当前位置:网站首页>Tdan over half
Tdan over half
2022-04-23 17:29:00 【Ton10】


This article It's video super score (VSR) in flow-free A masterpiece of , differ VESPCN Used in flow-based, That is, the optical flow estimation method is used to align adjacent frames , The author introduced TDAN Implicit motion compensation mechanism is adopted , The non reference frame is reconstructed by deformable convolution ( Support frame ) The estimate of , Finally, use and VESPCN A similar fusion mechanism realizes the current reference frame from L R → H R LR\to HR LR→HR The process of .
Note:
- TDAN This article The core of the article This paper mainly introduces a super segmentation method in video TDAN, It uses a new method based on DCN Of flow-free Alignment method , But no new integration is proposed fusion Method .
Reference documents :
①TDAN: Temporally Deformable Alignment Network for Video Super-Resolution Paper notes
② Video super score :TDAN(TDAN: Temporally Deformable Alignment Network for Video Super-Resolution)
③TDAN Official video
④TDAN Source code (PyTorch)
TDAN: Temporally Deformable Alignment Network for Video Super-Resolution
Write it at the front
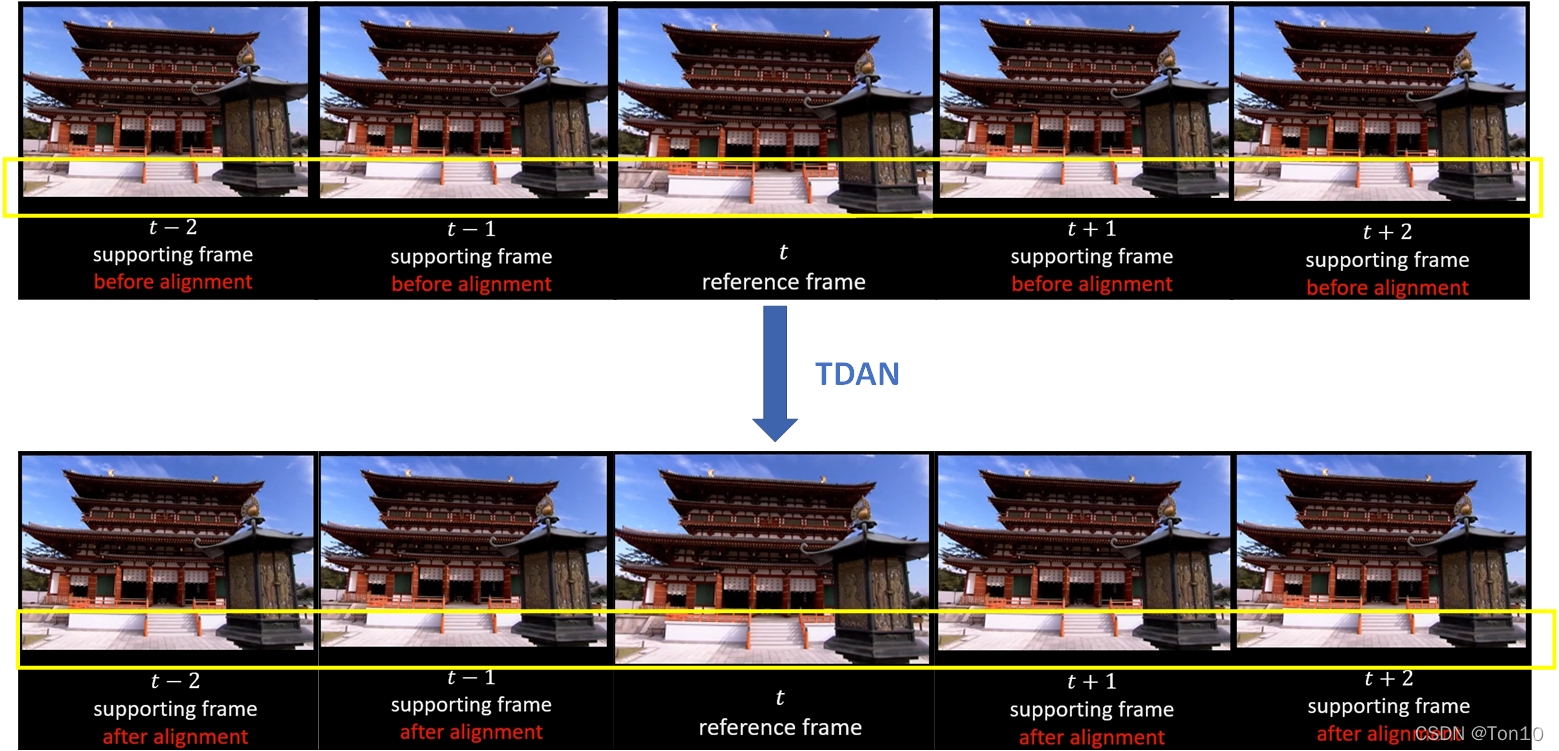
The two most important parts of video super score : image alignment Fusion with features . The basic framework of video super score is similar , Generally, several adjacent frames centered on the current frame are input into the alignment network , Then align and fuse , It's usually a SR The Internet ,SR The output of the network is the super division result of the current reference frame I S R I^{SR} ISR. In this paper ,TDAN The main purpose is to introduce a new image alignment method —— be based on DCN Alignment network , It can be seen as DCN A variation of .
Flow-based The defects of :
- Motion compensation based on optical flow is Two stages Of : motion estimation + Motion compensation . and TDAN Implicitly learn motion compensation , It's a one-stage .
- Flow-based Motion compensation It is highly dependent on the accuracy of motion estimation , Once the motion estimation is inaccurate, the motion compensation estimation will be inaccurate 、 Big deviation .
- Flow-based The method is
Image-wiseOf , Therefore, in Warp Stages can easily occur artifacts. and TDAN yesfeature-wiseOf , It is through learning in feature map The sampling offset on Warp. - Flowed-based stay Warp When , Just according to the point p p p( Usually sub-pixel coordinates ) Interpolate to get . and TDAN The sampling offset of is based on the point p p p Trained by the spatial relationship within the surrounding convolution range , so TDAN Better exploration ability .
Note:
- artifacts It refers to the unnatural... In the composite picture , At a glance, it can be seen that it has been processed manually , The specific performance is as follows :

Why align ?
The same features of the current frame and adjacent frames may appear in different pixel positions , If you can align first , Then fuse features , Finally, the super division can get a more accurate image . In super sub tasks , Alignment is through some spatial transformation operations , such as STN、DCN To make the reference frame and support frame as same as possible , say concretely :
- First, for the alignment itself ,alignment It can make frames more continuous , It can make the subsequent network better understand the motion relationship between frames . For adjacent frames with small motion change, it is used as SR When inputting ,SR The training of the network will predict... Towards fitting the characteristics of the input H R HR HR Images ; If the adjacent frames change too much , that SR The variability of network fitting to input features will increase , So the output H R HR HR The uncertainty of the image will increase , That is, training stability will be reduced , Over fitting phenomenon .
- Secondly, for subsequent integration , Different frames cannot differ too much , Otherwise, the performance of the network will be reduced . because alignment In order to Align the image content , Whether it's the same time frame or when several pictures are stacked , Let's use one 3 × 3 3\times 3 3×3 Deconvolution kernel extraction , We always want the same sampling location block ( 3 × 3 3\times 3 3×3) The content is relevant , For pictures, it is spatial correlation , And video is time related + Spatial correlation , Our neural network will use these correlations to improve the performance of tasks . If alignment is not used , Then you need a convolution kernel to sample , The contents of two pictures in the same position are generally irrelevant , For example, a piece is an edge information , The other is the background , Then such convolution cannot be used 2 The relevance of the picture ! Or you can think more abstractly : The two misaligned pictures are stacked together , It's equivalent to taking pictures and pasting , The content of the expression is naturally affected .
Abstract
Q 1 Q_1 Q1: Why use flow-free To align video frames ?
First , Because in the video , The object will move or the camera will move , Therefore, the reference frame and adjacent support frames cannot be aligned , so VSR The two most important parts of the are time alignment and feature fusion , In time alignment , Previous algorithms such as VESPCN Based on optical flow flow Method to align time ,VESPCN Use STN A variation of the , By means of Image-wise The motion estimation of the reference frame and the support frame is obtained , Then use motion estimation to warp Support frame for motion compensation , This approach is highly dependent on optical flow estimation ( motion estimation ) The accuracy of the , Incorrect estimation will affect the estimated value of supporting frames , And will lead to later SR Network reconstruction performance is inhibited .
secondly , To solve this problem , Adopted by the author flow-free The way to do it , Specifically, it is based on DCN This transformation method is used to align the reference frame and the support frame . because DCN be based on feature-wise Of , Therefore, there will be no... On the output image artifacts. We use adjacent frames of video as DCN To learn the changes between them, so as to output the support frame estimate close to the reference frame , Because the transformation involves not only spatial correlation , It also involves time , So this belongs to STN A variant of —— Time deformable convolution (TDCN).DCN By learning the offset of the sampling position, the features of the new position after offset are extracted to maintain spatial invariance , Therefore, it can avoid optical flow estimation ; and STN You must first learn the motion estimation between two frames , Then, the estimated value of the support frame is recovered by motion compensation , So optical flow estimation must exist .
Q 2 Q_2 Q2: How to use TDCN Do video alignment ?
Similar to VESPCN Use STN Variant to align ,TDAN Also use DCN variant TDCN To do video alignment : For the change of the support frame relative to the reference frame ,TDCN This change can be ignored to produce a feature extraction process similar to the reference frame , Then, it is recovered by deconvolution “ Reference frame ”, But actually this “ Reference frame ” Is the estimated value of the support frame , By optimizing alignment loss L a l i g n \mathcal{L}_{align} Lalign To make the estimated value of the supporting frame close to the reference frame , Thus, the alignment of reference frame and support frame is completed .
Note:
- STN Itself can be feature-wise, It can also be image-wise, Depending on warp The result is based on feature map Or images .VESPCN Use STN variant , It belongs to image-wise. and DCN and TDCN Use based on DCN Time aligned networks are feature-wise, because DCN Is to use the offset of sampling points to get a new sampling position , Then the convolution kernel is used to extract the output feature map The process of , After some training , Deformable convolution output feature map It can be compared with the convolution output before transformation feature map similar ( Note that this can only be approximate , You can never get as like as two peas. ).
- TDCN and DCN Is essentially the same , It's just TDCN Time information is introduced , The learning of forcing offset parameters needs to be based on adjacent video frames . But they all change the location of the sampling point , The convolution kernel has no deformation !
1 Introduction
Because in the video super score , There are changes between different frames , This comes from the movement of objects or the movement of cameras , So enter SR Before the Internet , Alignment must be done first . So the alignment module is VSR Problems that have to be solved , This paper introduces TDAN Is to specifically introduce a method based on DCN To reconstruct the estimated values of adjacent frames .Flow-based The method is in image-wise do , Because it relies too much on the accuracy of motion estimation, the rough optical flow estimation directly leads to various errors in the output estimated image artifacts. so TDAN Abandon optical flow , Use it directly feature-wise Of DCN To resist the change of adjacent frames and output the same image as the reference frame as much as possible .
TDCN(Temporal Deformable Convolution Networks) This way, Learn implicitly A motion estimation and deformation operation , In fact, the offset sampling point position is learned according to the reference frame and support frame , Let the convolution kernel extract the transformed feature map New position pixel value , Then output feature map Rebuilt . Besides ,TDCN Than TSTN Have a stronger ability to explore , because TSTN Of warp According to the sub-pixel position after deformation p p p Four surrounding pixels are obtained by interpolation , and TDCN Resampling point p p p It is the result of convolution of a region around the corresponding point on the support frame ( Depending on the size of the convolution kernel ), It considers a wider range of position transformation .
Experiments show that , In this way, it can be reduced artifacts The generation and fusion of the aligned reconstructed frame and the support frame are used for the following SR The reconstruction of the network improves the expressiveness , The specific visualization results are as follows :
To sum up TDAN The contribution of :
- Put forward one-stage Alignment method based on time deformable convolution , And previous optical flow based image-wise Different ,TDCN Belong to
feature-wise. - TDAN Alignment network use TDCN, Then I'll pick up SR The network thus forms the whole end-to-end video super division method .
- TDAN At the time of the VSR stay Vid4 We got it SOTA Expressive force .
2 Related Work
A little
3 Method
3.1 Overview

We use it I t L R ∈ R H × W × C I_t^{LR}\in\mathbb{R}^{H\times W\times C} ItLR∈RH×W×C Indicates the second... Of the video t t t frame , I t H R ∈ R s H × s W × C I_{t}^{HR}\in \mathbb{R}^{sH\times sW\times C} ItHR∈RsH×sW×C Indicates the second... Of the video t t t High resolution image corresponding to frame , namely Ground Truth, among s s s by SR Magnification , and I t H R ′ ∈ R s H × s W × C I_t^{HR'}\in\mathbb{R}^{sH\times sW\times C} ItHR′∈RsH×sW×C Indicates the result of our super score .
VSR The goal is to make the video continuous every time 2 N + 1 2N+1 2N+1 frame { I i L R } t − N t + N \{I_i^{LR}\}^{t+N}_{t-N} {
IiLR}t−Nt+N Input into the network , Super separation I t H R ′ I_t^{HR'} ItHR′.
Here 2 N + 1 2N+1 2N+1 In the frame , The first t t t frame I t L R I_t^{LR} ItLR Is the reference frame , rest 2 N 2N 2N frame { I t − N L R , ⋯ , I t − 1 L R , I t + 1 L R , ⋯ , I t + N L R } \{I_{t-N}^{LR},\cdots, I_{t-1}^{LR}, I_{t+1}^{LR},\cdots, I_{t+N}^{LR}\} {
It−NLR,⋯,It−1LR,It+1LR,⋯,It+NLR} To support frame .
TDAN The whole is divided into 2 Subnetworks :①TDAN Align the network ②SR Rebuilding the network . The former is to align objects or the content mismatch caused by camera motion , The latter will align the 2 N + 1 2N+1 2N+1 The process of frame fusion and then super Division .
①TDAN Align the network
Align the network every time you enter 2 frame , One of the frames is a fixed reference frame I t L R I_t^{LR} ItLR, Another frame is the support frame I i L R , i ∈ { t − N , ⋯ , t − 1 , t + 1 , ⋯ t + N } I_i^{LR},i\in\{t-N, \cdots, t-1,t+1, \cdots t+N\} IiLR,i∈{
t−N,⋯,t−1,t+1,⋯t+N}, set up f T D A N ( ⋅ ) f_{TDAN}(\cdot) fTDAN(⋅) Indicates the alignment operator , The alignment network expression is :
I i L R ′ = f T D A N ( I t L R , I i L R ) . (1) I_i^{LR'} = f_{TDAN}(I_t^{LR}, I_i^{LR}).\tag{1} IiLR′=fTDAN(ItLR,IiLR).(1) among I i L R ′ I_i^{LR'} IiLR′ To support frame I i L R I_i^{LR} IiLR The result after aligning with the reference frame , Or rather, I i L R I_i^{LR} IiLR The estimate of .
Note:
- Altogether 2 N + 1 2N+1 2N+1 frame , But each alignment uses only 2 Frame input .
②SR Rebuilding the network
When it's rebuilt, it's not just 2 Frames , But to Align the after 2 N 2N 2N A support frame and a reference frame are fused together Input in SR Network to reconstruct high-resolution images , The expression is as follows :
I t H R ′ = f S R ( I t − N L R ′ , ⋯ , I t − 1 L R ′ , I t L R , I t + 1 L R ′ , ⋯ I t + N L R ′ ) I_t^{HR'} = f_{SR}(I_{t-N}^{LR'},\cdots, I_{t-1}^{LR'}, {\color{deepskyblue}I_{t}^{LR}},I_{t+1}^{LR'},\cdots I_{t+N}^{LR'}) ItHR′=fSR(It−NLR′,⋯,It−1LR′,ItLR,It+1LR′,⋯It+NLR′)
Next, we will introduce these two sub networks in detail , among 3.2 Chaste Alignment is the focus of this article .
3.2 Temporally Deformable Alignment Network

TDAN Time deformable convolution (DCN variant ——TDCN) and DCN No difference in essence , It's just DCN Based on the introduction of time . In particular , differ DCN Single picture input ,TDCN Use adjacent frames 2 Input a picture , Through lightweight CNN Learn the offset parameter Θ \Theta Θ, Then the offset offset Add to input frame I i L R I_i^{LR} IiLR On , That is, it supports frame , By deformable convolution f d c ( ⋅ ) f_{dc}(\cdot) fdc(⋅) Output I i L R I_i^{LR} IiLR The estimate of I i L R ′ I_i^{LR'} IiLR′, Through optimization and I t L R I_t^{LR} ItLR Align at a distance of .
The picture above is TDAN Alignment network , from feature extraction 、TDCN And aligned frame reconstruction 3 A process consists of , Next, let's introduce it in blocks .
① feature extraction
Here we use a convolution layer to extract shallow features and EDSR Medium residual block similar k 1 k_1 k1 individual residual blocks To extract input adjacent frames I t L R 、 I i L R I_t^{LR}、I_i^{LR} ItLR、IiLR Deep features of , The final output feature map F t L R 、 F i L R F_t^{LR}、F_i^{LR} FtLR、FiLR After time deformable convolution feature-wise alignment .
② Time deformable convolution
Let's use the input first 2 Share feature map adopt concat(Early fusion) After that bottleneck layer To reduce the input feature map The number of channels , Finally, through a convolution layer, the number of channels is ∣ R ∣ |\mathcal{R}| ∣R∣, Height and width and input feature map Same offset parameters Θ \Theta Θ, The specific expression is as follows , among f θ ( ⋅ ) f_\theta(\cdot) fθ(⋅) Indicates the above process :
Θ = f θ ( F i L R , F t L R ) . (2) \Theta = f_\theta(F_i^{LR}, F_t^{LR}).\tag{2} Θ=fθ(FiLR,FtLR).(2)
Note:
- among ∣ R ∣ |\mathcal{R}| ∣R∣ Is the total number of parameters of convolution kernel , For example, for a 3 × 3 3\times 3 3×3 Convolution kernel , ∣ R ∣ = 9 |\mathcal{R}| = 9 ∣R∣=9.
- Θ = { Δ p n ∣ n = 1 , ⋯ , ∣ R ∣ } \Theta = \{\Delta p_n | n=1,\cdots, |\mathcal{R}|\} Θ={ Δpn∣n=1,⋯,∣R∣}.
- Offset stay DCN In the original paper 2 ∣ R ∣ 2|\mathcal{R}| 2∣R∣, Express 2 A direction x , y x,y x,y The migration ; stay TDCN In Chinese, it means ∣ R ∣ |\mathcal{R}| ∣R∣, The author is to directly learn a x 、 y x、y x、y The direction of synthesis .
With an offset offset After the matrix , We can implement deformable convolution , set up f d c ( ⋅ ) f_{dc}(\cdot) fdc(⋅) Is a deformable convolution operator , Our aim is to Δ p n \Delta p_n Δpn Apply to the same size The input of feature map F i L R F_i^{LR} FiLR On , Then use the convolution kernel R \mathcal{R} R To extract the sampling points after deformation , The specific expression is as follows :
F i L R ′ = f d c ( F i L R , Θ ) . (3) F_i^{LR'} = f_{dc}(F_i^{LR}, \Theta).\tag{3} FiLR′=fdc(FiLR,Θ).(3) among , F i L R ′ F_i^{LR'} FiLR′ Is the output of deformable convolution , Then we just need to rebuild it and we can recover I i L R I_i^{LR} IiLR The estimate of , It can work with I t L R I_t^{LR} ItLR alignment . Next, we will expand the deformable convolution , set up w ( p n ) w(p_n) w(pn) Is the convolution kernel position p n p_n pn The learnable parameters , p 0 p_0 p0 by F i L R ′ F_{i}^{LR'} FiLR′ Integer lattice position of , Then the process of deformable convolution can be expressed as :
F i L R ′ ( p 0 ) = ∑ p n ∈ R w ( p n ) F i L R ( p 0 + p n + Δ p n ⏟ p ) + b ( p n ) . (4) F_i^{LR'}(p_0) = \sum_{p_n\in\mathcal{R}} w(p_n)F_i^{LR}(\underbrace{p_0+p_n+\Delta p_n}_{p}) + b(p_n).\tag{4} FiLR′(p0)=pn∈R∑w(pn)FiLR(p
p0+pn+Δpn)+b(pn).(4)
because offset Generally not an integer , It's floating point numbers , therefore p p p Floating point numbers , and F i L R F_i^{LR} FiLR There is no pixel value corresponding to floating-point coordinates , Therefore, it needs to be done by interpolation , This sum DCN It's exactly the same . At present, all the changes involved are grid points , And the lattice is discrete , So in order to make the whole network trainable , The author uses bilinear interpolation to do , For details, please refer to my other article Paper notes DCN.
Note:
- Besides , Reference resources STN How to do it , The author will TDCN Conduct Series connection To enhance the flexibility and complexity of the model for transformation , The specific setting is 3 individual DCN. Specific relevant experiments can be seen in the experimental part 4.3 section .
- Reference frame F t L R F_t^{LR} FtLR It only involves calculation offset, Therefore, in actual programming , It can be used as a label to reduce the amount of calculation .
- TDCN stay feature-wise Do it implicitly STN The whole process of motion compensation in . Besides TDCN Each output point p 0 p_0 p0 The pixel values are based on the input feature map The convolution result within the operation range of a convolution kernel around , Not like STN Medium output feature map The pixel value of a point is only input from feature map Copy the new sampling location points ( Generally, an interpolation operation will be added ). So in contrast DCN Avoidable optical flow estimation , At the same time, it has strong exploration ability , That's decided TDAN It's a flow-free And in theory, it will be better than flow-based Better .
- and DCN equally ,TDCN in f θ ( ⋅ ) 、 f d c ( ⋅ ) f_\theta(\cdot)、f_{dc}(\cdot) fθ(⋅)、fdc(⋅) They train at the same time .
③ Aligned frame reconstruction
TDCN Belong to feature-wise Alignment on , That is, the above process is only aligned feature map F t L R F_t^{LR} FtLR and F i L R F_i^{LR} FiLR, But I didn't do I t L R I_t^{LR} ItLR and I i L R I^{LR}_i IiLR Alignment of . We usually use supervised learning to realize the above , In this way, it is necessary to supervise from the image level , So we need to use a deconvolution The process will feature map Rebuild into Image, The author uses a 3 × 3 3\times 3 3×3 The convolution layer of .
3.3 SR Reconstruction Network

This part is a SR The Internet , Enter after alignment 2 N + 1 2N+1 2N+1 Adjacent frames I t − N L R ′ , ⋯ , I t − 1 L R ′ , I t L R , I t + 1 L R ′ , ⋯ I t + N L R ′ I_{t-N}^{LR'},\cdots, I_{t-1}^{LR'}, {\color{deepskyblue}I_{t}^{LR}},I_{t+1}^{LR'},\cdots I_{t+N}^{LR'} It−NLR′,⋯,It−1LR′,ItLR,It+1LR′,⋯It+NLR′, The output is... After super division I t H R ′ I_t^{HR'} ItHR′.
Whole SR The network is divided into three parts :① Time series fusion network ② Nonlinear mapping layer ③ Reconstruction layer . Next, let's elaborate separately .
① Time series fusion network
The integration problem is VSR One of the two key problems , stay VESPCN in , The author introduces Early fusion、Slow fusion as well as 3D Convolution . And in this article , Integration is not the focus of the author's introduction , therefore TDCN As a framework, It's just Simple adoption Early fusion Conduct concat, Then use a 3 × 3 3\times 3 3×3 Convolution for shallow feature extraction .
② Nonlinear mapping layer
Adopt and EDSR Similar to k 2 k_2 k2 individual Residual block To stack , To extract deep features .
③ Reconstruction layer
The reconstruction layer uses ESPCN Proposed in Subpixel convolution layer To do the sampling , Then another convolution layer is connected to adjust , The final output I t H R ′ I_t^{HR'} ItHR′.
Note:
- About EDSR, Please refer to my other article Super cent EDSR.
- About VESPCN, Please refer to my other article Super cent VEPCN.
- About ESPCN, Please refer to my other article Super cent ESPCN.
3.4 Loss Function
TDAN There are two Loss form , Alignment network loss L a l i g n \mathcal{L}_{align} Lalign And hypernetwork losses L s r \mathcal{L}_{sr} Lsr.
For alignment modules , Our goal is to support the estimation of frames I i L R ′ I_{i}^{LR'} IiLR′ As close as possible to the reference frame I t L R I_{t}^{LR} ItLR, Thus, the contents of adjacent frames are aligned and the adjacent frames are more continuous , The specific loss expression is :
L a l i g n = 1 2 N ∑ i = t − N , ≠ t ∣ ∣ I i L R ′ − I t L R ∣ ∣ . (5) \mathcal{L}_{align} = \frac{1}{2N}\sum_{i=t-N,\ne t}||I_i^{LR'} - I_t^{LR}||.\tag{5} Lalign=2N1i=t−N,=t∑∣∣IiLR′−ItLR∣∣.(5)
Note:
- Alignment belongs to Self supervision Training for , Because it has no clear label information (Ground Truth), We actually use the reference frame as a pseudo tag .
SR Loss of network usage L 1 L_1 L1 Loss (1 Norm loss ):
L s r = ∣ ∣ I t H R ′ − I t H R ∣ ∣ 1 . (6) \mathcal{L}_{sr} = ||I_t^{HR'} - I_t^{HR}||_1.\tag{6} Lsr=∣∣ItHR′−ItHR∣∣1.(6)
Finally, the loss function we want to optimize is the sum of the above two , We will train aligned subnetworks and supramolecular networks together , So the whole TDAN The training of the model is end-to-end .
L = L a l i g n + L s r . (7) \mathcal{L} = \mathcal{L}_{align} + \mathcal{L}_{sr}.\tag{7} L=Lalign+Lsr.(7)
3.5 Analyses of the Proposed TDAN
- be based on Flow-based The alignment of belongs to two-stage Method , It is mainly divided into 2 Stages :① motion ( Optical flow ) It is estimated that ② Motion compensation . This way belongs to Image-wise, So it's easy to introduce artifacts, also flow-based It is highly dependent on the accuracy of motion estimation . and Flow-free alignment , For example, this paper proposes TDCN yes
one-stageMethod , It belongs to feature-wise Alignment on , because TDCN By learning the offset of sampling points to extract the features of the new position, it is equivalent to extracting the features of the reference frame ( This way of fighting transformation is different from STN Reverse sampling mechanism ), And the result of convolution is feature map, so This alignment is implicit . Besides , and TSTN Direct learning residuals in ( Optical flow ) Different ,TDCN The change in motion is feature map I got from studying in ( Position shift offset, But the change is not directly reflected in the image ), Then the image before the change is restored by reconstruction , Therefore, the capture of this optical flow is implicit . - Self monitoring training .TDCN Training belongs to self-monitoring training , Because we don't have I i L R ′ I_{i}^{LR'} IiLR′ Corresponding label , We just use the reference frame as the pseudo tag .
- The ability to explore .Flow-based Alignment method , such as TSTN It directly samples new position points on the input image obtained by motion estimation p p p The pixel value of is copied as the pixel value of the aligned image , Interpolation operations are generally added , It's just a change point 4 Just a pixel . and Flow-free alignment , such as TDCN Within the operation range of a convolution kernel around the sampling position point ( Use here “ Operation range ”, Because DCN Input in feature map The sampling position of will be deformed , So it can't be used “ Convolution kernel size range ”) Do convolution to correspond to the output feature map Upper point p 0 p_0 p0( p 0 p_0 p0 yes F i L R ′ F_i^{LR'} FiLR′ Integer lattice position ). therefore TDCN When determining the output pixels, we will explore a wider range , More adjacent pixels will be considered to determine the final output .
4 Experiments
4.1 Experimental Settings
① Data sets
- VSR and SISIR equally , Larger and higher resolution image frames contain more image details , about VSR The more the model's super division ability is improved , such as DIV2K Data set pair RCAN and EDSR The training effect is very good .
- Adopted by the author Vimeo Video hyperspectral data set as training set , This is one that includes 64612 The data set of 2 samples , Each sample contains continuous 7 The frame of 448 × 256 448\times 256 448×256 In the video . Therefore, it has no high-resolution training set , 448 × 256 448\times 256 448×256 Just from the original video resize Coming out ; Adopted by the author
Temple SequenceAs validation set ,Vid4As test set , These include {city,walk,calendar, foliage} Four scenarios .
② The evaluation index
and SISR equally ,VSR use PSNR and SSIM2 An objective image evaluation index .
③ Down sampling method
The author compared the results of this experiment 11 Other species SR Model , Among them is SISR Method , Also have VSR Of :VSRnet、ESPCN、VESPCN、Liu、TOFlow、DBPN、RND、RCAN、SPMC、FSRVSR、DUF.
The use of blue font Matlab Medium Bicubic Interpolation for down sampling , Write it down as B I BI BI; The red font uses Gaussian blur first and then select s s s A method of using pixels as down sampled images , Write it down as B D BD BD; and TDAN Use them separately BI and BD, Do it together 2 Next sampling .
Note:
- We use FRVSR-3-64 and DUF-16L Model , Because it's two and TDAN The model parameters are similar .
④ Training super parameter settings
- SR Zoom magnification r = 4 r=4 r=4.
- RGB Of patch Size fake 48 × 48 48\times 48 48×48.
- Batch=64.
- Each sample contains continuous 5 frame .
- Adam Optimize , The initial learning rate is 1 0 − 4 10^{-4} 10−4, every 100 individual epochs, Down by half .
4.2 Experimental Comparisons
① First of all BI Experimental comparison under down sampling configuration :

The experimental conclusion :
- TDAN stay Vid4 On the dataset SOTA The performance of the !
The visualization results are as follows :

The results are as follows :
- DPBN、RDN、RCAN these SISR The method is very simple for video processing , Is to do super points for each frame , Different frames are processed independently , That is, it only uses the reference frame, not the power of the supporting frame ( Time redundancy )! Therefore, its expressiveness will be lower than VSR Method .
- two-stage Video hyperspectral method , Such as VESPCN Your performance will be lower than one-stage Method TDAN The performance of the , Illustrates the one-stage Advantages of alignment method and TDAN Explore more powerful features .
② The second is BD Experimental results under configuration
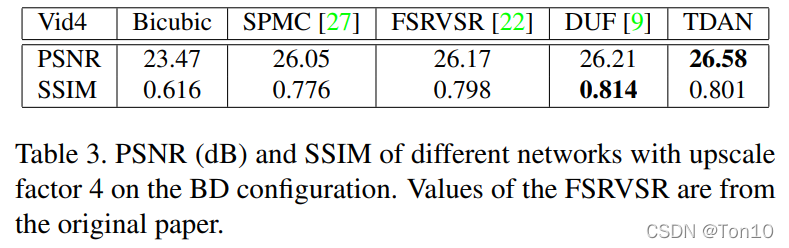
The results are as follows :
- stay PSNR On ,TDAN The optimal , But in SSIM On ,DUF Perform better .
The visualization results are as follows :

The results are as follows :
- obviously TDAN Better in detail recovery , Like a child's face , Illustrates the TDAN Better at using the information supporting frames for alignment , So as to bring better help to reconstruction .
③ Comparison of model size

The results are as follows :
- TDAN Use more Lightweight network To achieve better video super score effect , This further proves one-stage Validity of alignment !
- DUF Than TDAN Lighter weight , But not as expressive as TDAN Good to come . It's important to note that here TDAN According to the 1.97M The parameter quantity of is connected in series in the alignment network 4 A time deformable convolution .
4.3 Ablation Study
In order to further explore TDAN Performance of , The author compared TDAN stay SISR、MFSR、D2、D3、D4、D5 Performance comparison on , among SISR Express TDAN Use only reference frame input instead of support frame and alignment network ;MFSR Said the use of Early fusion Instead of using aligned networks , It and SISR All use 3.3 Section of the super sub reconstruction network ; { 2 D 、 3 D 、 4 D 、 5 D } \{2D、3D、4D、5D\} { 2D、3D、4D、5D} Respectively represent several time deformable convolution networks connected in series in the alignment network .
The experimental results are as follows :
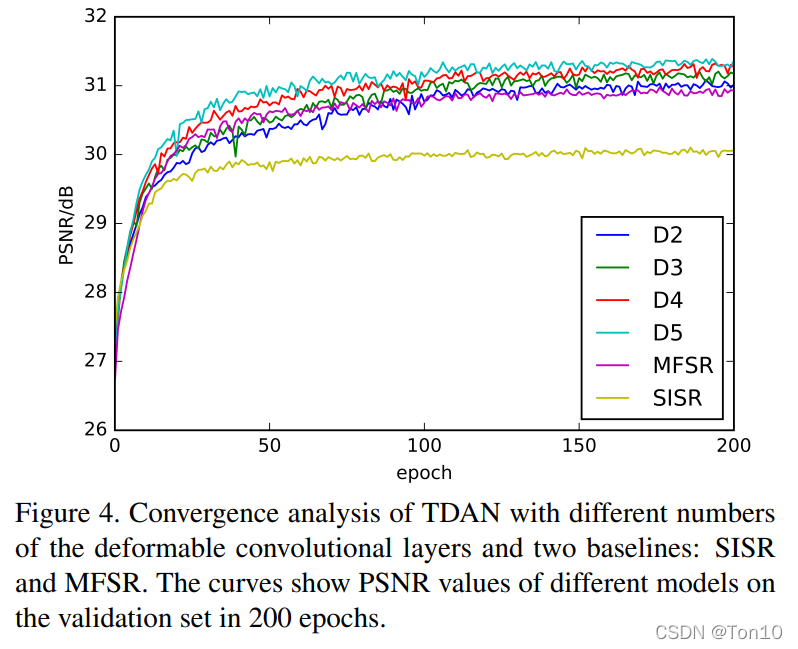
The results are as follows :
- MFSR Than SISR good , It shows that the support frame is right in time redundancy SR Effectiveness of reconstruction , Contribute to the improvement of expressiveness .
- The final performance of the model using aligned network is better than MFSR, The contribution of alignment to video frame continuity and the alignment of content are helpful to SR Network reconstruction and improvement of expressiveness .
- For the comparison of the number of deformable convolutions in series time , D 5 D5 D5 The advantage is greater , It shows that within a certain range , The more TDCN Produce more accurate alignment , Improve your expressiveness .
4.4 Real-World Examples
To further demonstrate TDAN The ability of , The author set up the video super score comparison of the real scene , The data set is 2 Video sequence :bldg and CV book, The experimental results are as follows :

The experimental conclusion :
- Obviously, in the real scene ,TDAN The performance is also better .
5 Limitation and Failure Exploration
Next is the author's comment on TDAN Description of limitations and future prospects , As follows :
① Data sets
The previous experimental training set is only a small low resolution set 448 × 256 448\times 256 448×256, So we can't train a deeper network and get better reconstruction quality , For example, the experimental results in the figure below :

TDAN Is not as expressive as deep networks RCAN stay DIV2K(1000 Zhang 2K Resolution data set ) Reconstruction effect on , This shows that in a larger and better quality data set , No need to support frames , Better performance can be achieved by using reference frames alone SR effect , Proved a larger and higher definition ( such as 2k、4k) How important is your dataset , Better data sets also allow us to train deeper TDAN.
② Fusion mode
stay TDAN in , Our point is to align , Therefore, only the simple Early fusion To do fusion , But it's like VESPCN In the same , We can do it in TDAN Expand better fusion methods on .
③ Alignment loss L a l i g n \mathcal{L}_{align} Lalign
The author points out that a more reasonable and complex alignment loss function can be designed . In addition, we use a self-monitoring method for the training of aligned networks , This means that false tags —— Supporting frames does not represent the real label of aligned frames , such Ground Truth It's noisy , So the author points out that this article Learning with Noisy Labels To further improve the noise labeling problem .
6 Conclusion
- This paper puts forward a kind of
one-stageAlignment VSR Model ——TDAN, Which aligns the network TDCN yesflow-freeMethod , Its Implicitly in feature-wise Capture motion information on , And directly convolute the changed sampling points to output feature map, thus Implicit implementation feature-wise Alignment on . - TDCN Compare with flow-based Alignment method , It has a stronger The ability to explore .
版权声明
本文为[Ton10]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231724046830.html
边栏推荐
- Oninput one function to control multiple oninputs (take the contents of this input box as parameters) [very practical, very practical]
- Promise (IV)
- [WPF binding 3] listview basic binding and data template binding
- Shell-入门、变量、以及基本的语法
- freeCodeCamp----shape_ Calculator exercise
- C# Task. Delay and thread The difference between sleep
- node中,如何手动实现触发垃圾回收机制
- How does matlab draw the curve of known formula and how does excel draw the function curve image?
- Go language, array, string, slice
- freeCodeCamp----prob_ Calculator exercise
猜你喜欢
STM32 entry development board choose wildfire or punctual atom?
Shell script -- shell programming specification and variables
【WPF绑定3】 ListView基础绑定和数据模板绑定

Use between nodejs modules
flink 学习(十二)Allowed Lateness和 Side Output
![[difference between Oracle and MySQL]](/img/90/6d030a35692fa27f1a7c63985af06f.png)
[difference between Oracle and MySQL]
线性代数感悟之1
. net cross platform principle (Part I)

Further study of data visualization
[WPF binding 3] listview basic binding and data template binding
随机推荐
HCIP第五次实验
Simulation of infrared wireless communication based on 51 single chip microcomputer
Self use learning notes - connectingstring configuration
In ancient Egypt and Greece, what base system was used in mathematics
Come out after a thousand calls
[batch change MySQL table and corresponding codes of fields in the table]
The system cannot be started after AHCI is enabled
Input file upload
Understanding of RPC core concepts
[registration] tf54: engineer growth map and excellent R & D organization building
Entity Framework core captures database changes
01-初识sketch-sketch优势
Use of shell cut command
Manually implement call, apply and bind functions
stm32入门开发板选野火还是正点原子呢?
C listens for WMI events
开期货,开户云安全还是相信期货公司的软件?
【WPF绑定3】 ListView基础绑定和数据模板绑定
ClickHouse-数据类型
How does matlab draw the curve of known formula and how does excel draw the function curve image?