当前位置:网站首页>swin-transformer训练自己的数据集<自留>
swin-transformer训练自己的数据集<自留>
2022-08-11 05:23:00 【壹万1w】
前期准备(数据处理)
标注数据集
LabelMe----> COCO
- LabelImg:能标注 VOC、YOLO格式数据集,标注VOC数据集尤其推荐
- 安装:
pip install labelimg -i [http://mirrors.aliyun.com/pypi/simple/](http://mirrors.aliyun.com/pypi/simple/) --trusted-host mirrors.aliyun.com - 启动: 直接在命令中输入 labelimg 启动软件
- ①勾选 View - Auto Save mode:这样切换到下一张图时就会将标签文件自动保存在Change Save Dir设定的文件夹。
②Open Dir:选择图片所在的文件夹 JPEGimages
③Change Save Dir:选择保存标签文件要保存的目录 Annotations - 快捷键
A:上一张图
D:下一张图
W:绘制矩形框
** LabelImg----> VOC **
- LabelMe:格式为LabelMe,提供了转VOC、COCO格式的脚本,可以标注矩形、圆形、线段、点。标注语义分割、实例分割数据集尤其推荐。
- 安装:
pip install labelme -i [http://mirrors.aliyun.com/pypi/simple/](http://mirrors.aliyun.com/pypi/simple/) --trusted-host mirrors.aliyun.com - 启动: 直接在命令行输入 labelme 启动软件
- ①勾选 File->Automatically:这样切换到下一张图时就会将标签文件自动保存在Change Save Dir设定的文件夹。
②Open Dir:选择图片所在的文件夹 JPEGimages
File-> Change Output Dir:选择保存标签文件所在的目录 Annotations
③Edit -> Create Rectangle:选中,开始画矩形框
④注:如果想删除某个框,需要先点击左侧 Edit Polygons,然后再选择你要删的框,点击del键 - 快捷键
A:上一张图
D:下一张图
Ctrl + R:画矩形框
VOC 转COCO
在github上下载运行,把voc数据集改为CoCo数据集
注:把数据在网站中格式化处理,可以看到数据集中的每个类别
一、结构目录
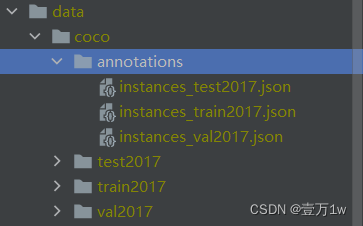
annotations下包含的是标签文件,分别有测试集(test)训练集(train)验证集(val)中间包含文件信息,目标位置信息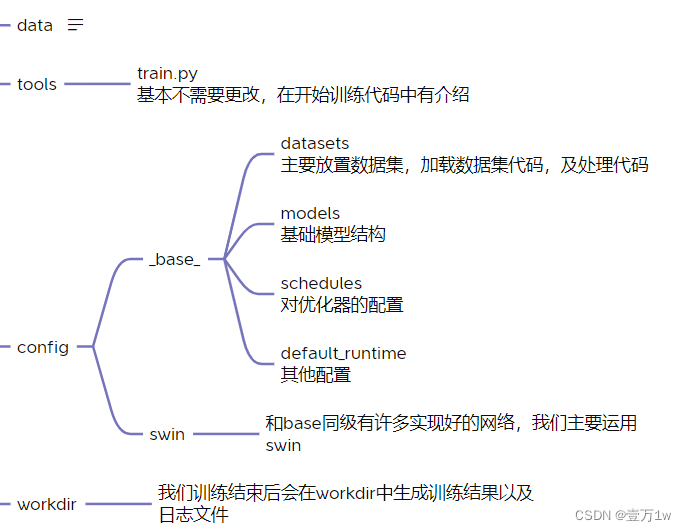
二、要修改的地方

- 类别 修改configs/base/models/mask_rcnn_swin_fpn.py中的num_classes
#num_classes=80,#类别
num_classes=4,#类别改为4 我们训练的类别是4
配置权重信息 修改 configs/base/default_runtime.py 中的 interval,loadfrom
interval:dict(interval=1) # 表示多少个 epoch 验证一次,然后保存一次权重信息
loadfrom:表示加载哪一个训练好(预训练)的权重,可以直接写绝对路径如:load_from = r"E:\workspace\Python\Pytorch\Swin-Transformer-Object-Detection\mask_rcnn_swin_tiny_patch4_window7.pth"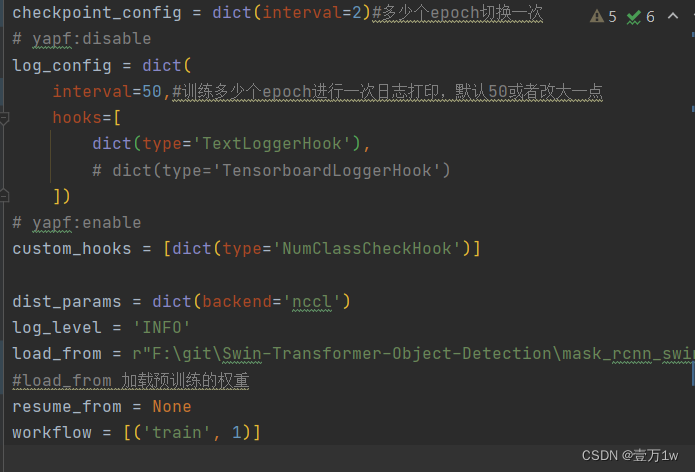
修改训练图片尺寸大小:如果显存够的话可以不改(基本都运行不起来),文件位置为:configs/swin/mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_adamw_3x_coco.py
修改所有的 img_scale 为 :img_scale = [(224, 224)] 或者 img_scale = [(256, 256)] 或者 480,512等。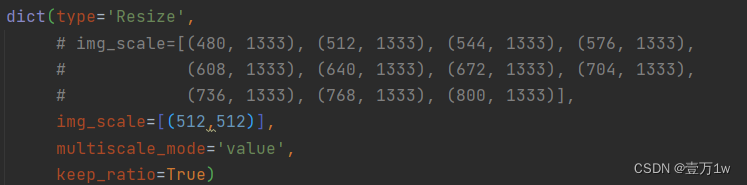
同时 configs/base/datasets/coco_instance.py 中的 img_scale 也要改成 img_scale = [(224, 224)] 或者其他值
注意:值应该为32的倍数,大小根据显存或者显卡的性能自行调整
- 配置数据集路径:configs/base/datasets/coco_instance.py
修改data_root文件的最上面指定了数据集的路径,因此在项目下新建 data/coco目录,下面四个子目录 annotations和test2017,train2017,val2017。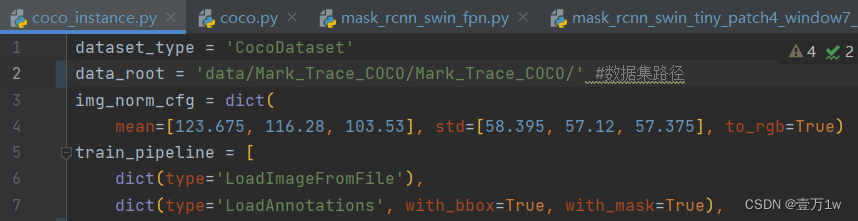
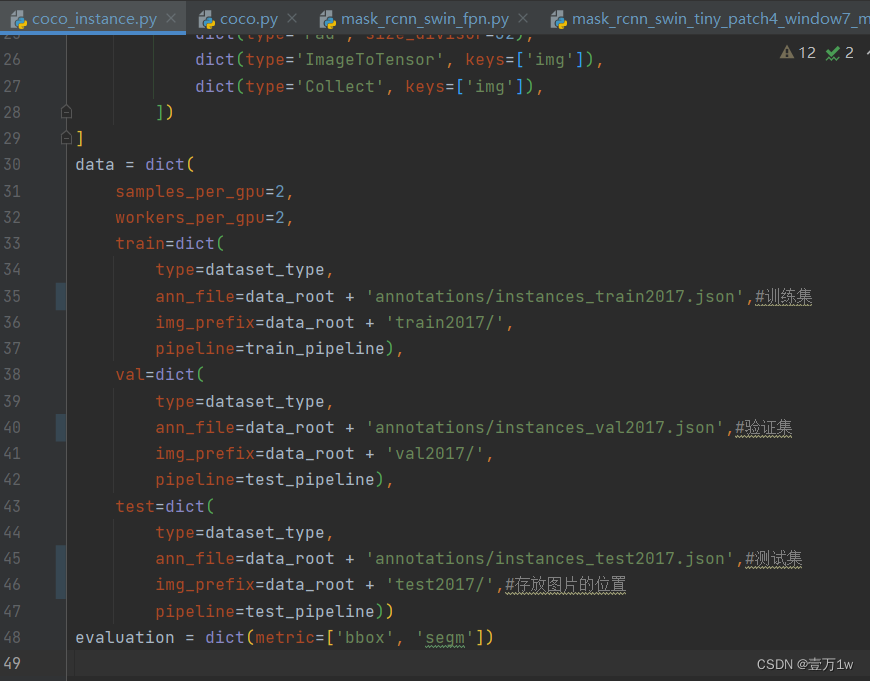
- 修改该文件下的 train val test 的路径为自己新建的路径:configs/base/datasets/coco_instance.py
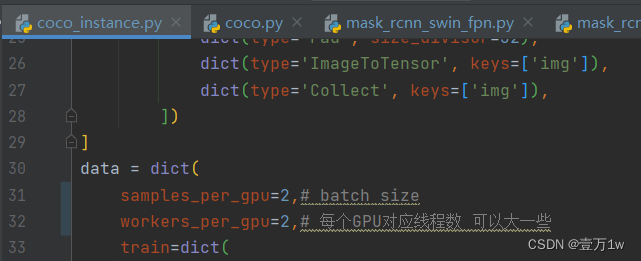
- 修改 batch size 和 线程数,路径:configs/base/datasets/coco_instance.py ,根据自己的显存和CPU来设置
samples_per_gpu=8, # batch size
workers_per_gpu=4, # 每个GPU对应线程数 可以大一些
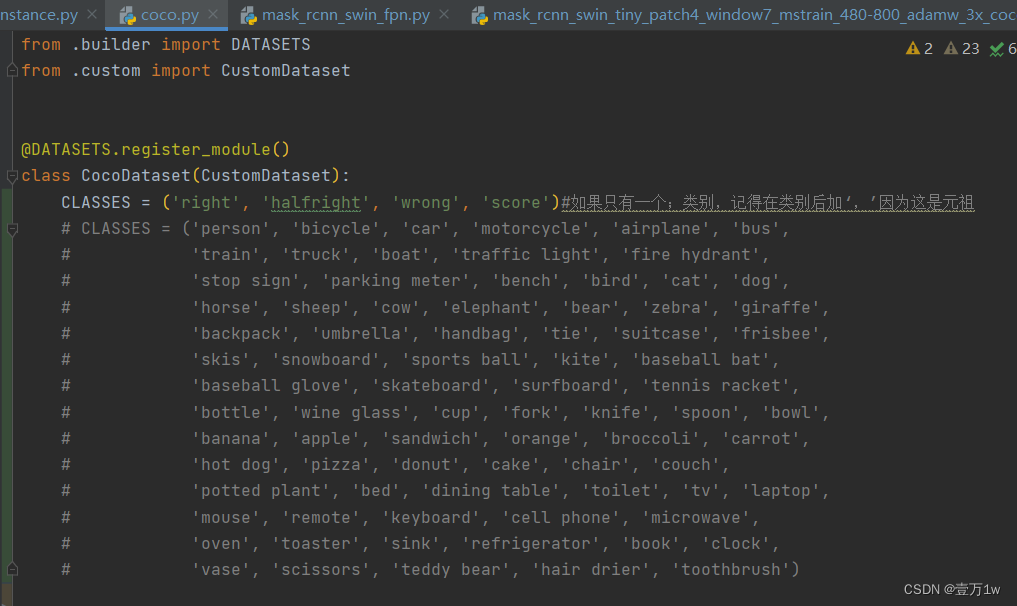
7. 修改分类数组:mmdet/datasets/coco.py
CLASSES中填写自己的分类:
CLASSES = ('person', 'bicycle', 'car')
8. 修改最大epoch configs/swin/mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_adamw_3x_coco.py
修改72行:runner = dict(type=‘EpochBasedRunnerAmp’, max_epochs=36)#最大epochs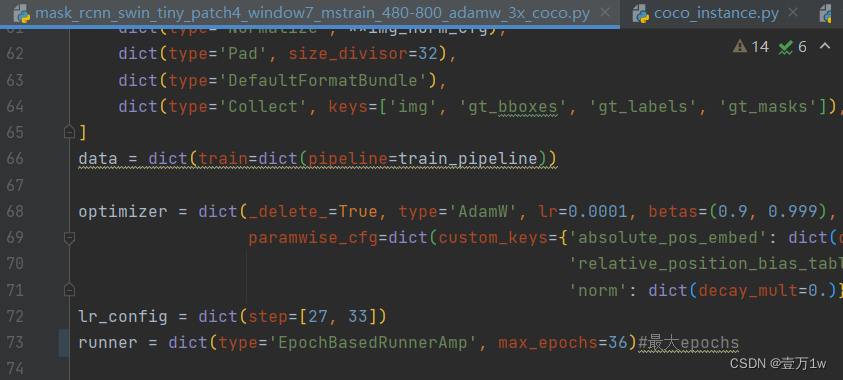
三、开始训练
在终端输入
python tools/train.py configs\swin\mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_adamw_3x_coco.py
解释:执行tools下train.py文件——传入configs\swin\mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_adamw_3x_coco.py 这个参数(这个参数就是我们要使用的网络)
四、训练过程结果
- 每50个打印一次日志信息,后边有学习率和loss信息

- 最后生成结果,会在项目根目录下生成work_dirs文件夹
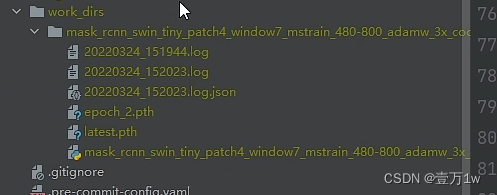
log:保存训练时终端打印的日志
epoch.pth:我们得到的权重文件
lastest.pth:最新保存的权重文件
边栏推荐
猜你喜欢





随机推荐
恶劣天气 3D 目标检测数据集收集
xss.haozi靶场通关
【mysql】查询不区分大小写(用户密码登录不区分大小写)
安全帽识别系统
mysql 间隙锁(GAP-LOCK)演示
GBase 8s分片技术介绍
MGRE实验
Zhejiang University School of Software 2020 Guarantee Research Computer Real Question Practice
安全帽识别系统-为安全生产保驾护航
Introduction of safety helmet wearing recognition system
TAMNet:A loss-balanced multi-task model for simultaneous detection and segmentation
Joint 3D Instance Segmentation and Object Detection for Autonomous Driving
mAPH——Waymo数据集
通过字符设备虚拟文件系统实现kernel和userspace数据交换(基于kernel 5.8测试通过)
>>开发工具:IDEA格式化代码无效
梅科尔工作室-HarmonyOS应用开发第四次培训
Toward a Unified Model
CVPR2022——A VERSATILE MULTI-VIEW FRAMEWORK
梅科尔工作室-HarmonyOS应用开发的第二次培训
Solutions to the 7th Jimei University Programming Contest (Individual Contest)