当前位置:网站首页>How to analyze the neural network diagram, draw the neural network structure diagram
How to analyze the neural network diagram, draw the neural network structure diagram
2022-08-11 09:39:00 【Yangyang 2013 haha】

神经网络Hopfield模型
一、Hopfield模型概述1982年,美国加州工学院J.Hopfield发表一篇对人工神经网络研究颇有影响的论文.他提出了一种具有相互连接的反馈型人工神经网络模型——Hopfield人工神经网络.
Hopfield人工神经网络是一种反馈网络(RecurrentNetwork),又称自联想记忆网络.
其目的是为了设计一个网络,存储一组平衡点,使得当给网络一组初始值时,网络通过自行运行而最终收敛到所存储的某个平衡点上.
Hopfield网络是单层对称全反馈网络,根据其激活函数的选取不同,可分为离散型Hopfield网络(DiscreteHopfieldNeuralNetwork,简称DHNN)和连续型Hopfield网络(ContinueHopfieldNeuralNetwork,简称CHNN).
离散型Hopfield网络的激活函数为二值型阶跃函数,主要用于联想记忆、模式分类、模式识别.这个软件为离散型Hopfield网络的设计、应用.
二、Hopfieldmodel principle discreteHopfield网络的设计目的是使任意输入矢量经过网络循环最终收敛到网络所记忆的某个样本上.
Weights of orthogonalization design and starting point is the basic idea of this method in order to satisfy the following4个要求:1)保证系统在异步工作时的稳定性,即它的权值是对称的,满足wij=wji,i,j=1,2…,N;2)保证所有要求记忆的稳定平衡点都能收敛到自己;3)使伪稳定点的数目尽可能地少;4)使稳定点的吸引力尽可能地大.
正交化权值的计算公式推导如下:1)已知有P个需要存储的稳定平衡点x1,x2…,xP-1,xP,xp∈RN,计算N×(P-1)阶矩阵A∈RN×(P-1):A=(x1-xPx2-xP…xP-1-xP)T.
2)对A做奇异值分解A=USVT,U=(u1u2…uN),V=(υ1υ2…υP-1),中国矿产资源评价新技术与评价新模型Σ=diαg(λ1,λ2,…,λK),O为零矩阵.
K维空间为N维空间的子空间,它由K个独立的基组成:K=rαnk(A),设{u1u2…uK}为A的正交基,而{uK+1uK+2…uN}为N维空间的补充正交基.下面利用U矩阵来设计权值.
3)Structure of China mineral resources evaluation of new technology and the evaluation of the new model the total connection weight matrix of the:Wt=Wp-T·Wm,其中,T为大于-1的参数,缺省值为10.
Wp和Wm均满足对称条件,即(wp)ij=(wp)ji,(wm)ij=(wm)ji,因而Wt中分量也满足对称条件.这就保证了系统在异步时能够收敛并且不会出现极限环.
4)网络的偏差构造为bt=xP-Wt·xP.下面推导记忆样本能够收敛到自己的有效性.
(1)对于输入样本中的任意目标矢量xp,p=1,2,…,P,因为(xp-xP)是A中的一个矢量,它属于A的秩所定义的K个基空间的矢量,所以必存在系数α1,α2,…,αK,使xp-xP=α1u1+α2u2+…+αKuK,即xp=α1u1+α2u2+…+αKuK+xP,对于U中任意一个ui,Has the Chinese mineral resources evaluation of new technology and the evaluation of the new model by the orthogonal property known,上式中当i=j,;当i≠j,;对于输入模式xi,其网络输出为yi=sgn(Wtxi+bt)=sgn(Wpxi-T·Wmxi+xP-WpxP+T·WmxP)=sgn[Wp(xi-xP)-T·Wm(xi-xP)+xP]=sgn[(Wp-T·Wm)(xi-xP)+xP]=sgn[Wt(xi-xP)+xP]=sgn[(xi-xP)+xP]=xi.
(2)对于输入模式xP,其网络输出为yP=sgn(WtxP+bt)=sgn(WtxP+xP-WtxP)=sgn(xP)=xP.
(3)如果输入一个不是记忆样本的x,网络输出为y=sgn(Wtx+bt)=sgn[(Wp-T·Wm)(x-xP)+xP]=sgn[Wt(x-xP)+xP].
因为x不是已学习过的记忆样本,x-xP不是A中的矢量,则必然有Wt(x-xP)≠x-xP,并且再设计过程中可以通过调节Wt=Wp-T·Wm中的参数T的大小来控制(x-xP)与xP的符号,以保证输入矢量x与记忆样本之间存在足够的大小余额,从而使sgn(Wtx+bt)≠x,使x不能收敛到自身.
用输入模式给出一组目标平衡点,函数HopfieldDesign()可以设计出Hopfield网络的权值和偏差,保证网络对给定的目标矢量能收敛到稳定的平衡点.
设计好网络后,可以应用函数HopfieldSimu(),对输入矢量进行分类,这些输入矢量将趋近目标平衡点,最终找到他们的目标矢量,作为对输入矢量进行分类.
三、总体算法1.Hopfield网络权值W[N][N]、偏差b[N]Design of the overall algorithm design method of orthogonalization weights,设计Hopfield网络;根据给定的目标矢量设计产生权值W[N][N],偏差b[N];使Hopfield网络的稳定输出矢量与给定的目标矢量一致.
1)输入P个输入模式X=(x[1],x[2],…,x[P-1],x[P])输入参数,包括T、h;2)由X[N][P]构造A[N][P-1]=(x[1]-x[P],x[2]-x[P],…,x[P-1]-x[P]);3)对A[N][P-1]作奇异值分解A=USVT;4)求A[N][P-1]的秩rank;5)由U=(u[1],u[2],…,u[K])构造Wp[N][N];6)由U=(u[K+1],…,u[N])构造Wm[N][N];7)构造Wt[N][N]=Wp[N][N]-T*Wm[N][N];8)构造bt[N]=X[N][P]-Wt[N][N]*X[N][P];9)构造W[N][N](9~13),构造W1[N][N]=h*Wt[N][N];10)求W1[N][N]的特征值矩阵Val[N][N](对角线元素为特征值,其余为0),特征向量矩阵Vec[N][N];11)求Eval[N][N]=diag{exp[diag(Val)]}[N][N];12)求Vec[N][N]的逆Invec[N][N];13)构造W[N][N]=Vec[N][N]*Eval[N][N]*Invec[N][N];14)构造b[N],(14~15),C1=exp(h)-1,C2=-(exp(-T*h)-1)/T;15)Structure of China mineral resources evaluation of new technology and the evaluation of new modelUˊ——U的转置;16)输出W[N][N],b[N];17)结束.
2.Hopfield网络预测应用总体算法Hopfield网络由一层N个斜坡函数神经元组成.应用正交化权值设计方法,设计Hopfield网络.根据给定的目标矢量设计产生权值W[N][N],偏差b[N].
初始输出为X[N][P],计算X[N][P]=f(W[N][N]*X[N][P]+b[N]),进行T次迭代,返回最终输出X[N][P],可以看作初始输出的分类.
3.Ramp function of China mineral resources evaluation scope of new technology and the evaluation model output[-1,1].四、数据流图Hopfield网数据流图见附图3.
五、调用函数说明1.一般实矩阵奇异值分解(1)function with Haushold(Householder)变换及变形QR算法对一般实矩阵进行奇异值分解.
(2)method description setA为m×n的实矩阵,则存在一个m×m的列正交矩阵U和n×n的列正交矩阵V,Evaluation of mineral resources which China new technology and the evaluation model was set up.
其中Σ=diag(σ0,σ1,…σp)p⩽min(m,n)-1,且σ0≥σ1≥…≥σp>0,上式称为实矩阵A的奇异值分解式,σi(i=0,1,…,p)称为A的奇异值.
奇异值分解分两大步:第一步:用豪斯荷尔德变换将A约化为双对角线矩阵.
China mineral resources evaluation new technology and the evaluation model of China mineral resources evaluation of new technology and the evaluation of each of the new model transformationUj(j=0,1,…,k-1)将A中的第j列主对角线以下的元素变为0,And each transformation inVj(j=0,1,…,l-1)将A中的第j行主对角线紧邻的右次对角线元素右边的元素变为0.
]]j具有如下形式:China's mineral resources evaluation of new technology and the evaluation of the new model ofρ为一个比例因子,以避免计算过程中的溢出现象与误差的累积,Vj是一个列向量.
即Vj=(υ0,υ1,…,υn-1),Is China's mineral resources evaluation of new technology and the evaluation model of China mineral resources evaluation of new technology and the evaluation model to the second step:用变形的QR算法进行迭代,计算所有的奇异值.
即:用一系列的平面旋转变换对双对角线矩阵B逐步变换成对角矩阵.
在每一次的迭代中,With transformation of China mineral resources evaluation new technology and the evaluation model of transformationB中第j列主对角线下的一个非0元素变为0,同时在第j行的次对角线元素的右边出现一个非0元素;而变换Vj,j+1将第j-1行的次对角线元素右边的一个0元素变为0,同时在第j列的主对角线元素的下方出现一个非0元素.
由此可知,经过一次迭代(j=0,1,…,p-1)后,B′仍为双对角线矩阵.但随着迭代的进行.最后收敛为对角矩阵,其对角线上的元素为奇异值.
在每次迭代时,经过初始化变换V01后,将在第0列的主对角线下方出现一个非0元素.在变换V01中,选择位移植u的计算公式如下:China mineral resources finally also need to evaluate new technologies and new models of singular value according to the increasing order arrangement.
在上述变换过程中,若对于某个次对角线元素ej满足|ej|⩽ε(|sj+1|+|sj|)则可以认为ej为0.若对角线元素sj满足|sj|⩽ε(|ej-1|+|ej|)则可以认为sj为0(即为0奇异值).
其中ε为给定的精度要求.
(3)调用说明intbmuav(double*a,intm,intn,double*u,double*v,doubleeps,intka),本函数返回一个整型标志值,若返回的标志值小于0,则表示出现了迭代60次还未求得某个奇异值的情况.
此时,矩阵的分解式为UAVT;若返回的标志值大于0,则表示正常返回.形参说明:a——指向双精度实型数组的指针,体积为m×n.
存放m×n的实矩阵A;返回时,其对角线给出奇异值(以非递增次序排列),其余元素为0;m——整型变量,实矩阵A的行数;n——整型变量,实矩阵A的列数;u——指向双精度实型数组的指针,体积为m×m.
返回时存放左奇异向量U;υ——指向双精度实型数组的指针,体积为n×n.返回时存放右奇异向量VT;esp——双精度实型变量,给定的精度要求;ka——整型变量,其值为max(m,n)+1.
2.求实对称矩阵特征值和特征向量的雅可比过关法(1)function with jacobian(Jacobi)方法求实对称矩阵的全部特征值与相应的特征向量.(2)Method to illustrate the basic idea of Jacobi method is as follows.设n阶矩阵A为对称矩阵.
在n阶对称矩阵A的非对角线元素中选取一个绝对值最大的元素,设为apq.
利用平面旋转变换矩阵R0(p,q,θ)对A进行正交相似变换:A1=R0(p,q,θ)TA,其中R0(p,q,θ)的元素为rpp=cosθ,rqq=cosθ,rpq=sinθ,rqp=sinθ,rij=0,i,j≠p,q.
如果按下式确定角度θ,China's mineral resources evaluation of new technology and the evaluation of the new model is symmetric matrixA经上述变换后,其非对角线元素的平方和将减少,对角线元素的平方和增加,而矩阵中所有元素的平方和保持不变.
由此可知,对称矩阵A每次经过一次变换,其非对角线元素的平方和“向零接近一步”.因此,只要反复进行上述变换,就可以逐步将矩阵A变为对角矩阵.
对角矩阵中对角线上的元素λ0,λ1,…,λn-1即为特征值,而每一步中的平面旋转矩阵的乘积的第i列(i=0,1,…,n-1)即为与λi相应的特征向量.
综上所述,用雅可比方法求n阶对称矩阵A的特征值及相应特征向量的步骤如下:1)令S=In(In为单位矩阵);2)在A中选取非对角线元素中绝对值最大者,设为apq;3)若|apq|<ε,则迭代过程结束.
此时对角线元素aii(i=0,1,…,n-1)即为特征值λi,矩阵S的第i列为与λi相应的特征向量.否则,继续下一步;4)计算平面旋转矩阵的元素及其变换后的矩阵A1的元素.
Its computation formula is as follows China's mineral resources evaluation of new technology and the evaluation model of5)S=S·R(p,q,θ),转(2).
在选取非对角线上的绝对值最大的元素时用如下方法:首先计算实对称矩阵AThe diagonal elements of the square root of sum of squares of China mineral resources and evaluate new technologies and new model set markυ1=υ0/n,在非对角线元素中按行扫描选取第一个绝对值大于或等于υ1的元素αpq进行平面旋转变换,直到所有非对角线元素的绝对值均小于υ1为止.
再设关口υ2=υ1/n,重复这个过程.以此类推,这个过程一直作用到对于某个υk<ε为止.(3)调用说明voidcjcbj(double*a,intn,double*v,doubleeps).
形参说明:a——指向双精度实型数组的指针,体积为n×n,存放n阶实对称矩阵A;返回时,其对角线存放n个特征值;n——整型变量,实矩阵A的阶数;υ——指向双精度实型数组的指针,体积为n×n,返回特征向量,其中第i列为与λi(即返回的αii,i=0,1,……,n-1)对应的特征向量;esp——双精度实型变量.
给定的精度要求.3.矩阵求逆(1)function with select all pivot Gaussian-约当(Gauss-Jordan)消去法求n阶实矩阵A的逆矩阵.
(2)Method Description Gaussian-约当法(全选主元)求逆的步骤如下:首先,对于k从0到n-1做如下几步:1)从第k行、第k列开始的右下角子阵中选取绝对值最大的元素,并记住此元素所在的行号和列号,再通过行交换和列交换将它交换到主元素位置上,这一步称为全选主元;2);3),i,j=0,1,…,n-1(i,j≠k);4)αij-,i,j=0,1,…,n-1(i,j≠k);5)-,i,j=0,1,…,n-1(i≠k);最后,根据在全选主元过程中所记录的行、列交换的信息进行恢复,恢复原则如下:在全选主元过程中,先交换的行、列后进行恢复;原来的行(列)交换用列(行)交换来恢复.
图8-4东昆仑—柴北缘地区基于HOPFIELD模型的铜矿分类结果图(3)调用说明intbrinv(double*a,intn).本函数返回一个整型标志位.
若返回的标志位为0,则表示矩阵A奇异,还输出信息“err**notinv”;若返回的标志位不为0,则表示正常返回.形参说明:a——指向双精度实型数组的指针,体积为n×n.
存放原矩阵A;返回时,存放其逆矩阵A-1;n——整型变量,矩阵的阶数.六、实例实例:柴北缘—东昆仑地区铜矿分类预测.
选取8种因素,分别是重砂异常存在标志、水化异常存在标志、化探异常峰值、地质图熵值、Ms存在标志、Gs存在标志、Shdadlie到区的距离、构造线线密度.构置原始变量,并根据原始数据构造预测模型.
HOPFIELD模型参数设置:训练模式维数8,预测样本个数774,参数个数8,迭代次数330.结果分44类(图8-4,表8-5).表8-5原始数据表及分类结果(部分)续表.
What is the meaning of the inside of the neural network cost function?
Below is the is the cost function in neural networkJ(Θ)J(Θ)的表达式,Looks a bit complicated常见的神经网络结构.What this expression in the calculation?Below we first step by step, separated by a simple example to calculate the.
J(Θ)=−1m∑i=1m∑k=1K[y(i)klog((hΘ(x(i)))k)+(1−y(i)k)log(1−(hΘ(x(i)))k)]+λ2m∑l=1L−1∑i=1sl∑j=1sl+1(Θ(l)j,i)2J(Θ)=−1m∑i=1m∑k=1K[yk(i)log((hΘ(x(i)))k)+(1−yk(i))log(1−(hΘ(x(i)))k)]+λ2m∑l=1L−1∑i=1sl∑j=1sl+1(Θj,i(l))2have the following neural network:其中:LslK=神经网络总共包含的层数=第l层的神经元数目=输出层的神经元数,亦即分类的数目L=神经网络总共包含的层数sl=第l层的神经元数目K=输出层的神经元数,number hypothesiss1=3,s2=2,s3=3s1=3,s2=2,s3=3,则Θ1Θ1的维度为2×42×4,Θ2Θ2的维度为3×33×3.
则有:XT=⎡⎣⎢⎢⎢1x1x2x3⎤⎦⎥⎥⎥,Θ1=[θ110θ120θ111θ121θ112θ122θ113θ123]2×4,Θ2=⎡⎣⎢⎢θ210θ220θ230θ211θ221θ231θ212θ222θ232⎤⎦⎥⎥3×3XT=[1x1x2x3],Θ1=[θ101θ111θ121θ131θ201θ211θ221θ231]2×4,Θ2=[θ102θ112θ122θ202θ212θ222θ302θ312θ322]3×3To recall the first positive propagation formula: z(j)=Θ(j−1)a(j−1)……(1)a(j)=g(z(j)),setting a(j)0=1……(2)hΘ(x)=a(j)=g(z(j))……(3)z(j)=Θ(j−1)a(j−1)……(1)a(j)=g(z(j)),setting a0(j)=1……(2)hΘ(x)=a(j)=g(z(j))……(3), a stamp here At this point we ignoreregularizedterm ①当m=1时; J(Θ)=−1m∑k=1K[y(i)klog((hΘ(x(i)))k)+(1−y(i)k)log(1−(hΘ(x(i)))k)]J(Θ)=−1m∑k=1K[yk(i)log((hΘ(x(i)))k)+(1−yk(i))log(1−(hΘ(x(i)))k)]1.令a1=XT;*z2=Θ1∗a1=[θ110θ120θ111θ121θ112θ122θ113θ123]2×4×⎡⎣⎢⎢⎢1x1x2x3⎤⎦⎥⎥⎥=[θ110+θ111⋅x1+θ112⋅x2+θ113⋅x3θ120+θ121⋅x1+θ122⋅x2+θ123⋅x3]2×11.令a1=XT;*z2=Θ1∗a1=[θ101θ111θ121θ131θ201θ211θ221θ231]2×4×[1x1x2x3]=[θ101+θ111⋅x1+θ121⋅x2+θ131⋅x3θ201+θ211⋅x1+θ221⋅x2+θ231⋅x3]2×1=[z21z22],*a2=g(z2);=[z12z22],*a2=g(z2);2.给a2添加偏置项,并计算a3即hθ(x) 2.给a2添加偏置项,并计算a3即hθ(x); a2=⎡⎣⎢1a21a22⎤⎦⎥;*z3=Θ2∗a2=⎡⎣⎢⎢θ210θ220θ230θ211θ221θ231θ212θ222θ232⎤⎦⎥⎥3×3×⎡⎣⎢1a21a22⎤⎦⎥=⎡⎣⎢⎢z31z32z33⎤⎦⎥⎥;a2=[1a12a22];*z3=Θ2∗a2=[θ102θ112θ122θ202θ212θ222θ302θ312θ322]3×3×[1a12a22]=[z13z23z33];*hθ(x)=a3=g(z3)=⎡⎣⎢⎢g(z31)g(z32)g(z33)⎤⎦⎥⎥=⎡⎣⎢h(x)1h(x)2h(x)3)⎤⎦⎥*hθ(x)=a3=g(z3)=[g(z13)g(z23)g(z33)]=[h(x)1h(x)2h(x)3)]此时我们知道,对于每一个example,will eventually output3个结果,So did the cost function is the3An output log and then multiplied by the corresponding target expectationsy之后,再累加起来.
具体如下:假设 input:XT=⎡⎣⎢⎢⎢1x1x2x3⎤⎦⎥⎥⎥;output:y=⎡⎣⎢100⎤⎦⎥=⎡⎣⎢y1y2y3⎤⎦⎥input:XT=[1x1x2x3];output:y=[100]=[y1y2y3]则有: J(Θ)∗m=[−y1×log(h(x)1)−(1−y1)×log(1−h(x)1)]+[−y2×log(h(x)2)−(1−y2)×log(1−h(x)2)]+[−y3×log(h(x)3)−(1−y3)×log(1−h(x)3)]=[−1×log(h(x)1)−(1−1)×log(1−h(x)1)]+[−0×log(h(x)2)−(1−0)×log(1−h(x)2)]+[−0×log(h(x)3)−(1−0)×log(1−h(x)3)]=−log(h(x)1)−log(1−h(x)2)−log(1−h(x)3)J(Θ)∗m=[−y1×log(h(x)1)−(1−y1)×log(1−h(x)1)]+[−y2×log(h(x)2)−(1−y2)×log(1−h(x)2)]+[−y3×log(h(x)3)−(1−y3)×log(1−h(x)3)]=[−1×log(h(x)1)−(1−1)×log(1−h(x)1)]+[−0×log(h(x)2)−(1−0)×log(1−h(x)2)]+[−0×log(h(x)3)−(1−0)×log(1−h(x)3)]=−log(h(x)1)−log(1−h(x)2)−log(1−h(x)3)在matlab中,After the cost function for vector quantization: J(Θ)=(1/m)∗(sum(−labelY.∗log(Hθ)−(1−labelY).∗log(1−Hθ)));J(Θ)=(1/m)∗(sum(−labelY.∗log(Hθ)−(1−labelY).∗log(1−Hθ)));②当m>1时;J(Θ)=−1m∑i=1m∑k=1K[y(i)klog((hΘ(x(i)))k)+(1−y(i)k)log(1−(hΘ(x(i)))k)]J(Θ)=−1m∑i=1m∑k=1K[yk(i)log((hΘ(x(i)))k)+(1−yk(i))log(1−(hΘ(x(i)))k)]此时,对于每一个exampleProduces a the price of the above,So you just need to put all the for eachexampleThe costs of added up to.
Let's break it down:假设,X=⎡⎣⎢⎢111x11x21x31x12x22x32x13x23x33⎤⎦⎥⎥,假设,X=[1x11x21x311x12x22x321x13x23x33],1.令a1=XT;*z2=Θ1∗a1=[θ110θ120θ111θ121θ112θ122θ113θ123]2×4×⎡⎣⎢⎢⎢⎢1x11x12x131x21x22x231x31x32x33⎤⎦⎥⎥⎥⎥4×3=1.令a1=XT;*z2=Θ1∗a1=[θ101θ111θ121θ131θ201θ211θ221θ231]2×4×[111x11x12x13x21x22x23x31x32x33]4×3=[θ110+θ111⋅x11+θ112⋅x12+θ113⋅x13θ120+θ121⋅x11+θ122⋅x12+θ123⋅x13θ110+θ111⋅x21+θ112⋅x22+θ113⋅x23θ120+θ121⋅x21+θ122⋅x22+θ123⋅x23θ110+θ111⋅x31+θ112⋅x32+θ113⋅x33θ120+θ121⋅x31+θ122⋅x32+θ123⋅x33]2×3[θ101+θ111⋅x11+θ121⋅x21+θ131⋅x31θ101+θ111⋅x12+θ121⋅x22+θ131⋅x32θ101+θ111⋅x13+θ121⋅x23+θ131⋅x33θ201+θ211⋅x11+θ221⋅x21+θ231⋅x31θ201+θ211⋅x12+θ221⋅x22+θ231⋅x32θ201+θ211⋅x13+θ221⋅x23+θ231⋅x33]2×3=[z211z221z212z222z213z223]2×3,*a2=g(z2);=[z112z122z132z212z222z232]2×3,*a2=g(z2);2.给a2添加偏置项,并计算a3即hθ(x) 2.给a2添加偏置项,并计算a3即hθ(x);a2=⎡⎣⎢1a211a2211a212a2221a213a223⎤⎦⎥3×3;*z3=Θ2∗a2=⎡⎣⎢⎢θ210θ220θ230θ211θ221θ231θ212θ222θ232⎤⎦⎥⎥3×3×⎡⎣⎢1a211a2211a212a2221a213a223⎤⎦⎥3×3a2=[111a112a122a132a212a222a232]3×3;*z3=Θ2∗a2=[θ102θ112θ122θ202θ212θ222θ302θ312θ322]3×3×[111a112a122a132a212a222a232]3×3*hθ(x)=a3=g(z3)=⎡⎣⎢⎢g(z311)g(z321)g(z331)g(z312g(z322g(z332)g(z313))g(z323))g(z333)⎤⎦⎥⎥*hθ(x)=a3=g(z3)=[g(z113)g(z123g(z133))g(z213)g(z223g(z233))g(z313)g(z323)g(z333)]=⎡⎣⎢⎢⎢⎢m=1时每个exampleAll the corresponding output;h(x1)1h(x1)2h(x1)3m=2时h(x2)1h(x2)2h(x2)3m=3时;h(x3)1h(x3)2h(x3)3⎤⎦⎥⎥⎥⎥=[m=1时每个exampleAll the corresponding output;m=2时m=3时;h(x1)1h(x2)1h(x3)1h(x1)2h(x2)2h(x3)2h(x1)3h(x2)3h(x3)3]假设 input:X=⎡⎣⎢⎢111x11x21x31x12x22x32x13x23x33⎤⎦⎥⎥;output:y=⎡⎣⎢122⎤⎦⎥=⎡⎣⎢y1y2y3⎤⎦⎥input:X=[1x11x21x311x12x22x321x13x23x33];output:y=[122]=[y1y2y3]The example of the background to use neural network to identify the script,即y1=1Said the expected output1,y2=y3=2,means its expected output is2.
At the time of calculation cost function to each of the corresponding output is converted to contain only0,1的向量y1=1Said the expected output1,y2=y3=2,means its expected output is2.
At the time of calculation cost function to each of the corresponding output is converted to contain only0,1The vector of: y1=⎡⎣⎢100⎤⎦⎥;y2=⎡⎣⎢010⎤⎦⎥;y3=⎡⎣⎢010⎤⎦⎥*labelY=⎡⎣⎢⎢⎢m=1100m=2010m=3010⎤⎦⎥⎥⎥y1=[100];y2=[010];y3=[010]*labelY=[m=1m=2m=3100011000]About how to transform average output value into contains only0,1的向量,Click here for(MalabIn the form of vector quantization): J(Θ)=(1/m)∗(sum(sum[−labelY.∗log(Hθ)−(1−labelY).∗log(1−Hθ)]));J(Θ)=(1/m)∗(sum(sum[−labelY.∗log(Hθ)−(1−labelY).∗log(1−Hθ)]));加上regularizedterm regular=λ2m∑l=1L−1∑i=1sl∑j=1sl+1(Θ(l)j,i)2;regular=λ2m∑l=1L−1∑i=1sl∑j=1sl+1(Θj,i(l))2;其实regularizedtermare all the parameters of each layer(Θlj,i,j≠0,That in addition to the first column of each layer offset item corresponding parameters)(Θj,il,j≠0,That in addition to the first column of each layer offset item corresponding parameters)The sum of squares can be added.
Example of this is specific to this article:Θ1=[θ110θ120θ111θ121θ112θ122θ113θ123]2×4,Θ2=⎡⎣⎢⎢θ210θ220θ230θ211θ221θ231θ212θ222θ232⎤⎦⎥⎥3×3Θ1=[θ101θ111θ121θ131θ201θ211θ221θ231]2×4,Θ2=[θ102θ112θ122θ202θ212θ222θ302θ312θ322]3×3regular=(θ111)2+(θ112)2+(θ113)2+(θ121)2+(θ122)2+(θ123)2+(θ211)2+(θ212)2+(θ221)2+(θ222)2+(θ231)2+(θ232)2regular=(θ111)2+(θ121)2+(θ131)2+(θ211)2+(θ221)2+(θ231)2+(θ112)2+(θ122)2+(θ212)2+(θ222)2+(θ312)2+(θ322)2Matlabvectorized to:s_Theta1=sum(Theta1.^2);%First find the square of all elements,Then add each columnr_Theta1=sum(s_Theta1)-s_Theta1(1,1);%Subtract the sum of the first columns_Theta2=sum(Theta2.^2);r_Theta2=sum(s_Theta2)-s_Theta2(1,1);regular=(lambda/(2*m))*(r_Theta1+r_Theta2);.
什么是“小波神经网络”?what can you do?
小波神经网络(Wavelet Neural Network, WNN)是在小波分析研究获得突破的基础上提出的一种人工神经网络.
它是基于小波分析理论以及小波变换所构造的一种分层的、多分辨率的新型人工神经网络模型. 即用非线性小波基取代了通常的非线性Sigmoid 函数,其信号表述是通过将所选取的小波基进行线性叠加来表现的.
它避免了BP 神经网络结构设计的盲目性和局部最优等非线性优化问题,大大简化了训练,具Has the strong function of learning ability and generalization ability及广阔的应用前景.
“小波神经网络”的应用:1、in image processing,Can be used for image compression、分类、识别与诊断,去污等.在医学成像方面的减少B超、CT、核磁共振成像的时间,Improve resolution, etc..2、Its application in signal analysis is widely.
它可以用于边界的处理与滤波、时频分析、信噪分离与提取弱信号、求分形指数、The signal recognition and diagnosis and multi-scale edge detection and so on.3、在工程技术等方面的应用.
including computer vision、computer graphics、曲线设计、湍流、And the research of the remote universe biological medicine.扩展资料:Wavelet neural network work about began in the early1992 年,The researchers are mainlyZhang Q、Harold H S and Jiao Licheng et al.
其中,Jiao li cheng in his masterpiece《Application and Realization of Neural Network》From the theory of wavelet neural network are discussed in detail.近年来,People in the aspect of theory and application of the wavelet neural network is a lot of research work.
The wavelet neural network has the following features:首先,Wavelet primitives and the determination of the entire network structure has a reliable theoretical basis for,可避免BP The blindness of neural network such as the structural design of;其次,The weight coefficient of the linear distribution and learning objective function convexity,The network training process the most superior fundamentally avoids the local nonlinear optimization problem;第三,Has the strong function of learning ability and generalization ability.
How deep neural network training?
Coursera的Ng机器学习,UFLDL都看过.没记错的话NgIn machine learning is directly given formula,Although you may know how to solve,But even if you don't know that finish the homework also is not a problem,Just follow the formula.
Anyway, I look at that time, the in the mind and failed to more clearly understand.I feel like I want to learn about deep learningUFLDL教程-Ufldl是不错的.有习题,Finish do to deep learning have more deep understanding,But it's not always clear.
后来看了LiFeiFei的StanfordUniversityCS231n:ConvolutionalNeuralNetworksforVisualRecognition,I feel rightCNNunderstanding has been greatly improved.
Sink down and pushing formula,多思考,See back propagation is essentially the chain rule(Although I knew,But then still understand a daze).All of the gradient are to the finallossobtained by derivation,That is a scalar matrixor向量的求导.
Of course, at the same time also learned a lot of other aboutcnn的.And suggest that you should not only ex,Better to write one yourselfcnn,This process may let you learn many more details and may ignore things.
The network can use the middle tier construct multi-layer abstract,As we do in Boolean line.
例如,If we in visual pattern recognition,So in the first layer of neurons may learn to recognize edge,On the edge of the second layer of neurons can learn to identify more complex shape on the basis of,such as triangles or rectangles.The third layer will be able to identify more complex shape.依此类推.
These layers of abstraction look to a depth of network a kind of learning the ability to solve the problem of complex pattern recognition.然后,As seen in the line of sample like that,There exists a theoretical research results tell us depth in nature than the shallow network more powerful.
Neural network and wavelet analysis what is the application in automobile engine troubleshooting?
The car is a commonly used to transport in our lives,Then the neural network and wavelet analysis what is the application in automobile engine troubleshooting?Look at my next explain in detail.一,The application of wavelet analysis in troubleshooting wavelet packet decomposition and fault feature extraction.
On the surface of the cylinder head vibration signal is composed of a series of transient response signals,Representing the vibration of the cylinder source response signal:1For the cylinder combustion excitation response;2Exhaust valve is opened when the throttle valve impact.
When the valve clearance is abnormal,When the energy of vibration signal is greater than the current impact effect,Vibration signal of the main components in stable from the impact of vibration signal and noise,Relatively small signal energy.
因此,The energy changes that can take advantage of each frequency band to extract the fault feature,Decomposition coefficients by wavelet packet{4]get the energy of the band.二,The role of neural network in troubleshooting the basic principle of neural network and fault identification.
Artificial neural network with its massively parallel processing、分布式存储、自组织、The adaptive and self-learning ability,And is suitable for processing inaccurate or vague information and attention5].其中,最成熟的是BP神经网络.值,Until the output is close to ideal output signal6.
因此,BPNeural network can approximate any finite dimensional function with arbitrary precision,适用于模式识别.Now take the signal for each operating condition5个样本,按照⒉Part of the steps described in35group sample signals for programming,To extract the sample signal energy eigenvector.
三,Wavelet analysis and neural network application summary for the collapse of fault diagnosis of diesel engine valve mechanism,This article will on measurement of cylinder head vibration signal wavelet threshold de-noising pretreatment.And then according to the frequency characteristic of the signal,The time-frequency analysis was carried out on the signal after wavelet packet decomposition.
The constructed energy eigenvector accurately reflect the state of valve clearance under the change of cylinder head vibration signal energy.
实验表明,Using energy eigenvectors,BPNeural network can complete from vibration signal space more accurately the nonlinear mapping to the state of valve clearance space,To better meet the requirements of diesel engine condition detection and fault diagnosis.
Research Status of Neural Networks
Spectral analysis because of its sensitive to、高精度、无破坏、To quickly detect material chemical composition and relative content and widely used in analytical chemistry、生物化学与分子生物学、农业、医学等领域.
目前,Spectrum analysis technology becoming mature,Introducing the theory of spectral analysis of hyperspectral remote sensing technology application is increasingly wide,especially in the agricultural sector,Can effectively obtain the farmland information、Judging crop growth、Estimating crop yields、Extract disease information.
Although spectral analysis technology has a strong material spectrum“perspective”,但在分析“同谱异物”和“Foreign bodies with spectrum”Need combined with modern analysis methods such as things,如小波变换、卡尔曼滤波、人工神经网络(ArtificialNeuralNet-work,ANN)、遗传算法(GeneticAlgorithm,GA)等.
In the field of spectral analysis,ANNMany used for quantitative analysis of the physical and biochemical composition of(Chen Zhenning et al,2001;Yin Chunsheng et al,2000),Also has more application in photometric analysis,如,Yu Hongmei et al(2002)利用ANNAnalysis of chromium and zirconium compound absorption spectrum,Combined with the points photometric method for the determination of.
ANNIn the nonlinear calibration and spectral data processing applications are(Blank,1993;Li-min fang etc.;2008).
while in pattern recognitionANN应用最为广泛,如,Eicemanetal.(2006)利用遗传算法(是ANN的一种)Classifying hybrid wavelet coefficients recognition.
目前,自组织特征映射(Self-organizingFeatureMaps,SOFM)Neural network in pattern recognition of hyperspectral images,Also less at home and abroad research and application,And combined with the application research of remote sensing spectrum d spectrum analysis technology is less.
SOFMCommonly used in remote sensing image processing,如,Moshouetal.(2005)利用SOFMNeural network for data fusion,reduce the classification error to1%;Doucetteetal.(2001)根据SOFM设计的SORM算法,From the classification of high resolution images to extract the road;Toivanenetal.(2003)利用SOFMNeural network was extracted from multispectral image edge,And points out that the method can be applied to large amount of data the image edge extraction;Moshouetal.(2006)根据5137Spectral data of leaves,利用SOFMNeural network to identify early wheat stripe rust,准确率高达99%.
然而,SOFMDon't need to input mode expectations(In some classification problem,It is hard to obtain samples of the a priori categories),其区别于BP(BackPropagation)Other neural network model is the most important feature is the ability to automatically find the inherent law and the essence of the sample properties,This greatly broadensSOFMApplications in pattern recognition and classification of.
基于以上几点,From the Angle of the spectral analysis in this chapter analyze the hyperspectral remote sensing image recognition and information extraction,Under different spectral model is given in,Different decompositions of hyperspectral data,之后利用SOFMTo have high spectral overlap degree is used to identify the classification of the decomposition of these,Combined with spectral analysis was carried out on the sample point category recognition,And through to the wheat stripe rust disease severity information extraction,Hyperspectral image spectrum d and spectral analysis is put forward new way of.
What are the advantages of compound neural network?
Neural network is deep learning is an important technology in artificial intelligence,But the neural network is also has certain limitation,In dealing with special situations there will be a bit of trouble,Yet now there is a special way that neural network can be more powerful than before,This technique is the complex neural network.
So what are the advantages of compound neural network?Below we will introduce you to the concept of.
In fact, if you want to learn compound neural network,Just need to know the principle of compound,The compound is a general principle,We can describe it as a kind of believe that the world is knowable belief,we can break things down、理解它们,And then rearrange them freely in the mind.
这其中的关键假设是,Things are in accordance with a certain set of rules from basic substructure composite with larger structure.这意味着,We can learn from the limited data to the substructure and combination rule,Then generalize them to compound the situation.
当然,Compound neural network and the depth of different neural network,Characterization of compound model need to be structured,Among them to explicitly expressed object structure and substructure.
Compound model also have the extrapolation to have never seen the data,reason about the system、Intervention and Diagnosis,And for the same knowledge structure's ability to answer different questions.
The compound model has the advantages of the concept on some task to get the preliminary validation,in terms of identification,Compound neural network recognition ability is higher than the depth of the ability of the neural network,The depth of the neural network will not be able to maintain a high level of performance.
There are also some nontrivial visual task also showed the same trend,to speculate on the content of the last;Image is the change rule between compound,and there will be interference.
Natural language models such as neural network module,Because they have the dynamic network structure,Able to capture some meaningful combination,Can defeat the traditional neural network in such tasks.
当然,Compound model also has a lot of ideal theoretical properties,In can explain and superb performance to generate samples.This allows us to more easily diagnostic error,Neural network is better than depth to the black box model is more difficult to cheat.
But the compound model is difficult to learn,Because it needs to learn basic structure and composite method at the same time.而且,In order to be able to analysis to generate the way,Compound model also need to match the object model and scenario generation type.According to the classification to generate images is still a difficult problem.
Of course, more basic knowledge,That is processing the combination explosion problem also need to learn things in a three-dimensional world common sense model,And learn the model and the corresponding relationship of the image.
In this article we give us a lot about the advantages of compound model,These advantages are the consistent good opinion of the engineers.相信在未来,There will be more model is used to solve the problem of more.
What are the common methods of data mining?
1、The decision tree method of decision tree in solving classification and prediction has a strong ability to,It is expressed in the form of law,While these laws expressed in a series of problems come out,By constantly ask questions can eventually export the desired results.
The top is a typical decision tree roots,There are a lot of leaves at the bottom,It will record down into different subsets,Each subset of the fields may involve a simple rule.此外,The decision tree may have different appearance,e.g. binary tree、The ternary tree or mixed type of decision tree.
2、Nn nn is to simulate the structure and function of biological nervous system,是一种通过训练来学习的非线性预测模型,它将每一个连接看作一个处理单元,试图模拟人脑神经元的功能,可完成分类、聚类、特征挖掘等多种数据挖掘任务.
神经网络的学习方法主要表现在权值的修改上.
其优点是具有抗干扰、非线性学习、联想记忆功能,对复杂情况能得到精确的预测结果;缺点首先是不适合处理高维变量,不能观察中间的学习过程,具有“黑箱”性,输出结果也难以解释;其次是需较长的学习时间.
神经网络法主要应用于数据挖掘的聚类技术中.
3、Association rules method of association rules is to describe the relationship between a data in the database the rule,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系.
在客户关系管理中,通过对企业的客户数据库里的大量数据进行挖掘,可以从大量的记录中发现有趣的关联关系,找出影响市场营销效果的关键因素,为产品定位、定价与定制客户群,客户寻求、细分与保持,市场营销与推销,营销风险评估和诈骗预测等决策支持提供参考依据.
4、Genetic algorithm and genetic algorithm to simulate the arising in the course of natural selection and genetic breeding、交配和基因突变现象,是一种采用遗传结合、遗传交叉变异及自然选择等操作来生成实现规则的、基于进化理论的机器学习方法.
它的基本观点是“适者生存”原理,具有隐含并行性、易于和其他模型结合等性质.主要的优点是可以处理许多数据类型,同时可以并行处理各种数据;缺点是需要的参数太多,编码困难,一般计算量比较大.
遗传算法常用于优化神经元网络,能够解决其他技术难以解决的问题.
5、Clustering analysis method, clustering analysis is a set of data is divided into several categories according to the similarity and difference,其目的是使得属于同一类别的数据间的相似性尽可能大,不同类别中的数据间的相似性尽可能小.
It is divided into four categories according to their definitions can:基于层次的聚类方法;Partition Clustering Algorithm;基于密度的聚类算法;Grid clustering algorithm.Commonly used classical clustering methods areK-mean,K-medoids,ISODATA等.
6、Fuzzy set method fuzzy set method is the use of fuzzy set theory to problems in fuzzy evaluation、模糊决策、模糊模式识别和模糊聚类分析.模糊集合理论是用隶属度来描述模糊事物的属性.系统的复杂性越高,模糊性就越强.
7、webPage digging through toWeb的挖掘,可以利用Web的海量数据进行分析,收集政治、经济、政策、科技、金融、各种市场、竞争对手、供求信息、客户等有关的信息,集中精力分析和处理那些对企业有重大或潜在重大影响的外部环境信息和内部经营信息,并根据分析结果找出企业管理过程中出现的各种问题和可能引起危机的先兆,对这些信息进行分析和处理,以便识别、分析、评价和管理危机.
8、Logistic regression analysis reflect the transaction attribute values in the database on the time features of,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的相关关系等.
9、Rough set method is a kind of new processing vague、不精确、不完备问题的数学工具,可以处理数据约简、数据相关性发现、数据意义的评估等问题.
其优点是算法简单,在其处理过程中可以不需要关于数据的先验知识,可以自动找出问题的内在规律;缺点是难以直接处理连续的属性,须先进行属性的离散化.因此,连续属性的离散化问题是制约粗糙集理论实用化的难点.
10、Link analysis it was based on the relationship of the subject,由人与人、物与物或是人与物的关系发展出相当多的应用.Such as telecommunications services can be collected by link analysis customer telephone use time and frequency,进而推断顾客使用偏好为何,提出有利于公司的方案.
apart from telecommunications,More and more marketing companies also use a link analysis for is advantageous to the enterprise of research.
Artificial intelligence, including what technology?
人工智能包括五大核心技术: 1.计算机视觉:计算机视觉技术运用由图像处理操作及机器学习等技术所组成的序列来将图像分析任务分解为便于管理的小块任务.
2.机器学习:机器学习是从数据中自动发现模式,模式一旦被发现便可以做预测,处理的数据越多,预测也会越准确.3.自然语言处理:对自然语言文本的处理是指计算机拥有的与人类类似的对文本进行处理的能力.
例如自动识别文档中被提及的人物、地点等,或将合同中的条款提取出来制作成表.4.机器人技术:近年来,随着算法等核心技术提升,机器人取得重要突破.例如无人机、家务机器人、医疗机器人等.
5.生物识别技术:生物识别可融合计算机、光学、声学、生物传感器、生物统计学,利用人体固有的生体特性如指纹、人脸、虹膜、静脉、声音、步态等进行个人身份鉴定,最初运用于司法鉴定.
人工智能的核心技术是什么?
1计算机视觉.Computer vision is refers to the computer can recognize the object from the image、场景和活动的能力.
它有着广泛的应用,Includes medical imaging analysis,for disease prediction、诊断和治疗;人脸识别;Security and surveillance field is used to identify the suspect;在购物方面,Consumers can use smart phone products in order to obtain more shopping choices.2机器学习.
Machine learning is refers to the computer system does not need to follow the display program instructions,But the ability to rely on data to improve its performance.它的应用也很广泛,Mainly aimed at generating huge data activity,比如销售预测,库存管理,石油和天然气勘探,and public health notices, etc..
3自然语言处理.It refers to the computer to be like humans have text processing capacity.举例来说,Is in a lot of emails,With the classified method of machine learning to drive,To distinguish whether an email is spam.
4Robots will machine vision、自动规划等认知技术整合至极小却高性能的传感器、制动器以及设计巧妙的硬件中,This creates a robot,It has the ability to work with human.例如无人机,And in the workshop for humans to share the work“cobots”等.
5Speech recognition speech recognition is mainly focus on automatically and accurately transcribed human voice technology.语音识别的主要应用包括医疗听写、语音书写、电脑系统声控、电话客服等.最近推出了一个允许用户通过语音下单的移动APP.
边栏推荐
猜你喜欢
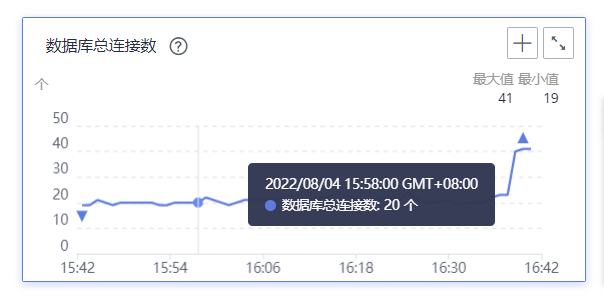
What should I do if the mysql data query causes the cup to be full because the query time span is too large
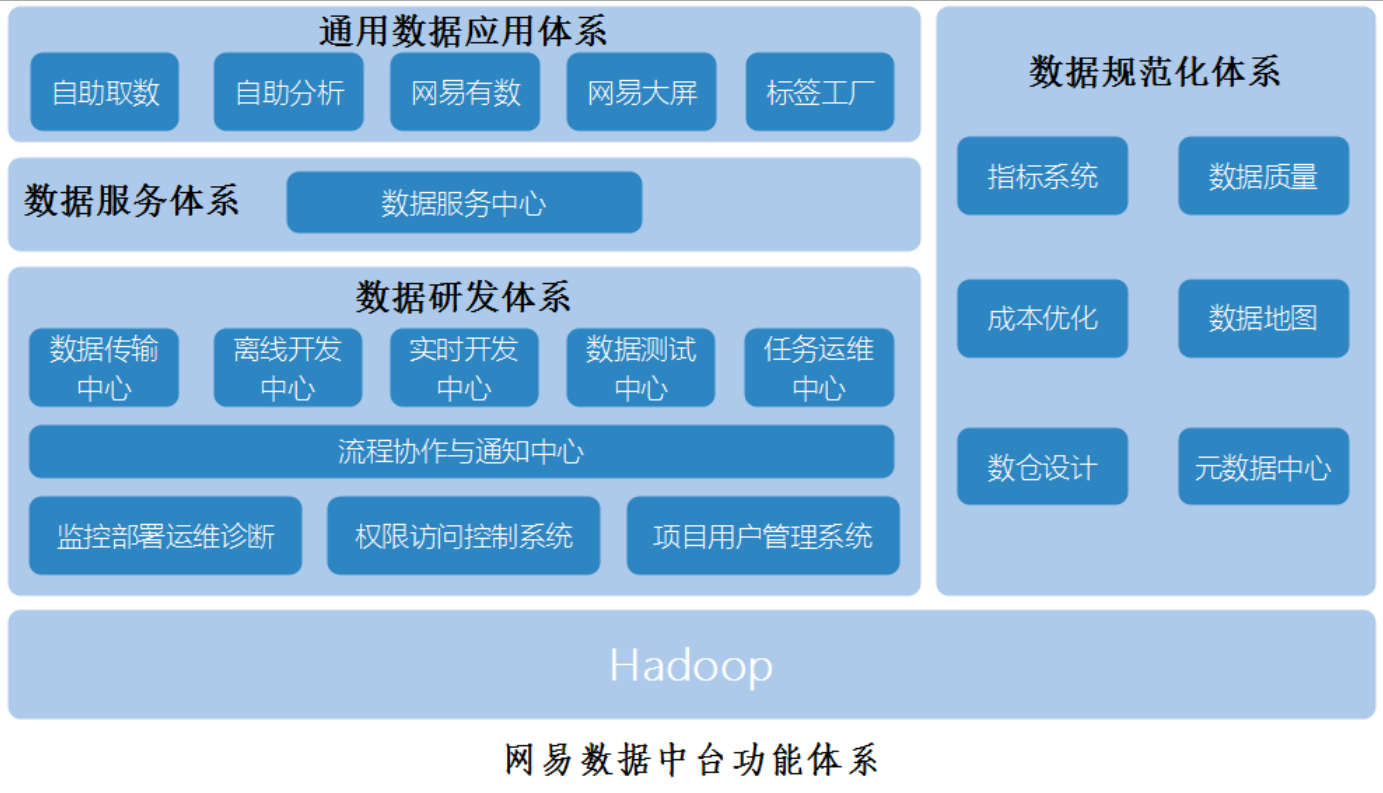
数据中台方案分析和发展方向
Data middle platform program analysis and development direction
WooCommerce电子商务WordPress插件-赚美国人的钱
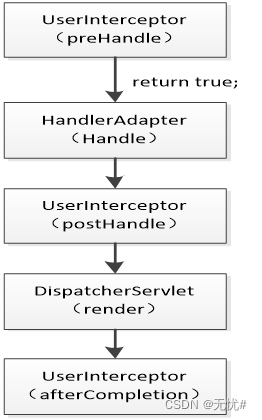
Validate the execution flow of the interceptor
Simple interaction between server and client
canvas图形操作(缩放、旋转、位移)
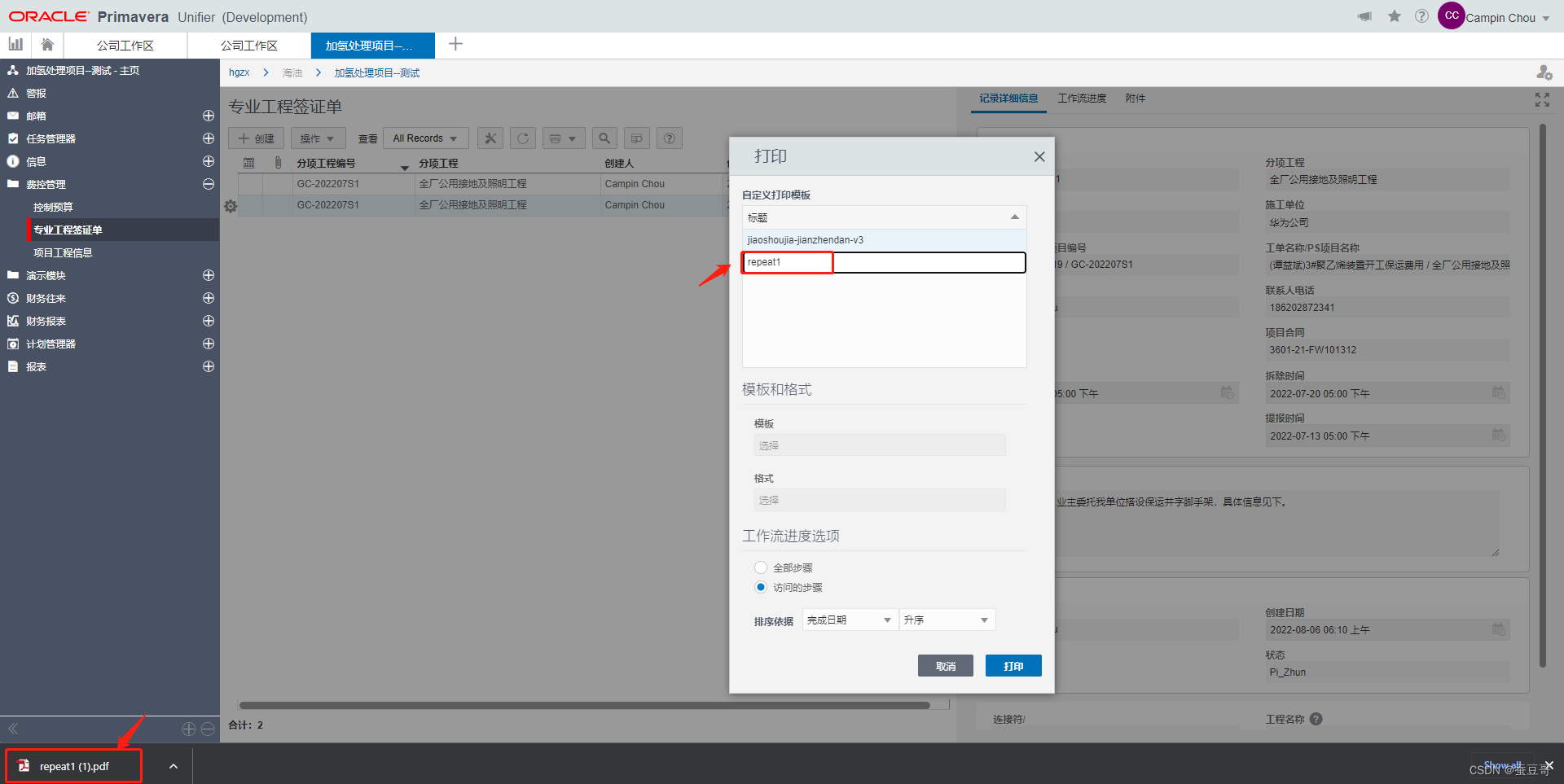
Primavera Unifier 自定义报表制作及打印分享
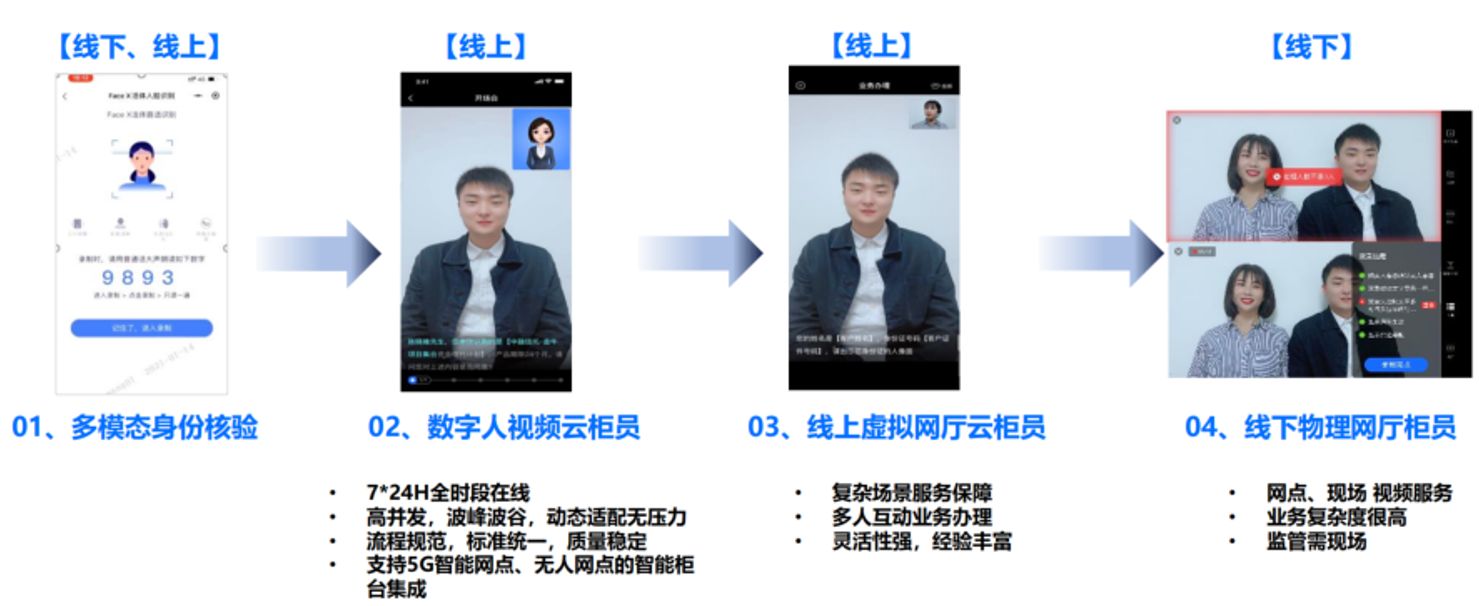
音视频+AI,中关村科金助力某银行探索发展新路径 | 案例研究
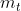
基于 VIVADO 的 AM 调制解调(1)方案设计
随机推荐
pycharm cancel msyql expression highlighting
Detailed Explanation of the Level 5 Test Center of the Chinese Institute of Electronics (1)-string type string
音视频+AI,中关村科金助力某银行探索发展新路径 | 案例研究
训练一个神经网络要多久,神经网络训练时间过长
Network model (U - net, U - net++, U - net++ +)
gRPC系列(一) 什么是RPC?
Typora和基本的Markdown语法
MySql事务
基于hydra库实现yaml配置文件的读取(支持命令行参数)
wordpress插件开发03-简单的all in one seo 插件开发
前几天,小灰去贵州了
清除微信小程序button的默认样式
Adobe LiveCycle Designer 报表设计器
nodejs worker_threads的事件监听问题
mysql中查询多个表中的数据量
中移链EOSJS实战使用
利用mindspore下面mindzoo里面的yolov3-darknet53进行目标识别,模型训练不收敛
canvas文字绘制(大小、粗体、倾斜、对齐、基线)
自定义卷积核的分组转置卷积如何实现?
HDRP Custom Pass Shader Get world coordinates and near clipping plane coordinates