当前位置:网站首页>Go编译原理系列10(逃逸分析)
Go编译原理系列10(逃逸分析)
2022-08-11 11:31:00 【书旅】
前言
在上一篇文章中分享了编译器的优化方法之一:函数内联,本文分享编译器的另一个优化方法:逃逸分析。逃逸分析是Go语言编译过程中比较重要的一个优化阶段,它主要用于标识变量应该被分配到栈上还是堆上
概述中的内容(包括示例),其实你可以在逃逸分析的源码注释中看到,逃逸分析源码位置:src/cmd/compile/internal/gc/escape.go(感觉是这几部分源码里边注释最全的一部分,哈哈哈)
逃逸分析概述
首先我们知道,在C/C++中,如果一个函数返回了一个栈上的对象指针,在函数执行完成,栈被销毁后,继续访问被销毁栈上的对象指针,就会出现问题
本部分介绍完Go语言编译过程的逃逸分析之后,你会发现逃逸分析阶段会识别出一个变量应该放在堆还是放在栈,对于放在堆中的变量,会借助Go运行时的垃圾回收机制自动的释放内存。当然,编译器会尽可能地将变量放置到栈中,因为栈中的对象随着函数调用结束会被自动销毁,减轻运行时分配和垃圾回收的负担
有了逃逸分析,其实作为Go开发者,我们在定义变量或对象时,都既可能被分配到栈中,也可能被分配到堆中。比如使用new或make创建的对象
在分配时,遵循以下两个原则:
指向栈上对象的指针不能被存储到堆中(因为栈上的内存会在使用完后被销毁) 指向栈上对象的指针不能超过该栈对象的生命周期(如果超过该栈对象的生命周期,它会被销毁)
下边是一个简单的逃逸的示例
package main
var a *int
func main() {
b := 1
a = &b
}
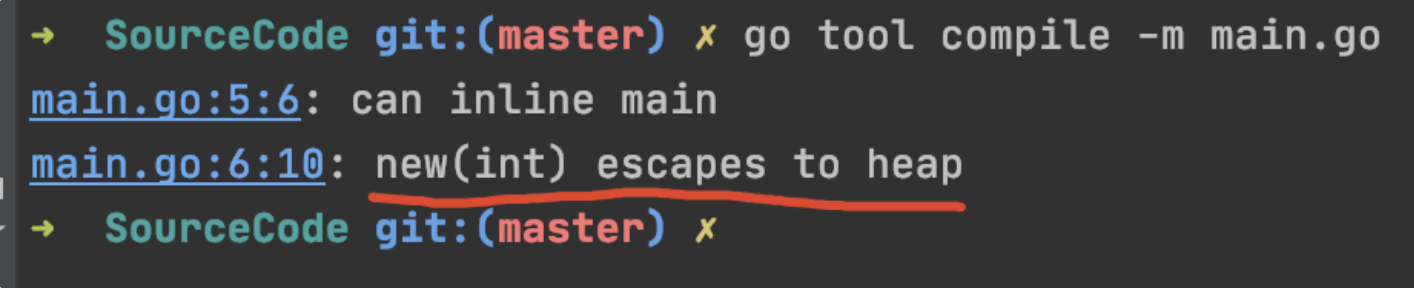
示例中,a是一个全局的整形指针变量,在main函数中,变量a引用了变量b的地址。根据上边我们提到的两个分配原则,如果b分配到栈中,就违背了第二个原则,变量a超过了变量b的声明周期,所以b需要被分配到堆中。你可以通过下边命令查看逃逸信息
go tool compile -m xxx.go

Go编译过程会构建带权重的有向图,权重表示当前变量引用和解引用的数量。如下例所示,p引用q时的权重,当权重大于0时,代表存在*解引用操作。当权重为-1时,代表存在&引用操作
p = &q // -1
p = q //0
p = *q // 1
p = **q // 2
p = **&**&q //2
并不是权重为-1就一定要逃逸,比如在下边这个示例中,虽然a引用了变量b的地址,但是由于变量a并没有超过变量b的声明周期,因此变量b与变量a都不需要逃逸
func test() int {
b := 666
a := &b
return *a
}
下边通过一个示例来展示解编译器带权重的有向图
package main
var o *int
func main() {
l := new(int)
*l = 42
m := &l
n := &m
o = **n
}
最终编译器在逃逸分析中的数据流分析,会被解析成下图所示的带权重的有向图
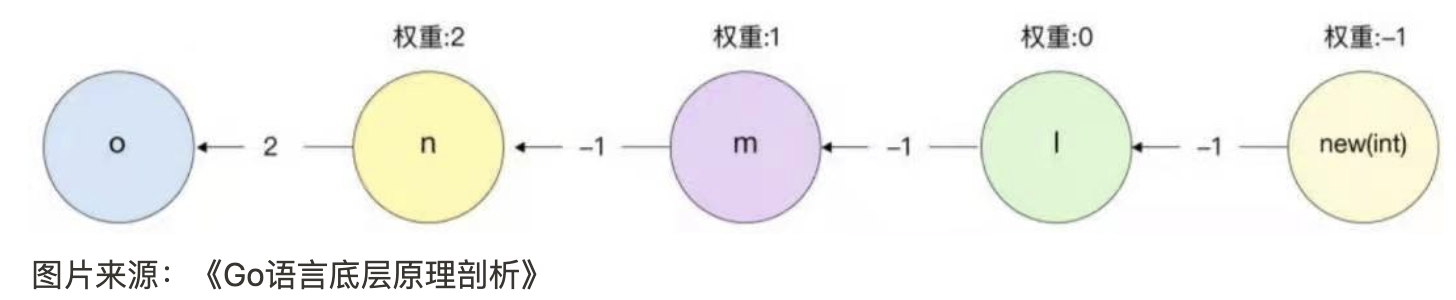
其中,节点代表变量,边代表变量之间的赋值,箭头代表赋值的方向,边上的数字代表当前赋值的引用或解引用的个数。节点的权重=前一个节点的权重+箭头上的数字,例如节点m的权重为2-1=1,而节点l的权重为1-1=0
遍历和计算有向权重图的目的是找到权重为-1的节点,比如上图中的new(int)节点,它的节点变量地址会被传递到根节点o中,这时还需要考虑逃逸分析的分配原则,o节点为全局变量,不能被分配在栈中,因此,new(int)节点创建的变量会被分配到堆中
实际的场景中会更加复杂,因为一个节点可能拥有多条边(比如结构体),而节点之间可能出现环。Go语言采用Bellman Ford算法(解决单源最短路径的算法)遍历查找有向图中权重小于0的节点
逃逸分析的核心代码位于:src/cmd/compile/internal/gc/escape.go。下边就简单看看一下逃逸分析的源码
逃逸分析底层实现
同样是顺着Go编译的入口文件往下看,你会看到下边这行代码
// Phase 6: Escape analysis.
timings.Start("fe", "escapes")
escapes(xtop)
调用了escapes方法,进行逃逸分析,下边看escapes方法的具体实现
func escapes(all []*Node) {
visitBottomUp(all, escapeFuncs)
}
发现它里边只调用可一个方法visitBottomUp,是不是很眼熟。没错,上一篇分享函数内联的时候,也是调用了这个方法。它的作用是通过深度优先搜索遍历抽象语法树,对每个结点进行验证,比如是不是闭包等。然后就是对满足条件的抽象语法树,执行传入的方法,对于逃逸分析,其实就是检查完之后去执行visitBottomUp的第二个参数中传递的函数escapeFuncs
下边就主要看escapeFuncs的内部实现
func escapeFuncs(fns []*Node, recursive bool) {
for _, fn := range fns {
if fn.Op != ODCLFUNC {
Fatalf("unexpected node: %v", fn)
}
}
var e Escape
e.heapLoc.escapes = true
for _, fn := range fns {
e.initFunc(fn)
}
for _, fn := range fns {
e.walkFunc(fn)
}
e.curfn = nil
e.walkAll()
e.finish(fns)
}
代码很少,主要是调用了initFunc、walkFunc、walkAll、finish这几个方法,我这里大致介绍它里边都做了什么,具体的实现细节,你可以自行的去看源码
initFunc:其实就是从语法树构造数据流图,前边提到的带权有向图walkFunc:遍历AST,判断相应节点是不是*OGOTO或OLABEL,然后将它们打上相应的标签(比如是OGOTO的话,就打上循环标签)*walkAll:它主要就是计算带权有向图中每个节点的最小解引用。它的实现就用到了上边提到的 Bellman Ford算法(关于这个算法我也不太懂,感兴趣的可以从维基百科上了解,具体点这里)finish:根据逃逸分析结果更新AST中对应节点的Esc字段等
边栏推荐
- centos linux 下安装mysql 8.0
- C# Call AutoNavi Map API to obtain latitude, longitude and positioning [Detailed 4D explanation with complete code]
- pgr_createTopology
- Bitmap这个“内存刺客”你也要小心
- LeetCode69:牛顿迭代法和二分法求解x的平方根
- 兴盛优选:时序数据如何高效处理?
- The fertile soil cloud innovation plan is coming
- EXCLUSIVE INTERVIEW | INTELLIGENCE IS SPONTANED, NOT PLANNED: Evolution Fan, Former OpenAI Research Manager and UBC Associate Professor Jeff Clune
- SD8016原厂单电池锂离子电池和锂聚合物电池充电IC
- vending machine
猜你喜欢



随机推荐
同城是美团电商的解法吗?
微信小游戏是个人尝试做游戏最好的选择
chrome is set to dark mode (including the entire webpage)
Web3 Entrepreneur's Guide: How to Build a Decentralized Community for Your Product?
C# Call AutoNavi Map API to obtain latitude, longitude and positioning [Detailed 4D explanation with complete code]
蚂蚁集团开源密码学基础库 BabaSSL 正式更名“铜锁”
【项目篇- 项目团队部分怎么写、如何作图?(两千字图文总结建议)】创新创业竞赛项目计划书、新苗国创(大创)申报书、挑战杯创业计划竞赛
【Opencv】-----倾斜图片转正
【2022】【Thesis Notes】Ultra-thin THz deflection based on laser direct writing graphene oxide paper——
SD8016原厂单电池锂离子电池和锂聚合物电池充电IC
兴盛优选:时序数据如何高效处理?
Spark Core
leetcode:373. 查找和最小的 K 对数字
闪灯IC,可按要求开发各种规格闪灯IC,单片机方案开发
【2022】【论文笔记】基于激光直写氧化石墨烯纸的超薄THz偏转——
Configuring vim(12) from scratch - theme configuration
openEuler小程序会议指南
C-V2X八大误区澄清和发展辩思
闪灯芯片银行塔闪灯IC参数应用
悠漓带你玩转C语言(详解操作符1)