当前位置:网站首页>Thesis unscramble TransFG: A Transformer Architecture for Fine - grained Recognition
Thesis unscramble TransFG: A Transformer Architecture for Fine - grained Recognition
2022-08-11 06:32:00 【pontoon】
This article is the application of transformers in fine-grained fields.
Problem: Transformer has not been used in the field of image segmentation
Contribution points: 1. The input of the vision transformer divides the image into patches, but there is no overlap. The article is changed to split patches and use overlap (this can only be counted as a trick)
2.Part Selection Module
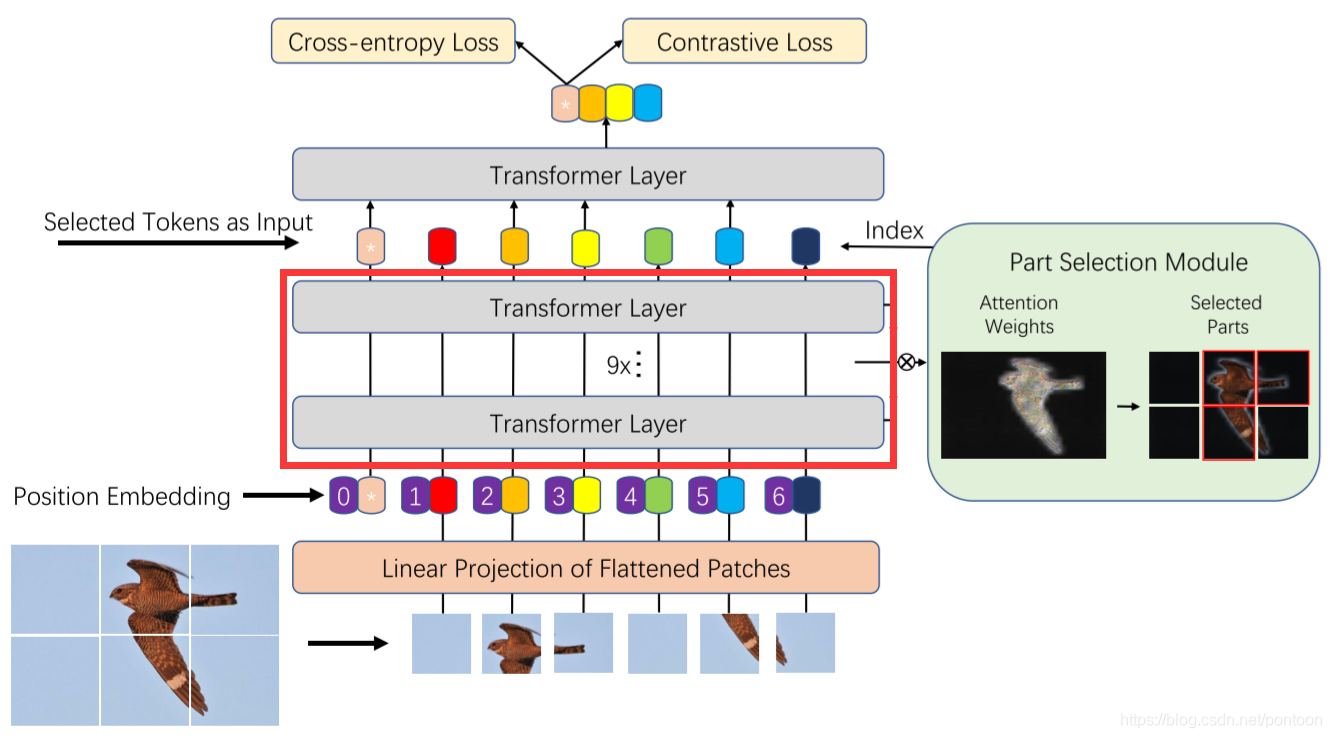
In layman's terms, the input of the last layer is different from the vision transformer, that is, the weights of all layers before the last layer (shown in the red box) are multiplied, and then the tokens with great weight are filtered and spliced together as the L-th layer.enter.
First of all, the output of the L-1 layer is originally like this:
![]()
The weight of a previous layer is as follows:
![]()
The value range of the subscript l is (1,2,...,L-1)
Assuming there are K self-attention heads, the weight in each head is:
![]()
The value range of the superscript i is (0,1,...,K)
The weights are multiplied to all layers before the last layer:
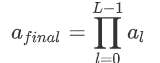
Then select the A_k tokens with the largest weight as the input of the last layer.
So after processing, its input can be expressed as:
![]()
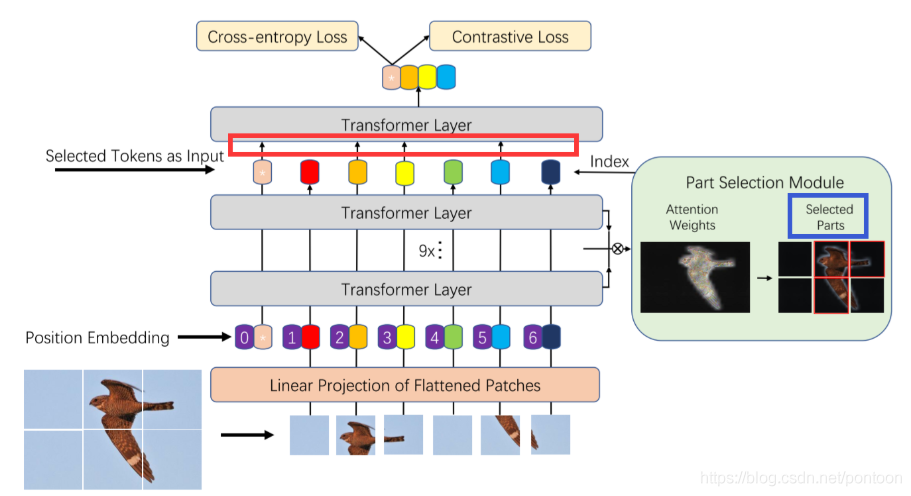
From the perspective of the model architecture, it can be found that the token with the arrow in the red box is selected, and it is also the token with a large weight after the weight is multiplied. The blue box on the right represents the patch corresponding to the selected token.
3.Contrastive loss
The author said that the features between different categories in the fine-grained field are very similar, so it is not enough to use the cross-entropy loss to learn the features. After the cross-entropy loss, a new Contrastive loss is added, which introduces the cosine similarity.(Used to estimate the similarity of two vectors), the more similar the vectors, the greater the cosine similarity.
The purpose of the author's proposal of this loss function is to reduce the similarity of "classification tokens" of different categories, and maximize the similarity of the same "classification tokens".The formula of Contrastive loss is as follows:
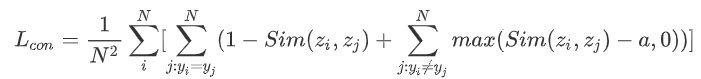
Where a is an artificially set constant.
So the overall function is:
![]()
Experiment:
Comparison with CNN and ViT on several datasets for sub-classification, SOTA
边栏推荐
猜你喜欢
Error: Flash Download failed - “Cortex-M4“-STM32F4
STM32F4-正点原子探索者-SYSTEM文件夹下的delay.c文件内延时函数详解
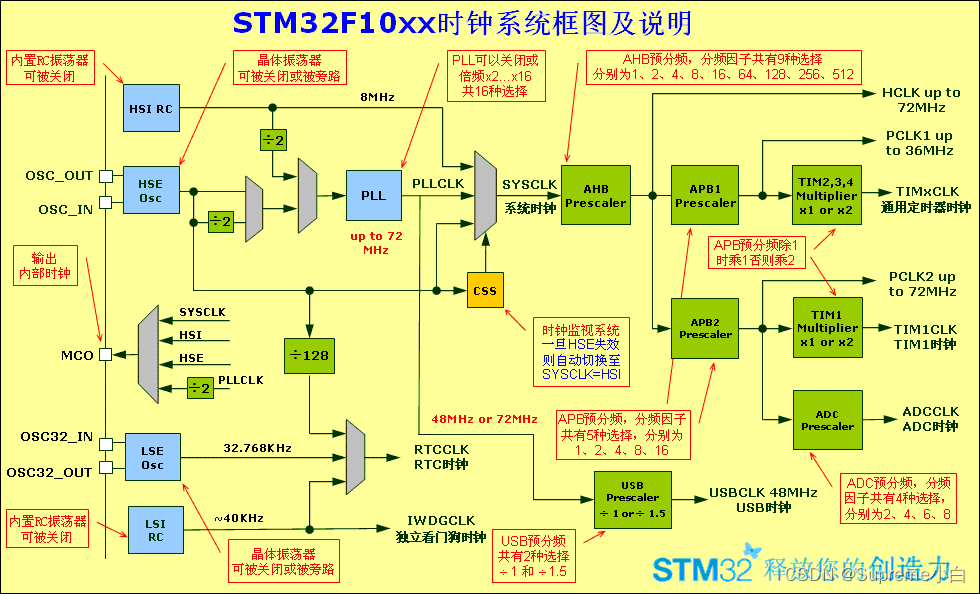
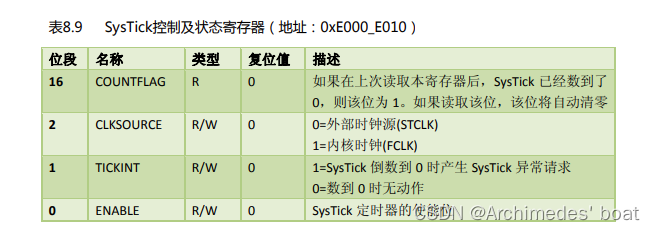
STM32学习总结(一)——时钟RCC
typescript学习日记,从基础到进阶(第二章)

Waymo dataset usage introduction (waymo-open-dataset)

Safety helmet recognition system

CKEditor富文本编辑器工具栏自定义笔记
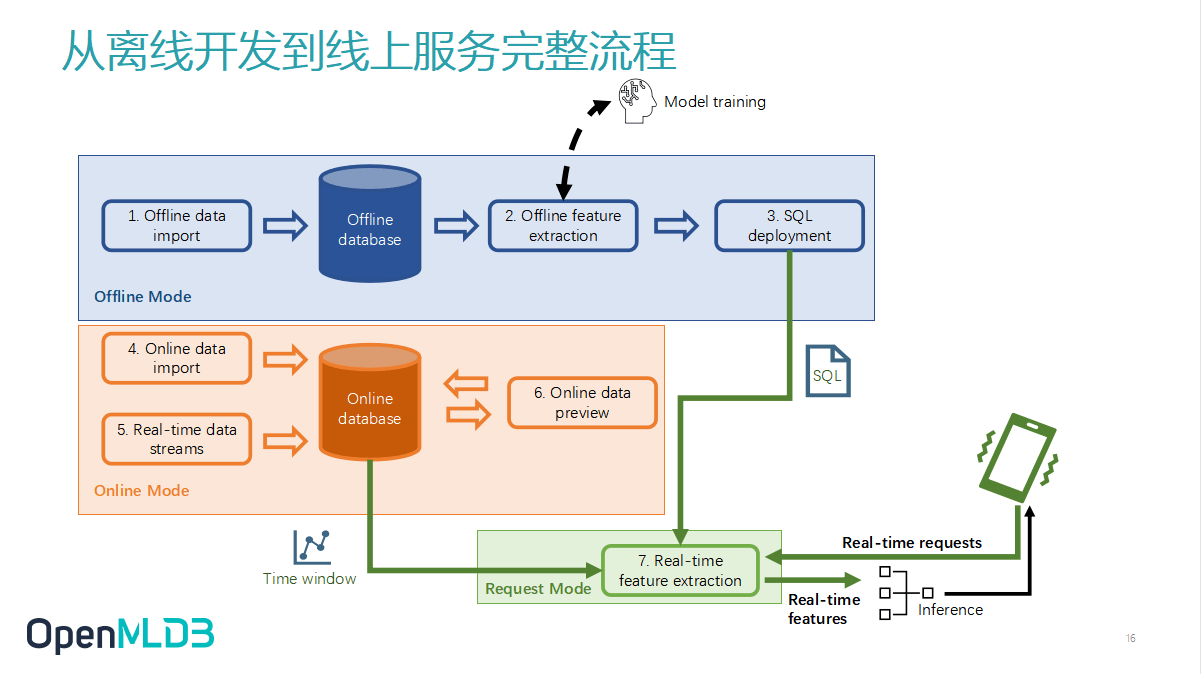
OpenMLDB:线上线下一致的生产级特征计算平台
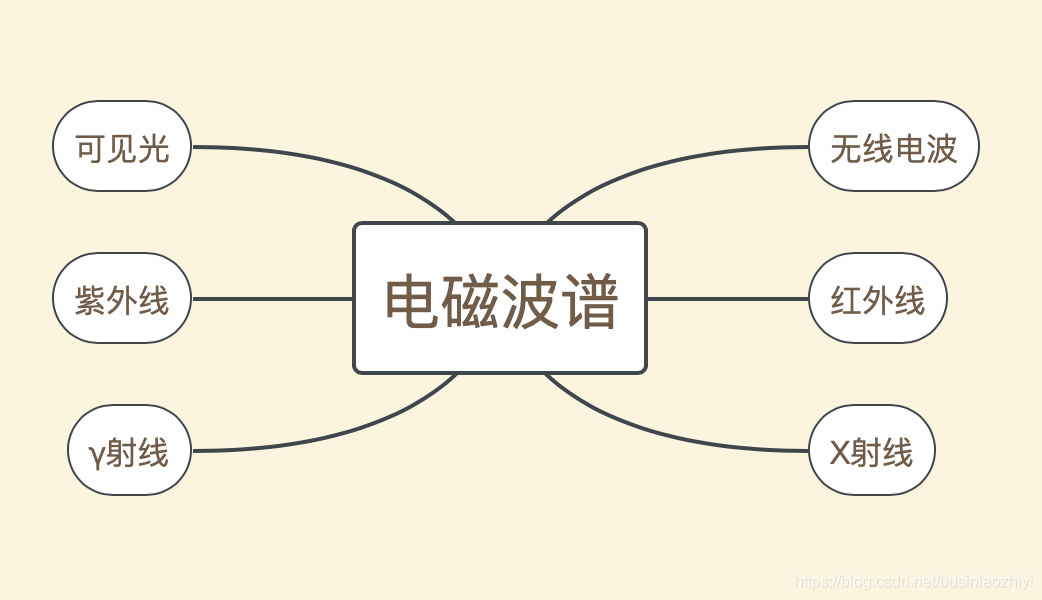
红外线一认识
第四范式OpenMLDB优化创新论文被国际数据库顶会VLDB录用
随机推荐
Diagnostic Log and Trace——DLT 离线日志存储
USB URB
贡献者任务第三期精彩来袭
目标检测思维导图
CMT2380F32模块开发8-Base Timer例程
Diagnostic Log and Trace——为应用程序和上下文设置日志级别的方法
USB 枚举过程中8 字节标准请求解析
Argparse模块 学习
张小龙的微信公开课(2019年)
STM32学习笔记(白话文理解版)—外部IO中断实验
Introduction of safety helmet wearing recognition system
NUC980-开发环境搭建
vscode插件开发——代码提示、代码补全、代码分析(续)
KANO模型——确定需求优先级的神器
scanf函数在混合接受数据(%d和%c相连接)时候的方式
Diagnostic Log and Trace——开发人员如何使用 DLT
华为IOT平台温度过高时自动关闭设备场景试用
目标检测——LeNet
Promise.race学习(判断多个promise对象执行最快的一个)
关于接口响应内容的解码