当前位置:网站首页>Node-3.构建Web应用(一)
Node-3.构建Web应用(一)
2022-08-11 05:24:00 【想要成为程序媛的DUDUfine】
文章目录
NodeJS构建Web应用(一)
基础功能
对于Web应用而言,在具体的业务中,客户端和服务器端发送报文,服务器解析报文分析请求头,我们经常都需要:
- 判断请求方法
- 解析URL的路径
- 解析URL上的查询字符串
- Cookie的解析
- Session(会话)的处理
- Basic认证
- 解析表单数据
- 对任意格式的文件上传处理
请求方法
Web应用中,常见的请求方法是GET和POST,除此之外,还有HEAD、DELETE、PUT、DELETE等方法。
请求方法存在报文的第一行的第一个单词。
GET /path?foo=bar HTTP/1.1
服务器一般只需要处理GET和POST两类请求, 但是在RESTful类Web服务中请求方法决定资源的操作行为。
PUT代表新建一个资源;
POST表示要更改一个新资源;
GET表示查看一个资源;
DELETE表示要删除一个资源。
可以通过请求方法来决定响应行为,如:
function (req, res) {
switch (req.method) {
case 'POST':
update(req, res);
break;
case 'DELETE':
remove(req, res);
break;
case 'PUT':
create(req, res);
break;
case 'GET':
default:
get(req, res);
}
}
路径解析
处理请求有时候需要根据路径来进行处理。
路径一般会存在于报文的第一行第二部分
GET /path?foo=bar HTTP/1.1
HTTP_Parser将报文路径解析为req.url。一般而言,完整的URL地址是如下这样的:
http://user:[email protected]:8080/p/a/t/h?query=string#hash
客户端代理(浏览器)会将这个地址解析成报文,将路径和查询部分放在报文第一行。需要注意的是,hash部分会被丢弃,不会存在于报文的任何地方。
最常见的根据路径进行业务处理的应用就是静态文件服务器,它会根据路径去查找磁盘中的文件,然后将其响应给客户端,如下:
function (req, res) {
var pathname = url.parse(req.url).pathname;
fs.readFile(path.join(ROOT, pathname), function (err, file) {
if (err) {
res.writeHead(404);
res.end('找不到相关文件。- -');
return;
}
res.writeHead(200);
res.end(file);
});
}
另一种比较常见的分发场景是根据路径来选择控制器,他将路径为控制器和行为的组合,无需额外配置路由信息,如下:
/user(user的控制器)/addage(行为是添加)/10(参数)
后台的会匹配到对应的controller,然后再匹配到对于的控制器行为,剩余值作为参数。
查询字符串
查询字符串位于路径之后,在地址栏中路径后的 “?foo=bar&baz=val” 字符串就是查询字符串。这个字符串会跟随在路径后,形成请求报文首行的第二部分。这部分内容经常需要为业务逻辑所用,Node提供了 “querystring” 模块用于处理这部分数据,如下所示:
var url = require('url');
var querystring = require('querystring');
var query = querystring.parse(url.parse(req.url).query);
更简洁的方法是给url.parse()传递第二个参数,如下所示:
var query = url.parse(req.url, true).query;
它会将foo=bar&baz=val解析为一个JSON对象,如下所示:
{
foo: 'bar',
baz: 'val'
}
在业务调用产生之前,我们的中间件或者框架会将查询字符串转换,然后挂载在请求对象上供业务使用,如下所示:
function (req, res) {
req.query = url.parse(req.url, true).query;
hande(req, res);
}
如果查询字符串中的键出现多次,那么它的值会是一个数组,如图:
// foo=bar&foo=baz
var query = url.parse(req.url, true).query;
// {
// foo: ['bar', 'baz']
// }
注意:
业务的判断一定要检查值是数组还是字符串,否则可能出现TypeError异常的情况。
Cookie
Cookie介绍
HTTP是无状态协议,我们在现实的业务中需要保留一些状态,否则不能区别用户的身份。Cookie就可以用来标识和认证一个用户。
Cookie的处理过程为:
- 服务器向客户端发送Cookie
- 浏览器将Cookie保存
- 之后每次浏览器都会将Cookie发向服务器端
客户端发送的Cookie在请求报文的Cookie字段中,Node的HTTP_Parser会将所有报文字段解析到req.headers上,Cookie就是req.header.cookie,Cookie的值是键值对形式的字符串,需要用Cookie某个值的时候需要手动获取Cookie进行字符串切割处理:
var parseCookie = function (cookie) {
var cookies = {};
if (!cookie) {
return cookies;
}
var list = cookie.split(';');
for (var i = 0; i < list.length; i++) {
var pair = list[i].split('=');
cookies[pair[0].trim()] = pair[1];
}
return cookies;
};
Cookie的性能影响
如果设置了Cookie,在设置的域名下所有的请求都会带上这些Cookie,从性能优化上考虑,可以:
- 减小Cookie的大小
过长的Cookie会消耗性能,所以Cookie不应该存放过多数据,只存必要的数据; - 为静态组件使用不同的域名
一些静态文件是不关心状态的,Cookie对它而言几乎是无用的,可以为不需要Cookie的资源换个域名,可以减少无效的Cookie的传输,使得Cookie不再影响静态资源。而且还可以突破浏览器下载线程和数量的限制,因为域名不同,下载线程数翻倍。但是有一个缺点就是多一个域名需要多一次DNS查询。 - 减少DNS查询
减少DNS查询和使用不同的域名是冲突的,不过现在的浏览器都会进行DNS缓存可以削弱这个副作用。
Cookie可以通过后端添加协议头的字段设置外,在前端浏览器中也可以通过JavaScript进行修改,浏览器将document通过document.cookie暴露给了JavaScript。前端在修改Cookie后,后续的网络请求都会携带改后的值。
广告和在线统计邻域是最为依赖Cookie的,通过第三方的广告或统计脚本,将Cookie和当前页面绑定,这样可以标识用户,得到用户的浏览习惯。广告商就可以定向投放广告了。尽管这样的行为看起来很可怕,不过Cookie只具有标识性,不能做具有破坏性的事情。
Session
Session与Cookie的区别
Cookie可以在前后端进行修改,因此数据极容易被篡改和伪造,Cookie对于敏感数据的保护是无效的。
Session的数据只保留在服务器端,客户无法修改,数据的安全性得到了保障,数据也无须在协议中每次都被传递。
Session的实现方式
Session如何将每个客户和服务器中的数据一一对应起来?
常见的有两种实现方式:
第一种:基于Cookie来实现用户和数据的映射
可以将口令放在Cookie中,而不是所有的数据。Cookie中存放口令还是没有问题的,因为口令一旦被篡改了,和服务器存在的数据映射关系也会失效。并且Seesion的有效期通常较短,普遍的设置是20分钟,如果20分钟内客户端和服务器端没有交互产生,服务器就会将数据删除。由于数据过期时间比较短,且在服务器存储数据,因此安全性相对比较高。第二种:通过查询字符串来实现浏览器端和服务器端数据的对应
通过检查请求的查询字符串,如果没有值,会先生成带值的URL然后再让浏览器重定向跳转到指定页面。
虽然这种方案无需在响应时设置Cookie,但是带来的风险远大于基于Cookie实现的风险,因为只要将地址发给另一个人,他就可以拥有相同的身份。
如何产生口令?
服务器启动了Session,它将约定一个规则产生唯一值作为Session的口令,这个值可以随意约定,比如Connect_uid,Tomcat会采用jssesionid等。
一旦服务器检查用户请求Cookie中没有携带这个值,就会为之生成一个值,并设定超时时间,请求到来时,检查Cookie中的口令与服务器端的数据,如果过期,就要重新生成,在响应中重新为客户端设置新的值。
生成Session的代码如下:
var sessions = {};
var key = 'session_id';
var EXPIRES = 20 * 60 * 1000;
var generate = function () {
var session = {};
session.id = (new Date()).getTime() + Math.random();
session.cookie = {
expire: (new Date()).getTime() + EXPIRES
};
sessions[session.id] = session;
return session;
};
Session与内存的处理
Session数据直接存放在内存中会产生的问题
由于Node存在内存限制,如果用户增多,就有可能达到内存限制的上限,内存的数据量大会引起频繁的垃圾回收扫描,引起性能问题。
另一个存在的问题是可能会为了利用多核CPU而启动多个进程,用户请求的连接将可能随意分配到各个进程中,而Node的进程与进程之间是不能直接共享内存的,可能会引起用户Session错乱的问题。
Session集中化
解决性能问题和Session数据无法跨进程共享的问题,常用的方案是将Session集中化 ,将原本可能分散在多个进程中的数据统一到集中的数据存储中。
常用的工具是Redis、Memcached等,通过这些高效的缓存,Node进程无须在内部维护数据对象,垃圾回收问题和内存限制问题都可以迎刃而解,并且这些高速缓存设计的缓存过期策略更合理更高效,比Node中自行设计的缓存策略更好。
采用第三方缓存来存储Session引起的一个问题是会引起网络访问。理论上来说访问网络中的数据要比访问本地磁盘中的数据速度要慢,因为涉及到握手、传输以及网络终端自身的磁盘I/O等,尽管如此但依然会采用这些高速缓存的理由有以下几条:
- Node与缓存服务保持长连接,而非频繁的短连接,握手导致的延迟只影响初始化。
- 高速缓存直接在内存中进行数据存储和访问。
- 缓存服务通常与Node进程运行在相同的机器上或者相同的机房里,网络速度受到的影响较小。
- 尽管采用专门的缓存服务会比直接在内存中访问慢,但其影响小之又小,带来的好处却远远大于直接在Node中保存数据。
Session与安全
虽然Session保存在后端,可以保障安全,但是无论是通过Cookie还是将以查询字符串的实现方式保存口令,还是存在口令被盗用的情况。如果Web应用的用户很多,有些简单的生成口令算法生成的口令值有可能被命中。一旦口令被伪造,服务器端的数据也可能间接被利用。
怎么可以让Session更加安全?主要指如何让口令更加安全。
- 有一种做法是口令通过私钥加密进行签名,使得伪造的成本变高。
比如,将值通过私钥签名,由".“分割口令原值和签名,再设置到Cookie或跳转URL中,服务端在响应的时候将口令和签名进行对比,如果签名非法,就将服务器端的数据立即过期。
如果攻击者知道”."前的口令,但是不知道私钥,就不能伪造签名,从而实现对Session的保护。
但是如果攻击者通过某种方式(比如XSS获得Cookie)获得了口令和签名,那他就能实现身份的伪装。 - 一种方案是将客户端的某些独有信息与口令作为原值,然后签名,这样攻击者一旦不在原始的客户端上进行访问,就会导致签名失败。这些独有信息包括用户IP和用户代理(User Agent)。(虽然原始用户与攻击者之间也存在上述信息相同的可能性,如局域网出口IP相同,相同的客户端信息等,不过增加这些考虑还是能够提高安全性。)
缓存
Web应用需要传输构成界面的组件(HTML、JavaScript、CSS文件等)和数据,其中有些静态资源内容在大多数场景下并不经常变更却需要在每次的应用中向客户端传递,如果不进行处理,那么它将造成不必要的带宽浪费。如果网络速度较差,就需要花费更多时间来打开页面,对于用户的体验将会造成一定影响。
所以可以让浏览器缓存静态资源。可以:
- 添加Expires 或Cache-Control 到报文头中
对于强缓存(请求头设置Expires 或Cache-Control),浏览器请求时,会对本地文件进行检查,如果本地已经缓存且没有过期,会直接使用本地的资源; - 配置If-Modified-Since或ETags
对于协商缓存(请求头设置If-Modified-Since),浏览器请求资源时需要发起一次GET条件请求,请求报文中有If-Modified-Since字段,询问服务器是否有更新版本及服务器文件的最后修改时间,如果没有新的版本,服务器会返回一个304状态码,客户端就是要本地的资源;如果服务器有新的版本,就将新的内容发送给客户端,客户端放弃本地版本。 - 让Ajax 可缓存
通常缓存只应用在GET请求中,对于POST、DELETE、PUT这类带行为的请求操作不做任何缓存。
Expires和Cache-Control的区别
Expires是一个GMT格式的时间字符串。浏览器在接到这个过期值后,只要本地还存在这个缓存文件,在到期时间之前它都不会再发起请求。
Expires的缺陷在于浏览器与服务器之间的时间可能不一致,这可能会带来一些问题,比如文件提前过期,或者到期后并没有被删除。
Cache-Control以更丰富的形式,实现相同的功能。可以为Cache-Control设置了max-age值。
Cache-Control能够避免浏览器端与服务器端时间不同步带来的不一致性问题。只要进行类似倒计时的方式计算过期时间即可。除此之外,Cache-Control的值还能设置public、private、no-cache、no-store等能够更精细地控制缓存的选项。
由于在HTTP1.0时还不支持max-age,如今的服务器端在模块的支持下多半同时对Expires和Cache-Control进行支持。在浏览器中如果两个值同时存在,且被同时支持时,max-age会覆盖Expires。
If-Modified-Since和ETags的区别
If-Modified-Since是一个GMT格式的时间字符串。它向服务器发送条件请求是会附带If-Modified-Since字段,询问服务器是否有更新的版本,本地文件的最后修改时间。如果服务器没有新的版本,会响应304状态码,客户端就使用本地的资源。
但是使用时间戳有些缺陷,可能时间戳发生改变但是文件内容没有改变;而且时间戳只能精确到秒,更新频繁的内容无法生效。
HTTP1.1引入ETag(Entity Tag),ETag的请求头和响应字段是If-None-Match/ETag。ETag由服务器端生成,服务器可以决定他的生成规则,比如将文件内容生成散列值,这样更加内容生成的标识判断是否有更新,比起由时间戳判断更准确。
协商缓存在每次请求前都会向服务器发起一个HTTP请求,服务器响应客户端资源没有改动比起重新加载整个页面代价还是小的多。
清除缓存
- 在URL路径上加上Web应用版本号或资源的版本号
- 路径上加上文件内容的hash值(更精准)
Basic认证
Basic认证是当客户端与服务器端进行请求时,允许通过用户名和密码实现的一种身份认证方式。
如果一个页面需要Basic认证,它会检查请求报文头中的Authorization字段的内容,该字段的值由认证方式和加密值构成,如下所示
$ curl -v "http://user:[email protected]/"
> GET / HTTP/1.1
> Authorization: Basic dXNlcjpwYXNz
> User-Agent: curl/7.24.0 (x86_64-apple-darwin12.0) libcurl/7.24.0 OpenSSL/0.9.8r zlib/1.2.5
> Host: www.baidu.com
> Accept: */*
在Basic认证中,它会将用户和密码部分组合:username + “:” + password。然后进行Base64编码,如下所示:
var encode = function (username, password) {
return new Buffer(username + ':' + password).toString('base64');
};
如果用户首次访问该网页,URL地址中也没携带认证内容,那么浏览器会响应一个401未授权的状态码
WWW-Authenticate字段告知浏览器采用什么样的认证和加密方式。一般而言,未认证的情况下,浏览器会弹出对话框进行交互式提交认证信息,
当认证通过,服务器端响应200状态码之后,浏览器会保存用户名和密码口令,在后续的请求中都携带上Authorization信息。
Basic认证有太多的缺点,它虽然经过Base64加密后在网络中传送,但是这近乎于明文,十分危险,一般只有在HTTPS的情况下才会使用。
不过Basic认证的支持范围十分广泛,几乎所有的浏览器都支持它。
边栏推荐
- GBase 8s共享内存中的常驻内存段
- 数据库的基本语法(其一)
- websocket聊天通讯(全局封装)
- The kernel communicates with user space through character devices
- XSS跨站脚本攻击详解以及复现gallerycms字符长度限制短域名绕过
- 关于安全帽识别系统,你需要知道的选择要点
- Redis持久化方案RDB详解
- GBase 8a 并行技术
- 更新GreenDAO实体类导致的编译错误
- Mei cole studios - fifth training DjangoWeb application framework + MySQL database
猜你喜欢

目标检测——LeNet

Safety helmet recognition system

360°大视野安全帽识别系统-深度学习智能视频分析

Waymo dataset usage introduction (waymo-open-dataset)

梅科尔工作室-HarmonyOS应用开发第一次培训
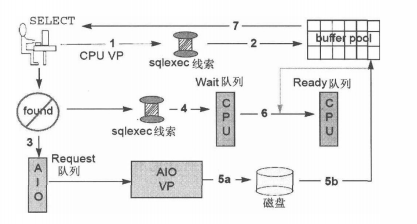
GBase 8s中IO读写方法
Maykle Studio - Second Training in HarmonyOS App Development
xss.haozi靶场通关

跳转到微信小程序方法
LAGRANGIAN FLUID SIMULATION WITH CONTINUOUS CONVOLUTIONS
随机推荐
TAMNet:A loss-balanced multi-task model for simultaneous detection and segmentation
GBase 8a 并行技术
AI智能图像识别的工作原理及行业应用
梅科尔工作室-DjangoWeb 应用框架+MySQL数据库第四次培训
如何修改严格模式让MySQL5.7插入用户表的方式新建用户成功?delete和drop的不同
XSS跨站脚本攻击详解以及复现gallerycms字符长度限制短域名绕过
MPLS 实验
Toward a Unified Model
Hardhat Recognition System - Solving Regulatory Conundrums
LiDAR Snowfall Simulation for Robust 3D Object Detection
LiDAR Snowfall Simulation for Robust 3D Object Detection
MGRE实验
内核与用户空间通过字符设备通信
LAGRANGIAN FLUID SIMULATION WITH CONTINUOUS CONVOLUTIONS
Redis分布式锁
经纬度距离
Zhejiang University School of Software 2020 Guarantee Research Computer Real Question Practice
软件架构之--MVC、MVP、MVVM
>>数据管理:DAMA简介
mAPH - Waymo dataset