当前位置:网站首页>Introduction to tensorrt
Introduction to tensorrt
2022-04-23 21:02:00 【Top of the program】
1. Basic TensorRT Workflow
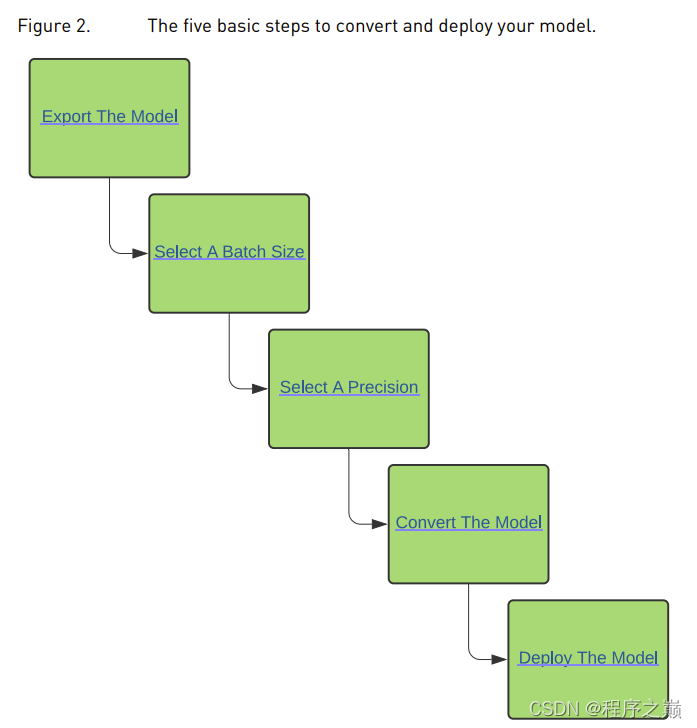
2. Transformation and deployment options
2.1 transformation
- Use TF-TRT, In order to convert TensorFlow Model ,TensorFlow Integrate (TF-TRT) Provides model transformation and advanced runtime
API, And has a fallback to TensorRT The of a specific operator is not supported TensorFlow Realization .
A more efficient option for automatic model transformation and deployment is transformation - from .onnx Automatic file conversion ONNX. Use ONNX. ONNX Is a framework independent option , Can be used to TensorFlow ,PyTorch The model in such format is transformed into ONNX Format .TensorRT Support use ONNX Automatic file conversion TensorRT API or trtexec - The latter is what we will use in this guide .ONNX Conversion is All or nothing , This means that all operations in your model must be performed by TensorRT Support ( Or you A custom plug-in must be provided for unsupported operations ).ONNX The final result of the conversion It's a single TensorRT engine , It allows you to use TF-TRT Less spending .
- Use TensorRT API( stay C++ or Python in ) Build the network manually
To maximize performance and customizability , You can also build TensorRT The engine is used manually TensorRT Network definition API. This mainly involves TensorRT The ecological system NVIDIA TensorRT DU-10313-001_v8.2.3 | 10 stay TensorRT In operation, the same network as the target model is built through operation , Use only TensorRT operation . establish TensorRT After network , You will only export the weights of the models taken from the frame and load them into the TensorRT In the network . For this method , About using TensorRT More information definition of network construction model API, You can find it here :
Creating A Network Definition From Scratch Using The C++ API
Creating A Network Definition From Scratch Using The Python API
2.2 Deploy
Use TensorRT The deployment model has three options :
‣ stay TensorFlow Deployment in China
‣ Use independent TensorRT Runtime API
‣ Use NVIDIA Triton Inference server
Your deployment choices will determine the steps required to transform the model .
Use TF-TRT when , The most common deployment option is simply to TensorFlow. TF-TRT The transformation produces a with TensorRT Operation of the
TensorFlow chart Insert it . This means you can run like any other TensorFlow Same operation TF-TRT Model USES Python
Model of .TensorRT Runtime API Allow the lowest overhead and the most fine-grained control , but TensorRT Operators that are not supported by themselves must be implemented as plug-ins ( A library
Pre written plug-ins are available here ). Use the most common path for runtime deployment API Is derived from the framework ONNX
To achieve , This is described in the following sections of this guide .Last ,NVIDIA Triton Inference Server Is an open source reasoning service software , Enable the team to start from any framework (TensorFlow、TensorRT、 PyTorch、ONNX Run time or custom framework ), From local storage or Google Cloud Anything based on GPU or CPU Infrastructure of ( cloud 、 Data center or edge ) On the platform or AWS S3. This is a flexible project , It has several unique functions For example, the first mock exam models execute heterogeneous models and multiple replicates of the same model. ( Multiple copies of the model can further reduce latency ) And load balancing and model analysis . This is a good choice if you need to pass HTTP Provide models - For example, in cloud reasoning solutions .
2.3 Choose the right workflow
The two most important factors in choosing how to transform and deploy the model are :
1. The frame you choose .
- Your preferred TensorRT Runtime target .
The following flowchart covers the different workflows covered in this guide . This flowchart will help you choose a path based on these two factors
The sample deployment uses ONNX
ONNX Conversion is usually automatic ONNX The most efficient way to model TensorRT engine . In this section , We will introduce the following five basic steps
In the deployment of pre training ONNX In the case of the model TensorRT transformation .
Reference article
https://github.com/NVIDIA/TensorRT/blob/main/quickstart/IntroNotebooks/4.%20Using%20PyTorch%20through%20ONNX.ipynb
https://github.com/ultralytics/yolov5/issues/251
版权声明
本文为[Top of the program]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/111/202204210545090116.html
边栏推荐
- 学会打字后的思考
- C knowledge
- C#,打印漂亮的贝尔三角形(Bell Triangle)的源程序
- [SDU chart team - core] enumeration of SVG attribute class design
- Factory mode
- pytorch 1.7. The model saved by X training cannot be loaded in version 1.4 or earlier
- 3-5 obtaining cookies through XSS and the use of XSS background management system
- IOT design and development
- PHP的Laravel与Composer部署项目时常见问题
- Assertionerror: invalid device ID and runtimeerror: CUDA error: invalid device ordinal
猜你喜欢
MySQL基础合集

Sharpness difference (SD) calculation method of image reconstruction and generation domain index
go interface

居家第二十三天的午饭
浅谈数据库设计之三大范式
Chrome 94 引入具有争议的 Idle Detection API,苹果和Mozilla反对

41. 缺失的第一个正数
How to make Jenkins job run automatically after startup

opencv应用——以图拼图
![[leetcode refers to offer 27. Image of binary tree (simple)]](/img/65/85e63a8b7916af058d78d72d775530.png)
[leetcode refers to offer 27. Image of binary tree (simple)]
随机推荐
Lunch on the 23rd day at home
常用60类图表使用场景、制作工具推荐
On IRP from the perspective of source code
Automatic heap dump using MBean
Presto on spark supports 3.1.3 records
IOT design and development
Tencent cloud has two sides in an hour, which is almost as terrible as one side..
The iswow64process function determines the number of program bits
ROS学习笔记-----ROS的使用教程
Realrange, reduce, repeat and einops in einops package layers. Rearrange and reduce in torch. Processing methods of high-dimensional data
Queue template code
go struct
使用mbean 自动执行heap dump
Minecraft 1.12.2 module development (43) custom shield
Assertionerror: invalid device ID and runtimeerror: CUDA error: invalid device ordinal
Detectron2 usage model
ros功能包内自定义消息引用失败
2.整理华子面经--2
DeNO 1.13.2 release
GSI-ECM工程建设管理数字化平台