system
随机推荐
梅科尔工作室-HarmonyOS应用开发的第二次培训
LAGRANGIAN FLUID SIMULATION WITH CONTINUOUS CONVOLUTIONS
TAMNet:A loss-balanced multi-task model for simultaneous detection and segmentation
SQL注入
内核与用户空间通过字符设备通信
经纬度距离
解决SmartRefreshLayout/SwipeRefreshLayout与RecyclerView下拉冲突的问题
>>开发工具:IDEA格式化代码无效
Socket 网络协议 等
OSI TCP/IP学习笔记
@2022-02-22:每日一语
目标检测——LeNet
Robust 3D Object Detection in Cold Weather Conditions
CNN-based Point Cloud De-Noising
Safety helmet recognition system
GBase 8s的多线程结构
梅科尔工作室-PR第三次培训笔记(效果与转场及插件使用)
梅科尔工作室-DjangoWeb 应用框架+MySQL数据库第四次培训
微信小程序部分功能细节
Introduction of safety helmet wearing recognition system