当前位置:网站首页>2. Finishing huazi Mianjing -- 2
2. Finishing huazi Mianjing -- 2
2022-04-23 20:53:00 【CV engineer driven by interest】
The encryption algorithm you know ?
MD5 Algorithm : Use hash function , It is not an encryption algorithm, but a hash algorithm , Its typical application is to generate information summary for a piece of information , To prevent being tampered with , No matter how long the input ,md5 Will output a 128bits A string of
SHA1 Algorithm : And MD5 The same popular hash algorithm , Security is better than MD5, But slow and MD5, be based on MD5,SHA1 The characteristics of information summarization and irreversibility , It can be used to check file integrity and digital signature
AES Algorithm : Symmetric block encryption algorithm , The encryption and decryption process is reversible
RSA Algorithm : Asymmetric encryption algorithm ,RSA It is the first one that can be used for encryption and digital signature at the same time Algorithm , All password attacks known so far , It is based on a very simple number theory fact : It's easy to multiply two large prime numbers , But it is very difficult to factorize the product , Therefore, its product can be disclosed as an encryption key
digital signature : A way to provide identifiable digital information to verify your identity
encryption : Process plaintext or data according to some algorithm , Make it unreadable
Decrypt : The reverse of encryption , The process of converting encoded information into original data
Symmetric encryption / Asymmetric encryption : The encryption and decryption keys are the same / Different , The key of symmetric algorithm is difficult to manage , Not suitable for the Internet in general , For internal systems , encryption / Fast decryption , Suitable for processing large amounts of data , Asymmetric algorithm keys are easy to manage , High safety , But encryption is slow , Suitable for small amount of data encryption or data signature
The idea of quick sequencing ?
- First, select a number from the sequence as the reference number
- During partitioning , Put a number larger than this number on its right , All numbers less than or equal to it are placed on its left
- Repeat the previous step , Know that there is only one number left in the left and right range
How to calculate the total number of permutations with repeated characters ?
Count the number of all characters , And the number of repeated characters , The result is the full arrangement of all numbers / Full arrangement of repeating characters
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String s=scanner.nextLine();
HashMap<Character, Integer> map = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
map.put(s.charAt(i),map.getOrDefault(s.charAt(i),0)+1);
}
int tol=getPermute(s.length());
for (Map.Entry<Character, Integer> entry : map.entrySet()) {
if(entry.getValue()!=1){
tol/=getPermute(entry.getValue());
}
}
System.out.println(tol);
}
public static int getPermute(int n){
int res=1;
while (n!=1){
res*=n;
n--;
}
return res;
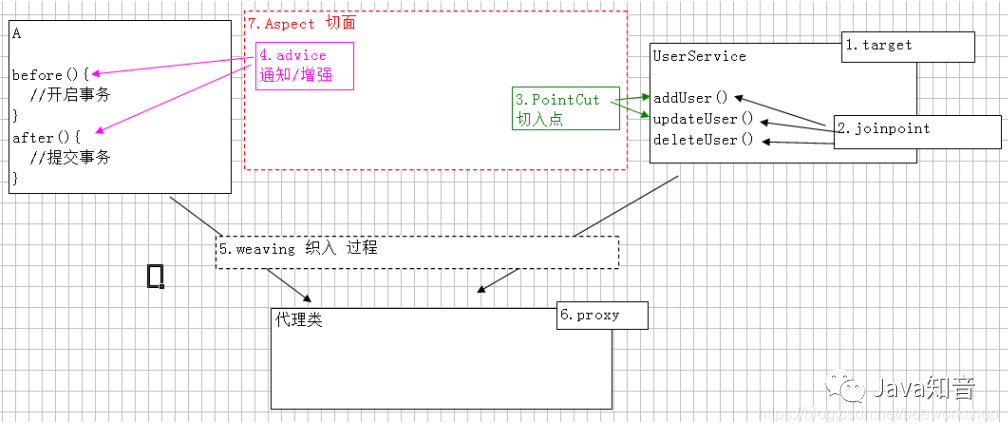
}AOP The concept of ?
aop Programming for facets , Can process logs , Business , Abnormal etc.
- target: Target class
- notice : Functions that need to be enhanced or added , Defines the of the section " what " And " when "
- Connection point : During application execution , When you can insert the section
- Tangent point : Timing running , Select the connection point of the insertion section , Defines which points have been enhanced , Defines where
- section : Modularize crosscutting concerns into special classes , These classes are called facets
- introduce : Allows you to add new methods and properties to an existing class
- Weaving : The process of applying facets to the target object and creating a new proxy object
Dao How are the methods in the interface related to xml The statements in ?
MyBatis Initializing SqlSessionFactoryBean When , Find the path area of the basic package that needs to be scanned for configuration, and analyze all the paths in it XML file
MyBatis Will put each sql The label is sealed as sqlSource object , And then according to sql Different sentences , It is also divided into dynamic sql And static sql, Where static sql Include a paragraph String Type of sql sentence , And dynamic sql Is made up of sqlNode form (IfNode,WhereNode etc. )
XML Every... In the document sql The label corresponds to one mapperStatement object , It has two very important properties :id For fully qualified class names + Method name ,sqlSource;
Created mapperStatement Object will be cached in Configuration in , such Configuration It includes all sql Information , Later MyBatis Method time , Will pass the fully qualified class name + Method name found MappedStatement object , And then analyze the sql Content is enough
Which is more efficient, the primary key index or the unique index ?
The primary keys of all indexes are ordinary ones , Then query according to the primary key , So you have to retrieve it twice , Therefore, the primary key index is more efficient than the unique index
Mysql Why don't you use functions on fields instead of indexes ? What else is not going to happen
Perform function operations on indexed fields , The Mainz optimizer decided to give up the tree search function, which may destroy the order of index values , It should be noted that , The optimizer is not abandoning the index
- Implicit type conversion does not take the index : For example tradeid It was originally varchar, The results are as follows sql
mysql> select * from tradelog where tradeid=110717;
- The operation of queries on composite indexes that do not comply with the leftmost prefix principle
Why? HashMap Thread unsafe ?
The main reason is resize Scale operation
stay put The multithreaded data is inconsistent , Like two threads a and b,a Want to insert a record into map in , First, calculate the index coordinates of the bucket , Then get the chain header node , here a I ran out of time ,b Enforced , and a Do the same , It's just b Successfully inserted record , here a Yes b I know nothing about your behavior , hypothesis a Record Insert Index and b Record insertion index is consistent , that a The insertion of will cover b The record of
stay get Cause a dead cycle when , from 1.7 The previous head insertion method caused ,resize Method and then migrate to the new bucket process , Head insertion method is used , Suppose there is such a linked list 1->2, During the expansion , Using the header will make its data in the new bucket become 2->1, If the thread a It hasn't been revised yet 1 Successor node , Threads b Insert... Is executed , It leads to a dead cycle
MySQL Of delete and truncate The difference between ?
delete Delete records one by one , Data can be retrieved with event and rollback , And auto increment will not reset
truncate Delete the entire table directly , Then create a new as like as two peas. ,auto_increment Will be reset , And the data cannot be retrieved
Mysql How to establish users and change passwords ?
Create user :Create User 'aaa' identified by '123456'; Create a new user , be known as aaa The password for 123456
Change password :Set password for 'aaa' =Password("123");
Forget the root Password of the account :
- mysqld --skip-grant-tables skip mysql User authentication for
- adopt update user set password=password('root') where user='root' and host='localhost' Change password
版权声明
本文为[CV engineer driven by interest]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/113/202204232049470392.html
边栏推荐
- Problem brushing plan -- dynamic programming (III)
- [SQL] string series 2: split a string into multiple lines according to specific characters
- UKFslam
- 启牛学堂有用吗,推荐的证券账户是否安全
- 常用60类图表使用场景、制作工具推荐
- unity 功能扩展
- Leetcode-279-complete square number
- South Korea may ban apple and Google from offering commission to developers, the first in the world
- mmap、munmap
- Pytorch preserves different forms of pre training models
猜你喜欢





随机推荐
Reference of custom message in ROS function pack failed
Fastdfs mind map
1.整理华子面经--1
使用mbean 自动执行heap dump
2.整理华子面经--2
Unity solves Z-fighting
Thinking after learning to type
3-5 obtaining cookies through XSS and the use of XSS background management system
Crisis is opportunity. Why will the efficiency of telecommuting improve?
MySQL基础之写表(创建表)
C# 知识
Leetcode-279-complete square number
airbase 初步分析
Selenium 显示等待WebDriverWait
Unity animation creates sequence frame code and generates animationclip
Ubutnu20 installer centernet
Opencv reports an error. Expected PTR < CV:: UMAT > for argument '% s'‘
Some grounded words
Keywords static, extern + global and local variables
又一款数据分析神器:Polars 真的很强大