当前位置:网站首页>redis优化系列(三)解决主从配置后的常见问题
redis优化系列(三)解决主从配置后的常见问题
2022-04-23 19:04:00 【InfoQ】
读写分离概述:
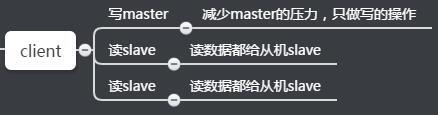
1、复制数据延迟
#使用redis镜像创建一台新的redis从节点服务器``docker run --privileged -itd --name redis-slave2 --net mynetwork -p 6390:6379 --ip 172.10.0.4 redis
#安装linux下的控流工具,使用他来模拟网络延迟``yum ``install` `iproute
#进入redis-slave2容器里面``docker ``exec` `-itd redis-slave2 ``bash` `#配置这台服务器的网络延迟5秒钟``tc qdisc add dev eth0 root netem delay 5000ms` `#然后你可以使用swoole的定时器来检测查看结果` `#删除延迟网络服务器的命令如下:``tc qdisc del dev eth0 root netem delay 5000ms
2、从节点故障问题
3、配置不一致
4、避免全量复制
5、复制风暴
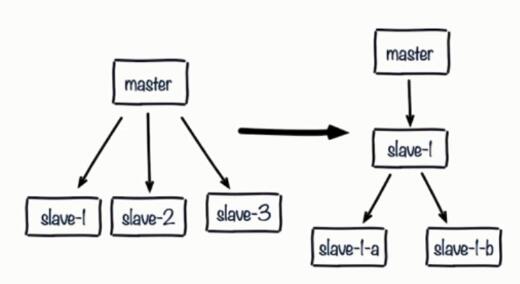
6、单机器的复制风暴

版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://xie.infoq.cn/article/549aa4bba0b6d8d806cc665a2
边栏推荐
- How can programmers quickly develop high-quality code?
- 【历史上的今天】4 月 23 日:YouTube 上传第一个视频;网易云音乐正式上线;数字音频播放器的发明者出生
- Sentinel service fusing practice (sentinel integration ribbon + openfeign + fallback)
- mysql_linux版本的下載及安裝詳解
- Machine learning theory (8): model integration ensemble learning
- Simple use of navigation in jetpack
- How about CICC wealth? Is it safe to open an account up there
- JVM的类加载过程
- Minesweeping II of souI instance
- K210 serial communication
猜你喜欢
剑指 Offer II 116. 省份数量-空间复杂度O(n),时间复杂度O(n)
Introduction to micro build low code zero Foundation (lesson 3)
Introduction to ROS learning notes (II)
Esp32 (UART receiving and sending) - receiving and sending communication of serial port (4)

Client interns of a large factory share their experience face to face
Esp32 (UART ecoh) - serial port echo worm learning (2)

Introduction to ROS learning notes (I)
ESP32 LVGL8. 1 - slider slider (slider 22)
PyGame tank battle
七、DOM(下) - 章节课后练习题及答案
随机推荐
WebView saves the last browsing location
RPM包管理
MySQL Téléchargement et installation de la version Linux
C: generic reflection
程序员如何快速开发高质量的代码?
8266 obtain 18b20 temperature
深入理解 Golang 中的 new 和 make 是什么, 差异在哪?
Raspberry pie 18b20 temperature
Machine learning theory (7): kernel function kernels -- a way to help SVM realize nonlinear decision boundary
Eight bit binary multiplier VHDL
MySQL statement
Simplified path (force buckle 71)
STM32: LCD display
Nacos as service registry
Machine learning practice - naive Bayes
MySQL学习第五弹——事务及其操作特性详解
Usage of functions decode() and replace() in SQL
简化路径(力扣71)
Seata handles distributed transactions
ESP32 LVGL8. 1. Detailed migration tutorial of m5stack + lvgl + IDF (27)