当前位置:网站首页>Detectron2 using custom datasets
Detectron2 using custom datasets
2022-04-23 21:01:00 【Top of the program】
This document explains the data set API(DatasetCatalog、MetadataCatalog) How to work , And how to use them to add custom datasets .
If you want to use a custom dataset , Reuse at the same time detectron2 Data loader (data loaders), You need :
- Register your dataset ( namely , tell detectron2 How to get your dataset ).
- ( Optional ) Register metadata for your dataset .
In order to make detectron2 Know how to get a file named “my_dataset” Data set of , The user needs to implement a function , This function is used to return the dictionary list of the dataset mentioned below , Then tell detectron2 This function :
def my_dataset_function():
...
return list[dict] in the following format
from detectron2.data import DatasetCatalog
DatasetCatalog.register("my_dataset", my_dataset_function)
# later, to access the data:
data: List[Dict] = DatasetCatalog.get("my_dataset")
ad locum , The code snippet will be named “my_dataset” The data set of is associated with the function that returns the data . If you call more than once , The function must return the same data ( In the same order ). Registration is always valid , Until the process exits .
This function can do anything , And should return list[dict] Data in , Every dict All in one of the following formats :
- Detectron2 Standard dataset Dictionary , As follows . This will make it similar to detectron2 Many of the other built-in features in , Therefore, it is recommended to use it when sufficient .
- Any custom format . You can also return any... In your own format dicts, For example, add additional keys for new tasks . then , You also need to handle them correctly downstream . See more details below .
Standard dataset dictionary
For standard tasks ( Instance detection 、 example / semantics / Panoramic segmentation 、 Key point detection ), We load the original dataset into the dictionary list ( list[dict]) in , Its specification is similar to COCO The annotation .
Every dict Contains information about an image . dict May have the following fields , The required fields vary depending on the needs of the data loader or task ( See below )
| Task | Fields |
|---|---|
| Common | file_name, height, width, image_id |
| Instance detection/segmentation | annotations |
| Semantic segmentation | sem_seg_file_name |
| Panoptic segmentation | pan_seg_file_name, segments_info |
- file_name: The full path of the image file .
- height, width: Integers , The shape of the image .
- image_id(str or int): A unique... That identifies this image id.
- annotations (list[dict]): Instance detection / Required for segmentation or key detection tasks . Every dict The corresponding annotation of an instance in this image , And may include the following keys:
1. bbox (list[float], required): Represents the instance bounding box 4 A list of numbers .
2. bbox_mode (int, required): bbox The format of . It has to be structures.BoxMode Members of . At present, we support :BoxMode.XYXY_ABS、BoxMode.XYWH_ABS.
3. category_id (int, required):[0, num_categories-1] Range of integers , Indicates a category label . If applicable , Reserved values num_categories To indicate that “ background ” Category .
4. segmentation (list[list[float]] or dict): Split mask of the instance .
a. If it is list[list[float]], It represents a list of polygons , One for each connected component of the object . Every list[float] Is a simple polygon , The format is [x1, y1, ..., xn, yn] (n≥3). Xs and Ys Is the absolute coordinate in pixels .
b. If it is dict, said COCO Compress RLE Per pixel segmentation mask in format . dict There should be a key “size” and “counts”. You can pycocotools.mask.encode(np.asarray(mask, order="F")) take 0s and 1s Of uint8 The segmentation mask is converted to such dict. If you use the default data loader in this format ,cfg.INPUT.MASK_FORMAT Must be set to bitmask .
5. keypoints (list[float]): The format is [x1, y1, v1,..., xn, yn, vn]. v[i] Indicates the visibility of the key . n Must be equal to the number of key categories . Xs and Ys yes [0, W or H] Absolute real value coordinates within the range .
( Be careful ,COCO The key coordinates of the format are [0, W-1 or H-1] Range of integers , This is different from our standard format .Detectron2 take COCO Key coordinates plus 0.5 To convert them from discrete pixel indexes to floating point coordinates .)
6. iscrowd:0( Default ) or 1. Whether this instance is marked as COCO Of “ Crowd area ”. If you don't know what it means , Please do not include this field .
If annotations It's an empty list , It means that the image is marked as having no object . By default , Such images will be deleted from the training , But you can use DATALOADER.FILTER_EMPTY_ANNOTATIONS Included .
- sem_seg_file_name (str): Semantic segmentation ground truth The full path to the file . It should be a grayscale image , Its pixel value is an integer label .
- pan_seg_file_name (str): Panoramic segmentation ground truth The full path to the file . It should be a RGB Images , Its pixel value is using panopticapi.utils.id2rgb Function encoded integer id. id from segments_info Definition . If id
Not in segments_info in , Then the pixel is considered unmarked , And often overlooked in training and evaluation . - Segments_info(list[dict]): Define panoramic segmentation ground truth Each of them id The meaning of . Every dict All have the following keys :
1. id (int): Appear in the ground truth Integer in image .
2. category_id(int):[0, num_categories-1] Range of integers , Indicates a category label .
3. iscrowd:0( Default ) or 1. Whether this instance is marked as COCO Of “ Crowd area ”.
版权声明
本文为[Top of the program]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/111/202204210545090239.html
边栏推荐
猜你喜欢

opencv应用——以图拼图

MySQL进阶之表的增删改查
Opencv application -- jigsaw puzzle
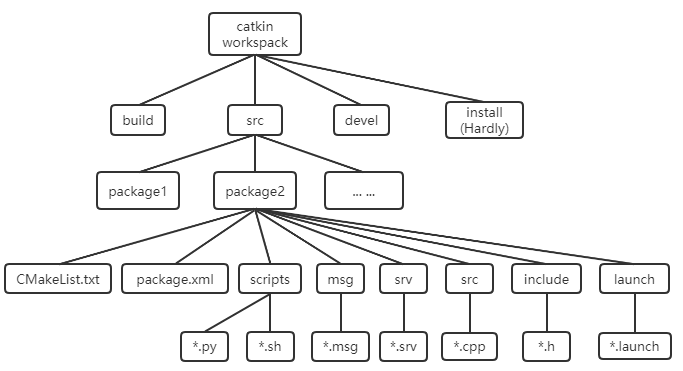
ROS学习笔记-----ROS的使用教程
Chrome 94 引入具有争议的 Idle Detection API,苹果和Mozilla反对
Addition, deletion, modification and query of MySQL advanced table
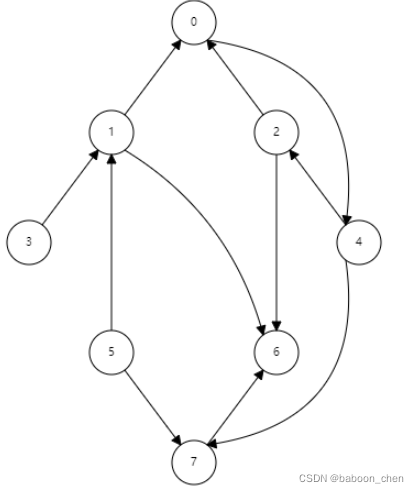
Graph traversal - BFS, DFS

Summary and effect analysis of methods for calculating binocular parallax
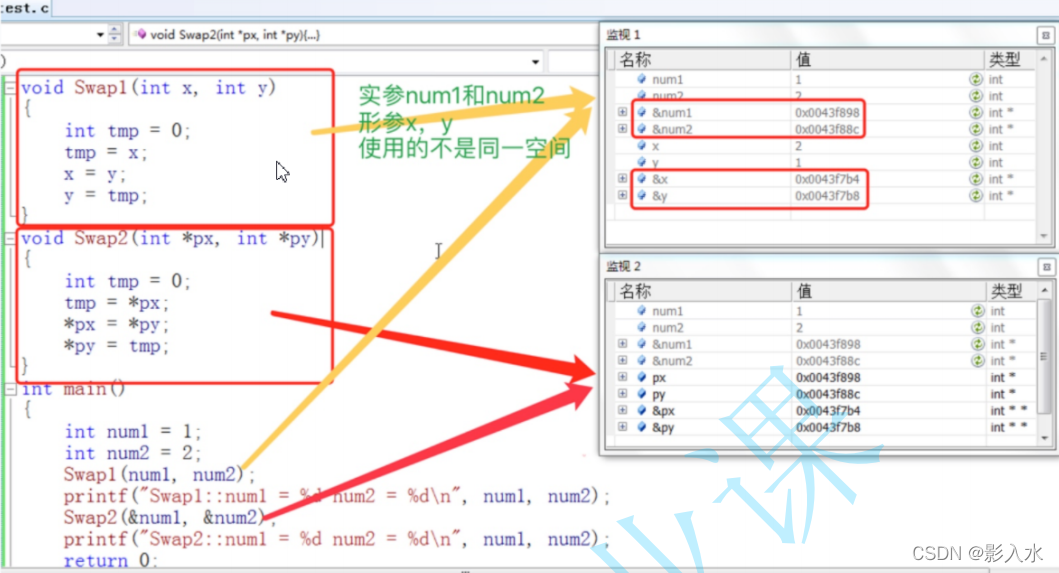
Deep analysis of C language function
Linux中,MySQL的常用命令
随机推荐
中创存储|想要一个好用的分布式存储云盘,到底该怎么选
笔记本电脑卡顿怎么办?教你一键重装系统让电脑“复活”
Awk example skills
Realrange, reduce, repeat and einops in einops package layers. Rearrange and reduce in torch. Processing methods of high-dimensional data
Minecraft 1.12.2 module development (43) custom shield
go interface
go map
2.整理华子面经--2
Arm architecture assembly instructions, registers and some problems
Gsi-ecm digital platform for engineering construction management
Fastdfs思维导图
go array
South Korea may ban apple and Google from offering commission to developers, the first in the world
Express③(使用Express编写接口、跨域有关问题)
CUDA, NVIDIA driver, cudnn download address and version correspondence
ros功能包内自定义消息引用失败
Chrome 94 引入具有争议的 Idle Detection API,苹果和Mozilla反对
Solve importerror: cannot import name 'imread' from 'SciPy misc‘
laravel 发送邮件