当前位置:网站首页>Sub database and sub table & shardingsphere
Sub database and sub table & shardingsphere
2022-04-23 16:50:00 【Kramer_ one hundred and forty-nine】
Basic concepts
Vertical sub database and sub table are considered in database design .
As the amount of data increases , Do not directly consider the sub database and sub table . Use cache first 、 Read / write separation 、 Index and other methods , If none of these methods can solve the problem , Then use the horizontal sub database and horizontal sub table .
Problems caused by sub database and sub table :
1、 Cross node join query problem
2、 Multiple data source management issues
ShardingSphere Can solve
table
Vertical sub table
Example :
When the user is browsing the product list , Only when you are interested in an item will you see the detailed description of the item . therefore , The access frequency of the product description field in the product information is low , And the storage space of this field is large , Access to individual data IO Longer time ; Product name in the product information 、 Commodity images 、 Data access frequency of other fields such as commodity price is high .
Because of the difference between the two kinds of data , So he considered splitting the product information table as follows :

Horizontal sub table
The horizontal sub table is in the same database , Split the data of the same table into multiple tables according to certain rules .

sub-treasury
Vertical sub database
Vertical sub base refers to the classification of tables according to business , Distributed to different databases , Each library can be placed on a different server , Its core idea is dedicated to special storage
The improvement it brings is :
Solve business level coupling , Business is clear
It can manage the data of different services in different levels 、 maintain 、 monitor 、 Extension etc.
High concurrency scenarios , The vertical sub database has been improved to a certain extent IO、 Number of database connections 、 Reduce the bottleneck of single machine hardware resources
The vertical sub database classifies tables by business , And then distributed in different databases , And you can deploy these databases on different servers , So as to achieve the effect of sharing pressure among multiple servers , But it still hasn't solved the problem of too much data in single table .
The vertical table division in the library only solves the problem of too much data in a single table , But the tables are not distributed across different servers , So each table still competes for the same physical machine CPU、 Memory 、 The Internet IO、 disk .
Example :

Horizontal sub database
When it is impossible to carry out vertical database distribution at the business level , You can try to use horizontal sub Library .
Horizontal sub database uses the same database table structure to store the same type of data
Example :
After the vertical sub database , The database performance problem has been solved to a certain extent , But as the business grows ,PRODUCT_DB( Commodity bank ) The data stored in a single database has exceeded the estimate . rough estimate , There are 8w The store , The average store 150 Products of different specifications , Add in the growth , The quantity of the goods must go to 1500w+ Up to estimate , also PRODUCT_DB( Commodity bank ) It belongs to a very frequent resource , A single server can no longer support . How to optimize at this time ?
Here can be according to the store ID For odd and shops ID Even number of commodity information is placed in two databases
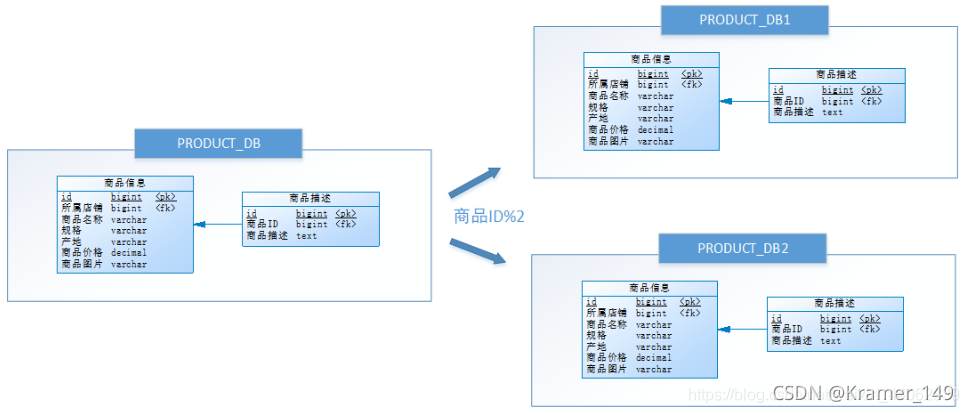
Java Realization - ShadingSphere
ShadingSphere Official website
Concept
ShadingSphere Is a set of open source distributed database middleware solutions . Focus on Sharding—JDBC、Sharding—Proxy.
Positioning is a relational database middleware , Rational use of relational database operation in distributed environment .
Sharding—JDBC
It's lightweight Java frame , stay Java Of JDBC Additional services provided by layer . It uses the client direct connection database , With jar Service in package form , No additional deployment and dependencies , Can be understood as “ Enhanced Edition JDBC drive ”, Fully compatible with JDBC And all kinds of ORM frame ( for example JPA、MyBatis). It also supports any third-party connection pool ( for example druid、DBCP etc. )
effect
( Its function “ Not at all ” Go to the sub warehouse and sub table )
After the database engineer completes the sub database and sub table ,Sharding—JDBC To operate the content that has been divided ( For example, putting data into multiple libraries , Read data, etc ).Sharding—JDBC The purpose is Simplify database related operations after database and table separation .
Sharding—JDBC The main function :
1、 Data fragmentation
2、 Read / write separation
Basic concepts
Logic table
A general term for horizontally split tables . For example, the order table is split into t_order_0、t_order_1、t_order_2、t_order_3 etc. . Their logical table is called t_order.
The table name written in the code is the logical table .
True table
In the above example t_order_0、t_order_1、t_order_2、t_order_3 etc. .
Data nodes
The smallest physical unit of data fragmentation , It consists of database and table . for example ds_0.t_order_0
Specifies which table in which library the logical table is distributed
Binding table
It refers to the main table and sub table with the same fragmentation rules . for example :t_order and t_order_item surface , All according to order_id Fragmentation , The partition keys between bound tables are exactly the same , Then the two tables are bound . Cartesian product association will not appear in multi table associated query between bound tables . For example, both tables are divided into 0 and 1, So when the joint investigation is conducted, only 0 and 0 Joint investigation ,1 and 1 Joint investigation .( If not bound , Will do a Cartesian product , perform 4 Queries )
Broadcast table
It refers to the table that exists in all fragmentation data sources , The structure of each table is completely consistent with the data in the database . It is suitable for scenarios where the amount of data is not large and needs to be associated with massive data tables .
Patch key
Database fields for sharding . for example Take the mantissa of the order primary key in the order table and split it into modules , Then the order primary key is the partition key .
Sharding algorithm
The data is divided into pieces by the fragmentation algorithm , perform =、BETWEEN、IN Fragmentation . The slicing algorithm needs to be implemented by developers .
Fragmentation strategy
Including the partition key and the partition algorithm , Because of the independence of the algorithm , Separate it from . What is really available for slicing is the partitioning key + Sharding algorithm , That is, fragmentation strategy . The built-in slicing strategy is roughly divided into mantissa and modulus 、 Hash 、 Range 、 label 、 Events, etc. . The partition strategy configured by the user side is more flexible . Common use of row expression configuration fragmentation strategy , It uses Groovy expression .
standard: Standard fragmentation strategy , Provide corresponding SQL Statement =,IN,BETWEEN AND Slice operation of . Only single partition key is supported .
complex: Comply with the fragmentation strategy , Provide corresponding SQL Statement =,IN,BETWEEN AND Slice operation of . Support multi partition key .
inline: Line expression fragmentation strategy . Use Groovy expression , Provide SQL Statement = and IN Slice operation of . Only single partition key is supported .
hint: adopt Hint Instead of SQL The way of analysis, the strategy of fragmentation .
none: No fragmentation strategy .
Practical example ( Horizontal sub table )
1、 Environmental Science :SpringBoot+MyBatisPlus+Sharding-JDBC+Druid Connection pool
springboot 2.2.1.RELEASE
2、 rely on
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
3、 Build table ( Horizontal sub table )
CREATE TABLE course_1 (
cid BIGINT ( 20 ) PRIMARY KEY,
cname VARCHAR ( 50 ) NOT NULL,
user_id BIGINT ( 20 ) NOT NULL,
cstatus VARCHAR ( 10 ) NOT NULL
);
CREATE TABLE course_2 (
cid BIGINT ( 20 ) PRIMARY KEY,
cname VARCHAR ( 50 ) NOT NULL,
user_id BIGINT ( 20 ) NOT NULL,
cstatus VARCHAR ( 10 ) NOT NULL
);
4、 Create entity class 、mapper Interface 、 Add... To the startup class mapperscan annotation
5、 To configure Sharding-JDBC Fragmentation strategy
(1)、 In the project application.properties To configure
Find configuration : Official website —— Learn more about —— left User's Manual ——ShardingJDBC—— Configuration manual ——SpringBoot To configure
# shardingjdbc Fragmentation strategy
# Configure data sources , Give the data source a name , Multiple data source names are separated by commas
spring.shardingsphere.datasource.names=m1
# Configure data source details , Contains connection pools 、 drive 、 Address 、 user name 、 password
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/sharding?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=12345678
# Appoint course Distribution of logical tables , Which database is the configuration table in , What are the table names
# here course Indicates the logical table name ( and mapper Inside sql The table name in the statement corresponds to , It can be customized to abc And so on. , then mapper Inside sql The sentence is also changed )
# $->{1..2} Represents the distribution of the table ( Which database is the table in , What is the name ), This is the data node
# there $->{1..2} Line expression used , It has its own grammar rules
spring.shardingsphere.sharding.tables.course.actual-data-nodes =m1.course_$->{1..2}
# Appoint course The primary key generation strategy in the logical table
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# Appoint course Fragmentation rules of logical table
# Specify the fragmentation policy Appointment cid Add even values to course_1 surface , If cid Is an odd number added to course_2 surface
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# open sql Output log
spring.shardingsphere.props.sql.show=true
6、 Test code
@SpringBootTest
class ShardingJdbcDemoApplicationTests {
@Autowired
private CourseMapper courseMapper;
@Test
public void addCourse() {
Course course=new Course();
course.setCname("java");
course.setUserId(100L);
course.setCstatus("Normal");
courseMapper.insert(course);
}
}
** notes :** There will be problems :
Description:
The bean 'dataSource', defined in class path resource [org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class], could not be registered. A bean with that name has already been defined in class path resource [com/alibaba/druid/spring/boot/autoconfigure/DruidDataSourceAutoConfigure.class] and overriding is disabled.
Action:
Consider renaming one of the beans or enabling overriding by setting spring.main.allow-bean-definition-overriding=true
Simply put, an entity class cannot correspond to two tables ;
The solution is :spring.main.allow-bean-definition-overriding=true Put this sentence in the configuration file application.properties
Execute the process
1、SQL analysis
2、SQL route , The process of mapping data operations on logical tables to operations on data nodes
3、SQL rewrite , Logic table course Change to real table course_1 or course_2
4、SQL perform , Perform real sql sentence
5、 The results merge , If logic sql There are many true sentences when executing sql, Then summarize the results
Practical example ( Horizontal sub database )
0、 demand
Two databases ,edu_db_1 and edu_db_2, There are two tables in the library course_1 and course_2. Rules of engagement :userid Add... For even numbers edu_db_1 in ,userid Add... To the base edu_db_2 in .cid Add to for even numbers course_1 in ,cid Add an odd number to course_2 in .
1、 Create databases and tables
sql The script is divided equally with the water table
2、 Configure database fragmentation rules in the configuration file
The sub database strategy is similar to the sub table strategy
# Sub library strategy , How to map a logical table to multiple data sources
spring.shardingsphere.sharding.tables.< Logical table name >.database-strategy.< Fragmentation strategy >.< Partition policy attribute name >=# Partition policy attribute value
# Tabulation strategy , How to map a logical table to multiple actual tables
spring.shardingsphere.sharding.tables.< Logical table name >.table-strategy.< Fragmentation strategy >.< Partition policy attribute name >=# Partition policy attribute value
Example :
# shardingjdbc Fragmentation strategy
# Configure data sources , Give the data source a name , Multiple data source names are separated by commas
spring.shardingsphere.datasource.names=m1,m2
# Configure data source details , Contains connection pools 、 drive 、 Address 、 user name 、 password
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=12345678
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=12345678
# Data nodes : Specify the database distribution , The sub database of tables in the database
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
# Appoint course The primary key generation strategy in the table
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# Specify the fragmentation policy of the table Appointment cid Add even values to course_1 surface , If cid Is an odd number added to course_2 surface
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# Specify the partition strategy of the database Appointment user_id Add to for even numbers m1,user_id Add an odd number to m2
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# The following is a sub database method for all logic tables , The above is to adopt specific strategies for specific tables
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# open sql Output log
spring.shardingsphere.props.sql.show=true
# An entity class corresponds to two tables
spring.main.allow-bean-definition-overriding=true
3、 Test code
The same water table
Practical example ( Project sub library has been completed )
server.port=8004
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
# shardingjdbc Fragmentation strategy
# Configure data sources , Give the data source a name , Multiple data source names are separated by commas
spring.shardingsphere.datasource.names=appidclia1ed623aa87a900b,appidclia1e788aeac38100d
# Configure data source details , Contains connection pools 、 drive 、 Address 、 user name 、 password
spring.shardingsphere.datasource.appidclia1ed623aa87a900b.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.appidclia1ed623aa87a900b.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.appidclia1ed623aa87a900b.url=jdbc:mysql://localhost:3306/appidcli_a1ed623aa87a900b?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.appidclia1ed623aa87a900b.username=root
spring.shardingsphere.datasource.appidclia1ed623aa87a900b.password=12345678
spring.shardingsphere.datasource.appidclia1e788aeac38100d.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.appidclia1e788aeac38100d.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.appidclia1e788aeac38100d.url=jdbc:mysql://localhost:3306/appidcli_a1e788aeac38100d?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.appidclia1e788aeac38100d.username=root
spring.shardingsphere.datasource.appidclia1e788aeac38100d.password=12345678
# Data nodes
spring.shardingsphere.sharding.tables.buffer_course.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.buffer_course
spring.shardingsphere.sharding.tables.buffer_course_member.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.buffer_course_member
spring.shardingsphere.sharding.tables.buffer_class.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.buffer_class
spring.shardingsphere.sharding.tables.buffer_task.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.buffer_task
spring.shardingsphere.sharding.tables.buffer_task_collaborator.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.buffer_task_collaborator
spring.shardingsphere.sharding.tables.announcement.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.announcement
spring.shardingsphere.sharding.tables.calendar.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.calendar
spring.shardingsphere.sharding.tables.chat.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.chat
spring.shardingsphere.sharding.tables.chat_member.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.chat_member
spring.shardingsphere.sharding.tables.company.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.company
spring.shardingsphere.sharding.tables.course_config.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.course_config
spring.shardingsphere.sharding.tables.course_config_material.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.course_config_material
spring.shardingsphere.sharding.tables.event_info.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.event_info
spring.shardingsphere.sharding.tables.event_config.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.event_config
spring.shardingsphere.sharding.tables.global_sync_config.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.global_sync_config
spring.shardingsphere.sharding.tables.lark_operation_sync_log.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.lark_operation_sync_log
spring.shardingsphere.sharding.tables.task.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.task
spring.shardingsphere.sharding.tables.task_collaborator.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.task_collaborator
spring.shardingsphere.sharding.tables.task_config.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.task_config
spring.shardingsphere.sharding.tables.upstream_data_sync_log.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.upstream_data_sync_log
spring.shardingsphere.sharding.tables.upstream_operation_sync_log.actual-data-nodes=appid$->{
['clia1e788aeac38100d','clia1e788aeac38100d']}.upstream_operation_sync_log
# The following is a sub database method for all databases , The above is to adopt specific strategies for specific tables
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=appId
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=appid$->{
appId}
# open sql Output log
spring.shardingsphere.props.sql.show=true
# An entity class corresponds to two tables
spring.main.allow-bean-definition-overriding=true
Practical example ( Vertical sub database )
0、 There are two databases :user_db、course_db. When querying users, go to user_db Medium t_user surface
1、 Create database t_user There are three fields :user_id、username、ustatus
2、 Create entity class User, Interface UserMapper
3、 Configure the vertical sub database policy
stay application.properties To configure
( This includes the previous data source , If not, you can remove )
# shardingjdbc Fragmentation strategy
# Configure data sources , Give the data source a name , Multiple data source names are separated by commas
spring.shardingsphere.datasource.names=m1,m2,m0
# Configure data source details , Contains connection pools 、 drive 、 Address 、 user name 、 password
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=12345678
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=12345678
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=12345678
# To configure user_db In the database t_user Make a special database and a special table
# t_user It's a rule , The following strategies will be used , Equivalent to binding
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=m$->{0}.t_user
# Appoint course The primary key generation strategy in the table
spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
# Specify the fragmentation policy of the table , Because there is no horizontal table , Then put them all in t_user In the table
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user
# open sql Output log
spring.shardingsphere.props.sql.show=true
# An entity class corresponds to two tables
spring.main.allow-bean-definition-overriding=true
4、 The test program
@Test
public void addUser() {
User user=new User();
user.setUsername("zhangsan");
user.setUstatus("Normal");
userMapper.insert(user);
}
Practical example ( Working with common tables )
Public table : A table that stores stable data in a project , The data in the table changes less , And this table is often associated when querying .
commonly , Create this common table in each database ( same ), The data is synchronized when
1、 Create common tables in multiple databases
edu_db_1、edu_db_2、user_db
create table t_udict(
dictid bigint(20) primary key,
ustatus varchar(100) not null,
uvalue varchar(100) not null
)
2、 Configure public tables in the project configuration file
stay application.properties To configure ( Add the following contents on the original basis )
# Configure common tables
spring.shardingsphere.sharding.broadcast-tables=t_udict
# Public table primary key policy
spring.shardingsphere.sharding.tables.t_udict.key-generator.column=dictid
spring.shardingsphere.sharding.tables.t_udict.key-generator.type=SNOWFLAKE
3、 Create entities and interfaces mapper
4、 Test code
When adding or modifying , The of these libraries will change .
@Test
public void addDict(){
Udict udict=new Udict();
udict.setUstatus("a");
udict.setUvalue("start");
udictMapper.insert(udict);
}
@Test
public void deleteDict(){
QueryWrapper<Udict> wrapper=new QueryWrapper<>();
wrapper.eq("dictid",667028606819500033L);
udictMapper.delete(wrapper);
}
ShardingJDBC Read and write separation
To ensure the stability of database products , Many databases have dual computer hot standby function . The first server is a production server that provides external addition, deletion and modification services ; The second server is mainly used for reading . principle : Let the main database (master) Transactional increase 、 Delete 、 Change operation , And processing from the database select Query operation .
Take one master and one slave as an example : The primary server is turned on binlog journal , Record addition, deletion and modification . The slave server monitors the master server in real time binlog Log changes .
ShardingJDBC adopt sql Sentence semantic analysis , Read and write separation .
Practical example
1、 Create two database services , Set up master-slave relationship , And start the .
Windows System Reference video
2、ShardingJDBC operation
ShardingJDBC The function is to access different databases according to different semantics
application.properties To configure
spring.shardingsphere.datasource.names=m0,s0
# The main data source
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=root
# From the database data source
spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.s0.url=jdbc:mysql://localhost:3307/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.s0.username=root
spring.shardingsphere.datasource.s0.password=12345678
# Master and slave logical data source definition ( Specify who is the master and who is the slave ),ds0 The corresponding is user_db database
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=s0
# t_user Tabulation strategy , Fixed allocation to ds0 Of t_user True table , use ds0 Represents the master server and the slave server user_db database
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds0.t_user
# Appoint course The primary key generation strategy in the table
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# Specify the fragmentation policy Appointment cid Add even values to course_1 surface , If cid Is an odd number added to course_2 surface
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# open sql Output log
spring.shardingsphere.props.sql.show=true
# An entity class corresponds to two tables
spring.main.allow-bean-definition-overriding=true
3、 The test program
Omit , The above code is OK .
Sharding—Proxy
Positioning as a transparent database agent , Provide the server version that encapsulates the binary protocol of the database , Used to support heterogeneous languages . At present MySQL and PostgreSQL( compatible openGauss Based on PostgreSQL The database of ) edition , It can use any compatible MySQL/PostgreSQL Protocol access client ( Such as :MySQL Command Client, MySQL Workbench, Navicat etc. ) Operational data , Yes DBA More friendly .
Equivalent to a programmer writing code using only operations ShardingProxy, then ShardingProxy Then operate our database . That is, an agent .
ShardingProxy Independent application , Use installation services , Separate database and table reading and writing configuration , It can only be used after final startup .
install
Official website
After downloading , Unzip the compressed file , start-up bin Directory startup file (windiws use .bat,linux use .sh) That's all right. .
( If lib Under the jar The package suffix is incorrect , It needs to be modified manually )
To configure
Configuration file in conf Under the table of contents
1、server.yaml
Open two files
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
- !TRANSACTION
defaultType: XA
providerType: Atomikos
props:
max-connections-size-per-query: 1
kernel-executor-size: 16 # Infinite by default.
proxy-frontend-flush-threshold: 128 # The default value is 128.
proxy-opentracing-enabled: false
proxy-hint-enabled: false
sql-show: false
check-table-metadata-enabled: false
show-process-list-enabled: false
2、 config-sharding.yaml
Set sub database and sub table rules
notes : It needs to be copied mysql Driven jar Package to lib in
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${
0..1}.t_order_${
0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
t_order_item:
actualDataNodes: ds_${
0..1}.t_order_item_${
0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
keyGenerateStrategy:
column: order_item_id
keyGeneratorName: snowflake
bindingTables:
- t_order,t_order_item
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${
user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${
order_id % 2}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${
order_id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
3、 Start the service
The default port is 3307
Designated port :cmd Start the service , Use command start.bat 3308 You can specify the window to start .
4、 adopt Sharding-Proxy Start the port to connect
cmd Window connection , Connection mode and connection mysql equally .
3307 Is the port to start the service
mysql -P3307 -uroot -p
5、 Local database verification
Go back to the local real database , Check for data .
Sub database and sub table
Read / write separation
版权声明
本文为[Kramer_ one hundred and forty-nine]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231359461098.html
边栏推荐
- SQL database
- How vscode compares the similarities and differences between two files
- LVM与磁盘配额
- 如何用Redis实现分布式锁?
- Use itextpdf to intercept the page to page of PDF document and divide it into pieces
- Detailed explanation of Niuke - Gloves
- Server log analysis tool (identify, extract, merge, and count exception information)
- Mock test using postman
- On the security of key passing and digital signature
- MySql主从复制
猜你喜欢
Use case execution of robot framework
Use itextpdf to intercept the page to page of PDF document and divide it into pieces

安装及管理程序
DDT + Excel for interface test
【Pygame小游戏】10年前风靡全球的手游《愤怒的小鸟》,是如何霸榜的?经典回归......
1959年高考数学真题
Mock test
Creation of RAID disk array and RAID5
Bytevcharts visual chart library, I have everything you want
RAID磁盘阵列与RAID5的创建
随机推荐
Copy constructor shallow copy and deep copy
On the security of key passing and digital signature
1959年高考数学真题
英语 | Day15、16 x 句句真研每日一句(从句断开、修饰)
Detailed explanation of the penetration of network security in the shooting range
Ali developed three sides, and the interviewer's set of combined punches made me confused on the spot
Esxi encapsulated network card driver
File upload and download of robot framework
OMNeT学习之新建工程
File system read and write performance test practice
100 deep learning cases | day 41 - convolutional neural network (CNN): urbansound 8K audio classification (speech recognition)
∑GL-透视投影矩阵的推导
5-minute NLP: text to text transfer transformer (T5) unified text to text task model
04 Lua 运算符
安装及管理程序
[pyGame games] how did angry birds, a mobile game that became popular all over the world 10 years ago, dominate the list? Classic return
聊一聊浏览器缓存控制
loggie 源码分析 source file 模块主干分析
Dancenn: overview of byte self-developed 100 billion scale file metadata storage system
磁盘管理与文件系统