当前位置:网站首页>Sqoop imports data from Mysql to HDFS using lzop compression format and reports NullPointerException
Sqoop imports data from Mysql to HDFS using lzop compression format and reports NullPointerException
2022-04-23 20:11:00 【My brother is not strong enough to fight】
The specific errors are as follows :
Error: java.lang.NullPointerException
at com.hadoop.mapreduce.LzoSplitRecordReader.initialize(LzoSplitRecordReader.java:63)
at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.initialize(MapTask.java:560)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:798)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:347)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
2021-12-21 11:14:28,253 INFO mapreduce.Job: Task Id : attempt_1639967851440_0006_m_000000_1, Status : FAILED
Error: java.lang.NullPointerException
at com.hadoop.mapreduce.LzoSplitRecordReader.initialize(LzoSplitRecordReader.java:63)
at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.initialize(MapTask.java:560)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:798)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:347)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
2021-12-21 11:14:31,265 INFO mapreduce.Job: Task Id : attempt_1639967851440_0006_m_000000_2, Status : FAILED
Error: java.lang.NullPointerException
at com.hadoop.mapreduce.LzoSplitRecordReader.initialize(LzoSplitRecordReader.java:63)
at org.apache.hadoop.mapred.MapTask$NewTrackingRecordReader.initialize(MapTask.java:560)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:798)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:347)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
2021-12-21 11:14:36,283 INFO mapreduce.Job: map 100% reduce 0%
2021-12-21 11:14:37,292 INFO mapreduce.Job: Job job_1639967851440_0006 failed with state FAILED due to: Task failed task_1639967851440_0006_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 0
2021-12-21 11:14:37,344 INFO mapreduce.Job: Counters: 9
Job Counters
Failed map tasks=4
Launched map tasks=4
Other local map tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=11344
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=5672
Total vcore-milliseconds taken by all map tasks=5672
Total megabyte-milliseconds taken by all map tasks=5808128
2021-12-21 11:14:37,345 ERROR lzo.DistributedLzoIndexer: DistributedIndexer job job_1639967851440_0006 failed.
resolvent :
stay core-site.xml Add configuration support LZO Compression configuration is enough .
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>版权声明
本文为[My brother is not strong enough to fight]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204210556214387.html
边栏推荐
- LeetCode动态规划训练营(1~5天)
- C语言的十六进制printf为何输出有时候输出带0xFF有时没有
- R language ggplot2 visualization: ggplot2 visualizes the scatter diagram and uses geom_ mark_ The ellipse function adds ellipses around data points of data clusters or data groups for annotation
- uIP1. 0 actively sent problem understanding
- nc基础用法2
- Building googlenet neural network based on pytorch for flower recognition
- 山东大学软件学院项目实训-创新实训-网络安全靶场实验平台(八)
- MySQL 进阶 锁 -- MySQL锁概述、MySQL锁的分类:全局锁(数据备份)、表级锁(表共享读锁、表独占写锁、元数据锁、意向锁)、行级锁(行锁、间隙锁、临键锁)
- Mysql database - single table query (II)
- 【h264】libvlc 老版本的 hevc h264 解析,帧率设定
猜你喜欢
Project training of Software College of Shandong University - Innovation Training - network security shooting range experimental platform (6)
LeetCode异或运算
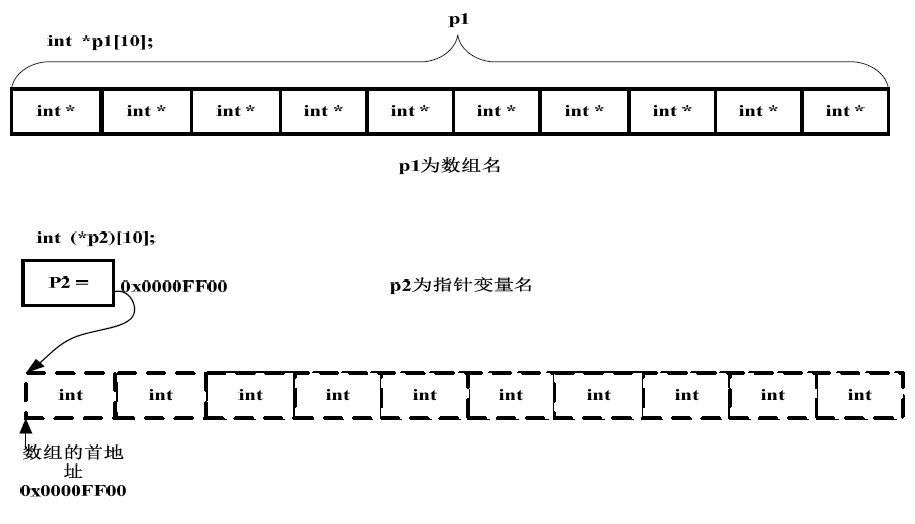
Distinction between pointer array and array pointer
【文本分类案例】(4) RNN、LSTM 电影评价倾向分类,附TensorFlow完整代码

STM32 Basics
如何在BNB鏈上創建BEP-20通證

The textarea cursor cannot be controlled by the keyboard due to antd dropdown + modal + textarea
网络通信基础(局域网、广域网、IP地址、端口号、协议、封装、分用)

AQS learning
Fundamentals of programming language (2)
随机推荐
还在用 ListView?使用 AnimatedList 让列表元素动起来
Command - sudo
SRS 的部署
NC basic usage 4
使用 WPAD/PAC 和 JScript在win11中进行远程代码执行1
nc基础用法2
LeetCode动态规划训练营(1~5天)
[numerical prediction case] (3) LSTM time series electricity quantity prediction, with tensorflow complete code attached
Openharmony open source developer growth plan, looking for new open source forces that change the world!
使用 WPAD/PAC 和 JScript在win11中进行远程代码执行
【2022】将3D目标检测看作序列预测-Point2Seq: Detecting 3D Objects as Sequences
PCL点云处理之计算两平面交线(五十一)
Physical meaning of FFT: 1024 point FFT is 1024 real numbers. The actual input to FFT is 1024 complex numbers (imaginary part is 0), and the output is also 1024 complex numbers. The effective data is
Kibana reports an error server is not ready yet. Possible causes
Redis cache penetration, cache breakdown, cache avalanche
PHP reference manual string (7.2000 words)
Mysql database - single table query (I)
CVPR 2022 | QueryDet:使用级联稀疏query加速高分辨率下的小目标检测
R语言使用timeROC包计算无竞争风险情况下的生存资料多时间AUC值、使用confint函数计算无竞争风险情况下的生存资料多时间AUC指标的置信区间值
NC basic usage