本章解释了如何开始使用 Pgpool-II。
安装
在本节中,我们假设您已经安装了 Pgpool-II 与 PostgreSQL 集群。
你的第一个复制(Replication)
在本节中,我们将解释如何使用 Pgpool-II 管理具有流复制的 PostgreSQL 集群,这是最常见的设置之一。
在继续之前,您应该正确设置 pgpool.conf 与流复制模式。Pgpool-II 提供了示例配置,配置文件位于 /usr/local/etc,默认从源代码安装。您可以将 pgpool.conf.sample 复制为 pgpool.conf。
cp /usr/local/etc/pgpool.conf.sample pgpool.conf如果你打算使用 pgpool_setup,输入:
pgpool_setup这将创建一个具有流复制模式安装、主 PostgreSQL 安装和异步备用 PostgreSQL 安装的 Pgpool-II。
从现在开始,我们假设您使用 pgpool_setup 在当前目录下创建安装。请注意,在执行 pgpool_setup 之前,当前目录必须是空的。
要启动整个系统,请输入:
./startall系统启动后,您可以通过向任何数据库发出名为 show pool_nodes 的伪 SQL 命令来检查集群状态。 pgpool_setup 自动创建 test 数据库。我们使用数据库。注意端口号是 11000,这是 pgpool_setup 分配给 Pgpool-II 的默认端口号。
$ psql -p 11000 -c "show pool_nodes" test
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+-------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | /tmp | 11002 | up | 0.500000 | primary | 0 | false | 0 | 2019-01-31 10:23:09
1 | /tmp | 11003 | up | 0.500000 | standby | 0 | true | 0 | 2019-01-31 10:23:09
(2 rows)结果显示 status 列为 up,表示 PostgreSQL 已启动并正在运行,这很好。
测试复制
让我们使用标准 PostgreSQL 安装附带的基准工具 pgbench 来测试复制功能。键入以下内容以创建基准表
$ pgbench -i -p 11000 test要查看 replication 是否正常工作,请直接连接到主服务器和备用服务器,看看它们是否返回相同的结果。
$ psql -p 11002 test
\dt
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+---------
public | pgbench_accounts | table | t-ishii
public | pgbench_branches | table | t-ishii
public | pgbench_history | table | t-ishii
public | pgbench_tellers | table | t-ishii
(4 rows)
\q
$ psql -p 11003 test
\dt
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+---------
public | pgbench_accounts | table | t-ishii
public | pgbench_branches | table | t-ishii
public | pgbench_history | table | t-ishii
public | pgbench_tellers | table | t-ishii
(4 rows)主服务器(端口 11002)和备用服务器(端口 11003)返回相同的结果。接下来,让我们运行 pgbench 一段时间并检查结果。
$ pgbench -p 11000 -T 10 test
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 10 s
number of transactions actually processed: 4276
latency average = 2.339 ms
tps = 427.492167 (including connections establishing)
tps = 427.739078 (excluding connections establishing)
$ psql -p 11002 -c "SELECT sum(abalance) FROM pgbench_accounts" test
sum
--------
216117
(1 row)
$ psql -p 11003 -c "SELECT sum(abalance) FROM pgbench_accounts" test
sum
--------
216117
(1 row)同样,结果是相同的。
测试负载均衡(Load Balance)
Pgpool-II 允许读取查询负载均衡。默认情况下启用。要查看效果,让我们使用 pgbench -S 命令。
$ ./shutdownall
$ ./startall
$ pgbench -p 11000 -c 10 -j 10 -S -T 60 test
starting vacuum...end.
transaction type: <builtin: select only>
scaling factor: 1
query mode: simple
number of clients: 10
number of threads: 10
duration: 60 s
number of transactions actually processed: 1086766
latency average = 0.552 ms
tps = 18112.487043 (including connections establishing)
tps = 18125.572952 (excluding connections establishing)
$ psql -p 11000 -c "show pool_nodes" test
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+-------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | /tmp | 11002 | up | 0.500000 | primary | 537644 | false | 0 | 2019-01-31 11:51:58
1 | /tmp | 11003 | up | 0.500000 | standby | 548582 | true | 0 | 2019-01-31 11:51:58
(2 rows)select_cnt 列显示有多少 SELECT 被分派到每个节点。由于使用默认配置,Pgpool-II 尝试调度相同数量的 SELECT,因此该列显示几乎相同的数字。
测试故障转移(Fail Over)
当 PostgreSQL 服务器宕机时,Pgpool-II 允许自动故障转移。在这种情况下,Pgpool-II 将服务器的状态设置为 down 并使用剩余的服务器继续数据库操作。
$ pg_ctl -D data1 stop
waiting for server to shut down.... done
server stopped
$ psql -p 11000 -c "show pool_nodes" test
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+-------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | /tmp | 11002 | up | 0.500000 | primary | 4276 | true | 0 | 2019-01-31 12:00:09
1 | /tmp | 11003 | down | 0.500000 | standby | 1 | false | 0 | 2019-01-31 12:03:07
(2 rows)备用节点被 pg_ctl 命令关闭。Pgpool-II 检测到它并分离备用节点。show pool_nodes 命令显示备用节点处于关闭状态。您可以在没有备用节点的情况下继续使用集群:
$ psql -p 11000 -c "SELECT sum(abalance) FROM pgbench_accounts" test
sum
--------
216117
(1 row)如果主服务器宕机了怎么办?在这种情况下,剩余的备用服务器之一被提升为新的主服务器。 对于这个测试,我们从两个节点都启动的状态开始。
$ psql -p 11000 -c "show pool_nodes" test
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+-------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | /tmp | 11002 | up | 0.500000 | primary | 0 | false | 0 | 2019-01-31 12:04:58
1 | /tmp | 11003 | up | 0.500000 | standby | 0 | true | 0 | 2019-01-31 12:04:58
(2 rows)
$ pg_ctl -D data0 stop
waiting for server to shut down.... done
server stopped
$ psql -p 11000 -c "show pool_nodes" test
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+-------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | /tmp | 11002 | down | 0.500000 | standby | 0 | false | 0 | 2019-01-31 12:05:20
1 | /tmp | 11003 | up | 0.500000 | primary | 0 | true | 0 | 2019-01-31 12:05:20
(2 rows)现在主节点从 0 变成了 1。里面发生了什么?当节点 0 宕机时,Pgpool-II 检测到它并执行 pgpool.conf 中定义的 failover_command。这是文件的内容。
#! /bin/sh
# Execute command by failover.
# special values: %d = node id
# %h = host name
# %p = port number
# %D = database cluster path
# %m = new main node id
# %M = old main node id
# %H = new main node host name
# %P = old primary node id
# %R = new main database cluster path
# %r = new main port number
# %% = '%' character
failed_node_id=$1
failed_host_name=$2
failed_port=$3
failed_db_cluster=$4
new_main_id=$5
old_main_id=$6
new_main_host_name=$7
old_primary_node_id=$8
new_main_port_number=$9
new_main_db_cluster=${10}
mydir=/home/t-ishii/tmp/Tutorial
log=$mydir/log/failover.log
pg_ctl=/usr/local/pgsql/bin/pg_ctl
cluster0=$mydir/data0
cluster1=$mydir/data1
date >> $log
echo "failed_node_id $failed_node_id failed_host_name $failed_host_name failed_port $failed_port failed_db_cluster $failed_db_cluster new_main_id $new_main_id old_main_id $old_main_id new_main_host_name $new_main_host_name old_primary_node_id $old_primary_node_id new_main_port_number $new_main_port_number new_main_db_cluster $new_main_db_cluster" >> $log
if [ a"$failed_node_id" = a"$old_primary_node_id" ];then # main failed
! new_primary_db_cluster=${mydir}/data"$new_main_id"
echo $pg_ctl -D $new_primary_db_cluster promote >>$log # let standby take over
$pg_ctl -D $new_primary_db_cluster promote >>$log # let standby take over
sleep 2
fi该脚本从 Pgpool-II 接收必要的信息作为参数。如果主服务器宕机,它会执行 pg_ctl -D data1 promote ,这应该将备用服务器提升为新的主服务器。
测试在线恢复(Online Recovery)
Pgpool-II 允许通过称为 Online Recovery 的技术来恢复宕机的节点。 这会将数据从主节点复制到备用节点,以便与主节点同步。 这可能需要很长时间,并且在此过程中可能会更新数据库。这没问题,因为在流式配置中,备用服务器将接收 WAL 日志并将其应用于赶上主服务器。为了测试在线恢复,让我们从之前的集群开始,其中节点 0 处于关闭状态。
$ pcp_recovery_node -p 11001 -n 0
Password:
pcp_recovery_node -- Command Successful
$ psql -p 11000 -c "show pool_nodes" test
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+-------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | /tmp | 11002 | up | 0.500000 | standby | 0 | false | 0 | 2019-01-31 12:06:48
1 | /tmp | 11003 | up | 0.500000 | primary | 0 | true | 0 | 2019-01-31 12:05:20
(2 rows)pcp_recovery_node 是 Pgpool-II 安装附带的控制命令之一。参数 -p 是指定分配给命令的端口号,它是 pgpool_setup 设置的 11001。参数 -n 是指定要恢复的节点 id。执行命令后,节点 0 恢复到 up 状态。
pcp_recovery_node 执行的脚本在 pgpool.conf 中被指定为 recovery_1st_stage_command。这是 pgpool_setup 安装的文件。
#! /bin/sh
psql=/usr/local/pgsql/bin/psql
DATADIR_BASE=/home/t-ishii/tmp/Tutorial
PGSUPERUSER=t-ishii
main_db_cluster=$1
recovery_node_host_name=$2
DEST_CLUSTER=$3
PORT=$4
recovery_node=$5
pg_rewind_failed="true"
log=$DATADIR_BASE/log/recovery.log
echo >> $log
date >> $log
if [ $pg_rewind_failed = "true" ];then
$psql -p $PORT -c "SELECT pg_start_backup('Streaming Replication', true)" postgres
echo "source: $main_db_cluster dest: $DEST_CLUSTER" >> $log
rsync -C -a -c --delete --exclude postgresql.conf --exclude postmaster.pid \
--exclude postmaster.opts --exclude pg_log \
--exclude recovery.conf --exclude recovery.done \
--exclude pg_xlog \
$main_db_cluster/ $DEST_CLUSTER/
rm -fr $DEST_CLUSTER/pg_xlog
mkdir $DEST_CLUSTER/pg_xlog
chmod 700 $DEST_CLUSTER/pg_xlog
rm $DEST_CLUSTER/recovery.done
fi
cat > $DEST_CLUSTER/recovery.conf $lt;$lt;REOF
standby_mode = 'on'
primary_conninfo = 'port=$PORT user=$PGSUPERUSER'
recovery_target_timeline='latest'
restore_command = 'cp $DATADIR_BASE/archivedir/%f "%p" 2> /dev/null'
REOF
if [ $pg_rewind_failed = "true" ];then
$psql -p $PORT -c "SELECT pg_stop_backup()" postgres
fi
if [ $pg_rewind_failed = "false" ];then
cp /tmp/postgresql.conf $DEST_CLUSTER/
fi架构基础
Pgpool-II 是位于客户端和 PostgreSQL 之间的代理服务器。Pgpool-II 理解 PostgreSQL 使用的称为 前端和后端协议(frontend and backend protocol) 的线路(wire)级协议。 有关该协议的更多详细信息,请参阅 PostgreSQL 手册。使用 Pgpool-II 不需要修改 PostgreSQL(更准确地说,您需要一些扩展才能使用 Pgpool-II 的全部功能)。因此 Pgpool-II 可以应对各种 PostgreSQL 版本。理论上,即使是最早的 PostgreSQL 版本也可以与 Pgpool-II 一起使用。对客户端也可以这样说。只要它遵循协议,Pgpool-II 就会愉快地接受来自它的连接,无论它使用什么样的语言或驱动程序。
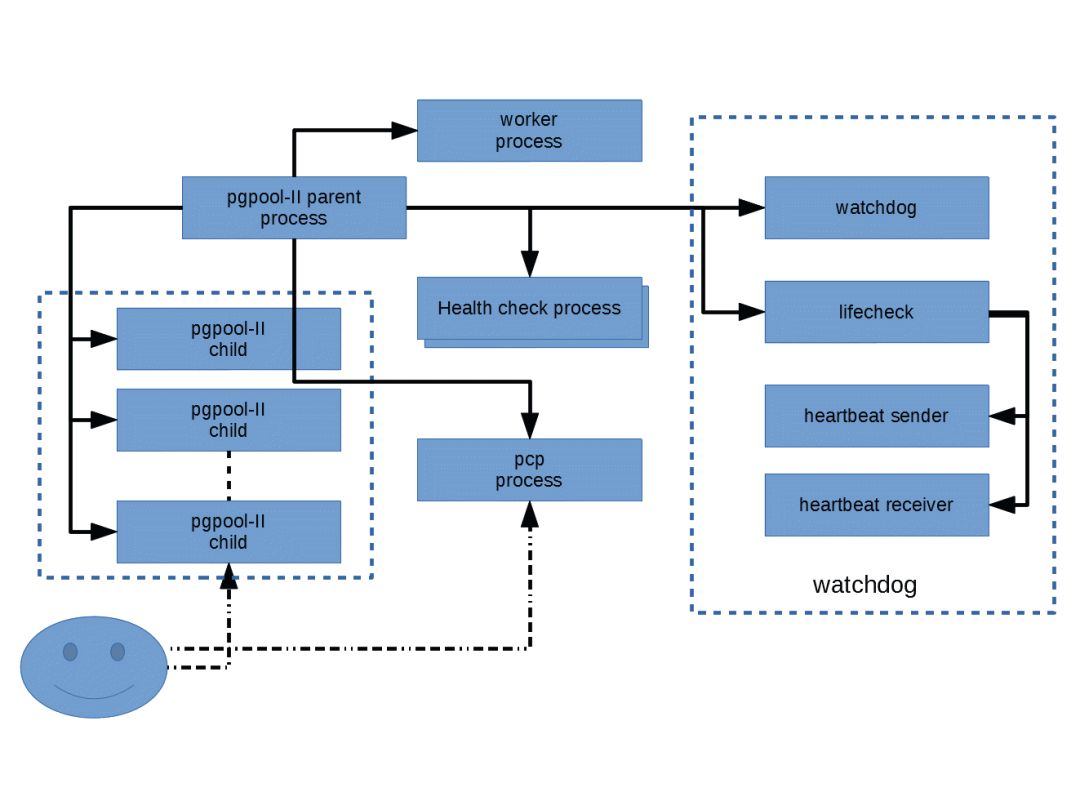
Pgpool-II 由多个进程组成。有一个主进程,它是所有其他进程的父进程。 它负责分叉子进程,每个子进程都接受来自客户端的连接。 还有一些从主进程派生的工作进程,负责检测流复制延迟。还有一个特殊的进程叫做 pcp 进程,专门用于管理 Pgpool-II 本身。Pgpool-II 有一个内置的高可用性功能,称为 watchdog。Watchdog 由一些进程组成。