当前位置:网站首页>数据库内核面试中我不会的问题(4)
数据库内核面试中我不会的问题(4)
2022-08-11 10:13:00 【Aiky哇】
真的是面的最难的一次了,,确实全是数据库内核的,确实全是执行器和查询优化相关的,但是说出来就是不会啊,这种自己在擅长的方面被人吊起来锤的感觉让人很难过。
我也没有完全记住他面试中问了我哪些问题,先列出来这几个吧。
1.执行器的架构有哪几种?
1.最为常见的是传统的火山模型,以及一系列的优化,比如说pull模型改为push模型的优化。
优点:简单,每个 Operator 可以单独实现逻辑。
缺点:查询树调用next()接口次数太多,并且一次只取一条数据,CPU 执行效率低;而 Joins, Subqueries, Order By 等操作经常会阻塞。
2.然后是Materialization,物化模型,每个算子一次处理所有的输入,处理完之后将所有结果一次性输出。
物化模型更适合OLTP负载,这些查询每次只访问小规模的数据,只需要少量的函数调用。
3.向量化模型,是火山模型和物化模型的折衷。
向量化模型比较适合 OLAP 查询,因为其大大减少了每个 operator 的调用次数,也就简单减少了虚函数的调用。
2.执行器算子之间,使用批量传递数据比起按行传递数据的好处有哪些?坏处有哪些?
这个我确实也不知道正确答案,我搜到的坏处是,使用批量处理会降低在批处理期间的交互性。
但是我觉得这个比起来批处理带来的好处,显得也不是特别明显了。
- 批处理适用于对大量静态数据进行处理,需要等到整个分析处理结束才能获得结果(即获得最终分析处理结果的延迟较大)。一般应用于实时性要求不高,离线计算的场景下。
- 流处理适用于对每个新到达的(动态的)数据元素(Data Element)或者一个比较小的时间窗口内的数据元素进行计算,数据上的计算或者分析处理相对来讲是比较简单的,因此完成分析处理的时间非常迅速。一般应用于时效性要求比较高的场景。
这么来看的话,面试官应该问的是两种处理方式的处理场景的差异。
所以我应该回答的是批处理应对实时性要求比较高的场景,处理效果是比不上行传递处理的。
3.讲一下MPP架构?
(当时谈到了我们这边的数据库整体架构,我说我们这边是上层多个cn,下层多个dn的情况。然后面试官问我是不是mpp架构,我说是,我理解的mpp就是并行计算架构,当时不太懂,,后来细问就觉得不对了,我们这架构dn之间没有数据交互,所以其实不能算mpp)
MPP (Massively Parallel Processing),即大规模 并行处理。
MPP 处理数据的思路
面对海量数据和计算时,采用大事化小的思路,对数据进行分割,数据分割后单独存储,数据处理消耗的资源也是相互隔开的,对于MPP数据库来讲,整个数据库由多个完全独立的数据库构成,各个拥有完整的数据存储、数据管理、数据操作能力。基于网络实现节点互联,形成一个整体对外提供服务,节点间互不干扰,即Share Nothing,不共享磁盘和计算能力。
MPP 具备以下技术特征
● 任务并行执行;
● 数据分布式存储(本地化);
● 分布式计算;
● 高可用、易维护:数据通过副本提供冗余保护,自动故障探测和管理,自动同步元数据和业务数据。提供图形化工具,以简化管理员对数据库的管理工作;
● 高并发:读写不互斥,支持数据的边加载边查询,单个节点并发能力大于 300 用户;
● 高扩展、高可靠:支持集群节点的扩容和缩容,支持全量、增量的备份/恢复;
● 行列混合存储:提供行列混合存储方案,从而提高了列存数据库特殊查询场景的查询响应耗时;
● 标准化:支持SQL92 标准,支持 C API、ODBC、JDBC、ADO.NET 等接口规范。
4.filter算子下推的情况有哪几种?
这个是对rbo的考察。
filter代表的是对数据的过滤条件,这里其实是在问什么情况下才能够提前过滤条件。或者是在问何时能够谓词下推。
谓词条件主要来自sql条件中的:where子句、having子句以及join on表达式。
where表达式中:
- 当select语句只涉及单个逻辑表时,在执行谓词下推优化过程中where对应的Selection条件直接下推至DataSource。
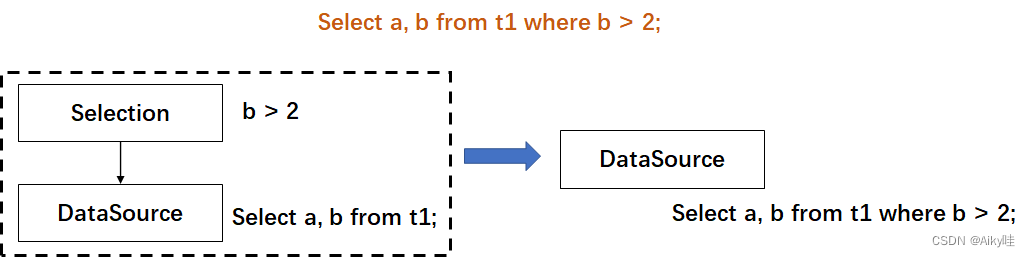
- 当select语句涉及多表join时,根据不同的join方式有不同的下推 :
条件 cross join inner join left join right join full join left table right table left table right table left table right table left table right table left table right table where predicate √ √ √ √ √ × × √ × ×
join条件表达式中:
| 条件 | cross join | inner join | left join | right join | full join | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| left table | right table | left table | right table | left table | right table | left table | right table | left table | right table | |
| join predicate | √ | √ | √ | √ | × | √ | √ | × | × | × |

having表达式中:
having谓词表达式作为过滤条件与where等价,对应逻辑计划树中的selection逻辑计划节点。
当having条件为实际的表列时,能够将对应的Selection算子节点进行下推。
select t1.a from t1 where t1.b = 1 group by t1.a having t1.a = 3;
select * from paren_table t1 left join chi_table t2 on t1.id > 1 where t2.cinfo = "poi" group by cid having cid > 1; //join场景同样可以下推
若having条件中非实际的表列则不能下推,如以下sql不能下推:
select a, count(b) as c from t1 group by a having c = 10;
5.group by(sum(a))怎么实现的
要想清楚这个语句的执行顺序,虽然看起来sum(a)是和groupby在一起执行的,但实际上是两个不同的阶段。
虽然group by中有一个聚合函数,但是这个聚合函数可以当做只是某一列的名字,可以把它当做单纯的一列值来处理,和group by (suma )是一样的。
这一列值(sum(a)),一定是在之前处理过生成好的列。比如是cn发到dn的sql,select sum(a) from t1;,这个时候cn的filed中就会有sum(a)这个列。
6.子查询都能转成join么?
不一定,需要按照数据量来判断,有的子查询是会被消除的,有的子查询数据量比较少,比如标量子查询,使用条件判断比join更快。
对于from中的子查询没有办法做消除,对于on表达式,where表达式中的子查询,会根据情况转化成semi join,left join,join的情况,新生成的on条件会根据连接关系来定。
| 操作符 | |
| =,>、>=,<,<= (子查询) | |
| =,>、>=,<,<= + ANY/ALL关键字 (子查询) |
7. select * from a left join b on a.id=b.id where a.id>3,谓词能不能下推?那么select * from a left join b on a.id=b.id and a.id>3,谓词能不能下推?
在where条件中的过滤条件是可以下推的,因为虽然是left join,join完之后的数据还是会被过滤掉。
在on条件中的过滤条件是不可下推的,因为这个是join的条件,left join在不满足on条件的时候需要补null值,所以a表是需要全量数据的。
8.一个文件100G,每行数据不超过1M,内存有1G,写一下实现去重操作的伪代码。
(我之前做的题目都是非常直接的数学题目,这种直接应用到实际情况的,一时间脑袋没有转过弯来。)
- 创建一些小文件,确保每个文件中的数据能够完全被内存装载
- 流式读取这个100G文件,每回读取一行数据
- 对该行数据进行一个hash,然后根据hash值,将这行数据放入对应的小文件
- 由于hash值不同,所以可以确定每个小文件中存储的数据肯定和其他文件不同
- 依次打开这些小文件,读取每个小文件的内容
- 在内存中构建一个set,过滤掉这个小文件中的重复数据,并写入新文件
边栏推荐
猜你喜欢
力扣题解8/10
Open Office XML 格式中的 Style 设计原理
![Array, string, date notes [Blue Bridge Cup]](/img/71/242804a93332fc545662b983f3aa2a.png)
Array, string, date notes [Blue Bridge Cup]
深度神经网络与人脑神经网络哪些区域有一定联系?
训练一个神经网络要多久,神经网络训练时间过长
SAP Product Enhancement Technology Review
Data middle platform program analysis and development direction
STM32入门开发 LWIP网络协议栈移植(网卡采用DM9000)
网络流行简笔画图片大全,关于网络的简笔画图片
Primavera Unifier 高级公式使用分享
随机推荐
MySQL数据库基础01
使用stream实现两个list集合的合并(对象属性的合并)
logstash/filebeat只接收最近一段时间的数据
二维数组名的用途
Simple strokes on the Internet
27岁了,目前从事软件测试,听些老一辈的人说测试前途是IT里最差的,是这样吗?
ES6: Expansion of Numerical Values
Network model (U - net, U - net++, U - net++ +)
HDRP shader to get shadows (Custom Pass)
Deploying Robot Vision Models Using Raspberry Pi and OAK Camera
错误代码: 1118 - Row size too large (> 8126). Changing some columns to TEXT or BLOB may help. In current
如何建立编程思想和提高编程思想
人是怎么废掉的?人是怎么变强的?
Primavera P6 Professional 21.12 登录异常案例分享
Primavera Unifier 自定义报表制作及打印分享
Validate the execution flow of the interceptor
SQL语句
pycharm cancel msyql expression highlighting
神经网络参数如何确定的,神经网络参数个数计算
The crawler is encapsulated into an api