当前位置:网站首页>Unity Shader学习
Unity Shader学习
2022-04-23 15:48:00 【林枫依依】
GPU的优越性:
由于GPU具有高并行结构,所以GPU在处理图形数据和复杂算法方面拥有比CPU更高的效率。CPU大部分面积为控制器和寄存器,与之相比,GPU拥有更多的ALU(Arthmetic Logic Unit:逻辑运算单元)用于数据处理,这样的结构适合对密集型数据进行并行处理。
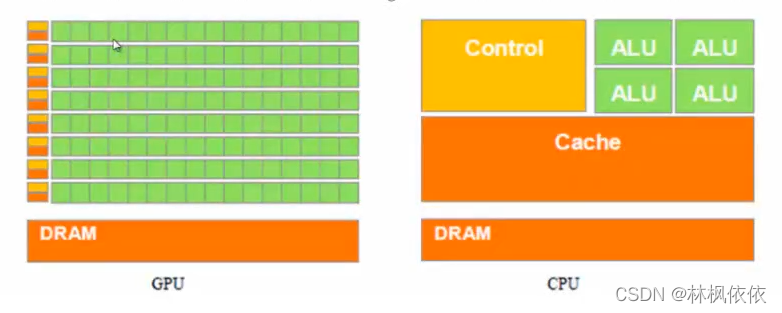
GPU采用流式并行计算模式,可对每个数据进行独立的并行运算,所谓“对数据进行独立运算”,即:流内任意元素的计算不依赖于其它同类型数据。
GPU的缺陷:
由于“任意一个元素的计算不依赖于其它同类型数据”,导致“需要知道数据之间相关性”的算法,在GPU上难以得到实现,一个典型的例子是射线与物体的求交运算。GPU中的控制器少于CPU,致使控制能力有限。
什么是Shader Language?
Shader Language的发展方向是设计出在便携性方面可以和C++、Java等相比的高级语言,“赋予程序员灵活而方便的编程方式”,并“尽可能的控制渲染过程”,同时“利用图形硬件的并行性,提高算法效率”。
Shader Language目前有3种语言:
(1)GLSL,基于OpenGL的OpenGL Shading Language;
(2)HLSL,基于DirectX的High Level Shading Language;
(3)CG,基于英伟达公司的C for Graphic。
OpenGL简介:
OpenGL(Open Graphics Library)是一个定义了跨编程语言、跨平台的编程接口规格的专业图形程序接口。它用于三维图像(二维也行),是一个功能强大、调用方便的底层图形库。OpenGL是行业领域中最为广泛接纳的2D/3D图形API,其自诞生至今已催生了各种计算机平台及设备上的数千优秀应用程序。它独立于视窗操作系统或其他操作系统,也是网络透明的。在包含CAD、内容创作、能源、娱乐、游戏开发、制造业及虚拟现实等行业领域中,OpenGL是一个与硬件无关的软件接口,可以在不同的平台如Windows95、WindowsNT、Unix、Linux、MacOS、OS/2之间进行移植。因此,支持OpenGL的软件具有很好的移植性,可以获得非常广泛的应用。但是OpenGL的发展一直很慢,每次版本的提高新增的技术很少,大多只是对其中部分作出修改和完善。
DirectX简介:
DirectX(Direct extension,简称DX)是由微软公司创建的多媒体编程接口。由C++编程语言实现,遵循COM。被广泛适用于Microsoft Windows、Microsoft XBOX、Microsoft XBOX360和MicrosoftXBOX ONE电子游戏开发,并且只能支持这些平台。最新版本为DirectX 12,创建在最新的Windows10。DirectX是这样的一组技术:它旨在使基于Windows的计算机成为运行和显示具有丰富多媒体元素(例如全色图形、视频、3D动画和丰富音频)的应用程序的理想平台。DirectX包括安全和性能更新程序,以及许多涵盖所有技术的新功能。应用程序可以通过使用DirectX API来访问这些新功能。
CG简介:
CG语言(C for Graphic)是为GPU编程设计的高级着色语言,CG极力保留C语言的大部分语义,并让开发者从硬件细节中解脱出来,CG同时也有一个高级语言的其他好处,如代码的易重用性、可读性得到提高,编译器代码优化。CG是一个可以被OpenGL和Direct3D广泛支持的图形处理器编程语言。CG语言和OpenGL、Direct3D并不是同一层次的语言,而是OpenGL和DirectX的上层,即CG程序是运行在OpenGL和DirectX标准顶点和像素着色的基础上的。CG由英伟达公司和微软公司相互协作在标准硬件光照语言的语法和语义上达成了一致开发。所以,HLSL和CG其实是同一种语言。
渲染流水线:
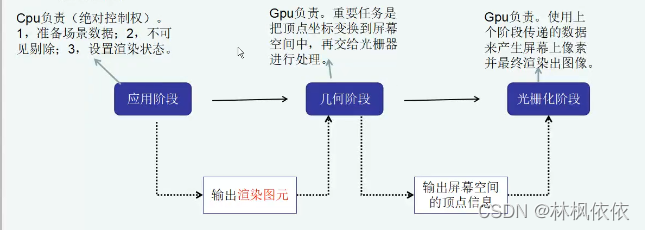
CPU应用阶段:
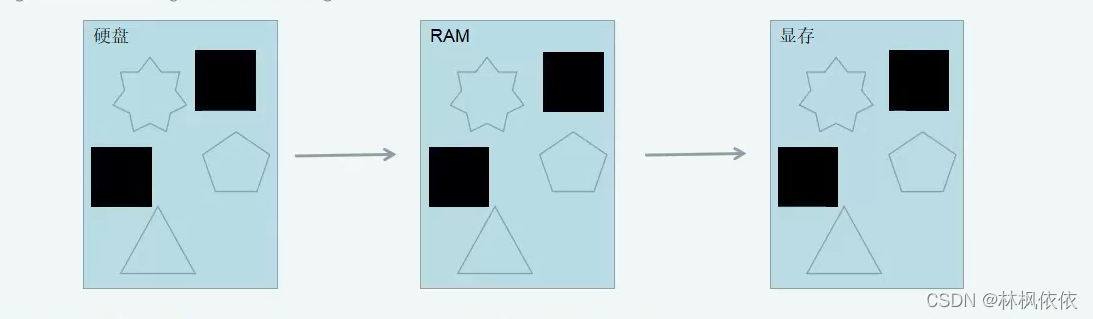
1.把数据加载到显存中;
将渲染所需数据从硬盘加载到内存中,网络纹理等数据又被加载到显存中(一般加载到显存后,内存中的数据就会被移除)。
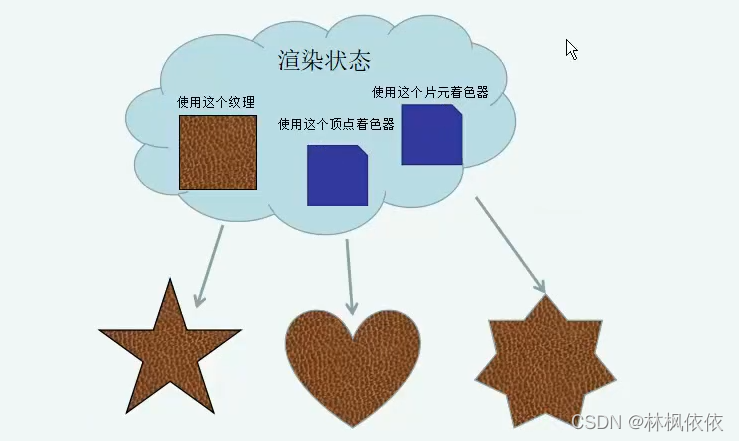
2.设置渲染状态;
这些状态定义了场景中的网格是怎么被渲染的。例如:使用哪个顶点着色器、片元着色器、光源属性、材质等。
3.调用Draw Call。
Draw Call就是一个命令,它的发起方是CPU,接收方是GPU。这个命令仅仅会指向一个需要被渲染的图元列表,而不会包含任何材质信息。
GPU流水线:
几何阶段和光栅化阶段,开发者无法拥有绝对的控制权,其实现的载体是GPU。GPU通过实现流水线化,大大加快了渲染速度。虽然我们无法完全控制这两个阶段的实现细节,但是GPU向开发者开放了很多控制权。
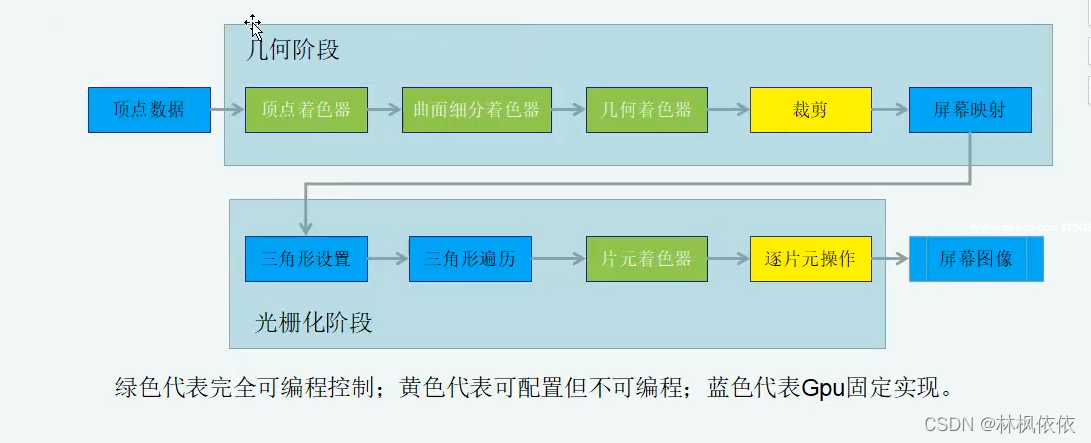
顶点数据为输入,顶点数据是由应用阶段加载到显存中,再由Draw Call指定的。这些数据随后被传递给顶点着色器。
顶点着色器是完全可编程的,它通常用于实现顶点的空间变换,顶点着色器等功能。
曲面细分着色器是一个可选着色器,用于细分图元。
几何着色器同样是可选着色器,可以被用于执行逐图元的着色操作,或者被产生于更多的图元。
裁剪的目的是将那些不在摄像机视野内的顶点裁减掉,剔除某些三角图元的面片,这个阶段可配置。
屏幕映射负责把每个图元的坐标转换到屏幕坐标系中,该阶段不可配置和编程。
三角形设置和三角形遍历都是固定函数的阶段。
片元着色器用于实现逐片元的着色操作,是完全可编程的。
逐片元操作阶段负责很多重要操作,如修改颜色、深度缓冲、进行混合等,该阶段不可编程但是可以配置。
几何阶段详解:
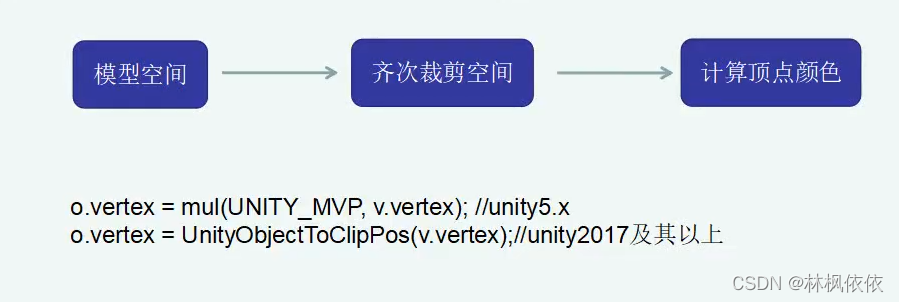
顶点着色器:顶点着色器的处理单位是顶点,也就是说,输入进来的每个顶点都会调用一次顶点着色器。顶点着色器本身不可以创建或者销毁任何顶点,而且无法得到顶点与顶点之间的关系。GPU可以利用本身的特性快速处理每一个顶点。
顶点着色器主要完成的工作:坐标变换及逐顶点光照。当然除此之外还可以输出后续阶段所需的数据等。
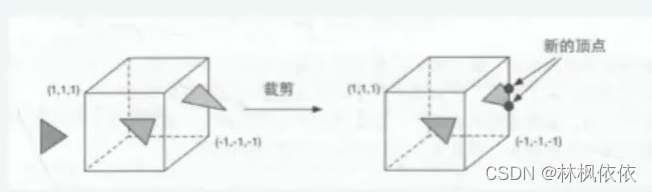
裁剪:一个图元与摄像机的关系有3种:完全在视野内、部分在视野内、完全在视野外。
完全在视野内的图元就继续传递给下一个流水线阶段,完全在视野外的图元不会继续向下传递。那些部分在视野内的图元需要进行裁剪。
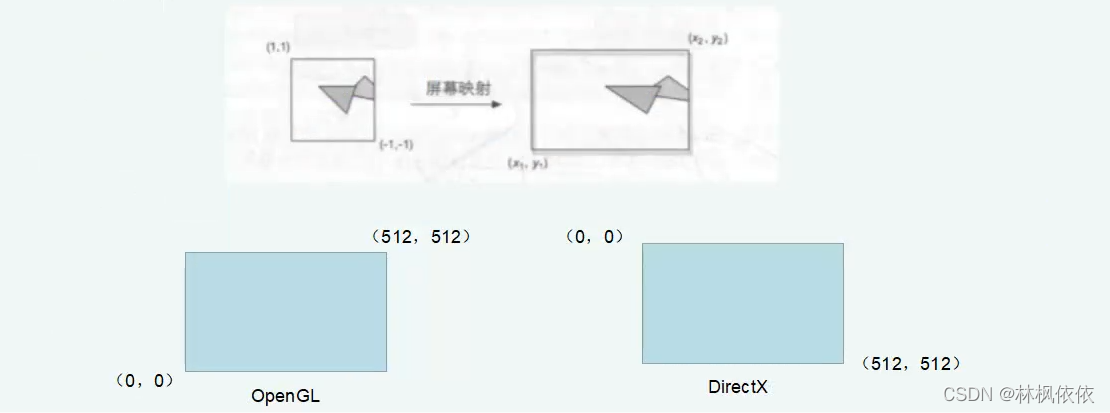
屏幕映射:屏幕映射的任务是将裁剪后的齐次坐标(NDC)转换到屏幕坐标系,屏幕坐标系是一个二维坐标系,和用于显示画面的分辨率有很大关系。
屏幕映射如下图所示:将齐次坐标下(-1,1)的坐标范围转换到(x1,y1),(x2,y2)。可以看到这个过程实际上就是一个缩放的过程。在这个处理中 z轴不做处理。屏幕坐标系和z轴构成了窗口坐标系。这些值会被传到光栅化阶段。
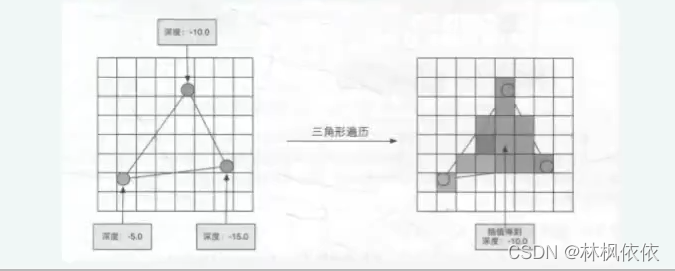
三角形设置:这个阶段会计算光栅化一个三角网格所需要的信息。上一个阶段输出的都是三角网格的顶点,即我们得到的是三角网格每条边的两个端点。如果要得到正规三角网格 对像素的覆盖情况,就必须计算每条边上的像素坐标。为了能够计算边界像素的坐标信息,就需要得到三角形边界的表示方式。
三角形遍历:这个阶段将会检查每个像素是否被一个三角网格所覆盖。如果被覆盖的情况下,就会产生一个片元。而这样一个找到那些像素被三角网格覆盖的过程 就叫做三角形遍历,也被称作扫描变换。
三角形遍历阶段会根据上一个阶段的计算结果来判断一个三角网格覆盖了哪些像素,并使用三角网格3个顶点的顶点信息对整个覆盖区域的像素进行插值。
片元着色器:片元着色器的输入是上一个阶段对顶点信息插值得到的结果,具体来说是根据那些从顶点着色器中输出的数据插值得到的。而其输出是一个或者多个颜色值。
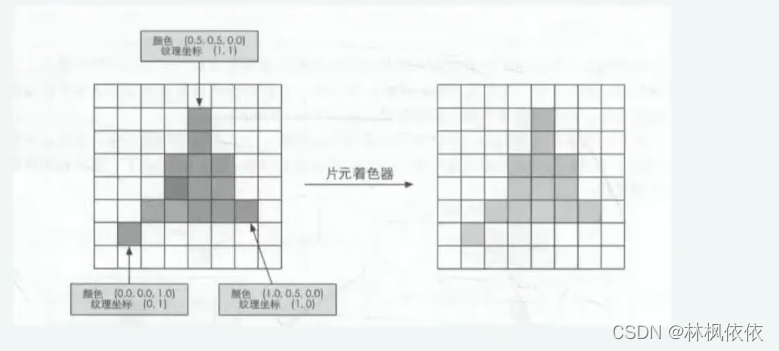
这一阶段可以完成很多重要的渲染技术,其中最重要的技术之一就是纹理采样。为了在片元着色器中进行纹理采样,我们通常会在顶点着色器阶段输出每个顶点对应的纹理坐标,然后经过光栅化阶段对三角网格的3个顶点对应的纹理坐标进行插值后,就可以得到起覆盖的片元的纹理坐标。
逐片元操作:逐片元操作时OpenGL中的说法,在DX中这个阶段被称作 输出合并阶段。
(1)决定每个片元的可见性,涉及很多测试工作,例如深度测试、模板测试;
(2)如果一个片元通过了所有测试后,就需要把这个片元的颜色值和已经储存在颜色缓冲区的色彩进行合并,或者说混合。

测试的过程实际上是一个比较复杂的过程,而且不同的图形接口(OpenGL和DX)的实现细节也不尽相同。
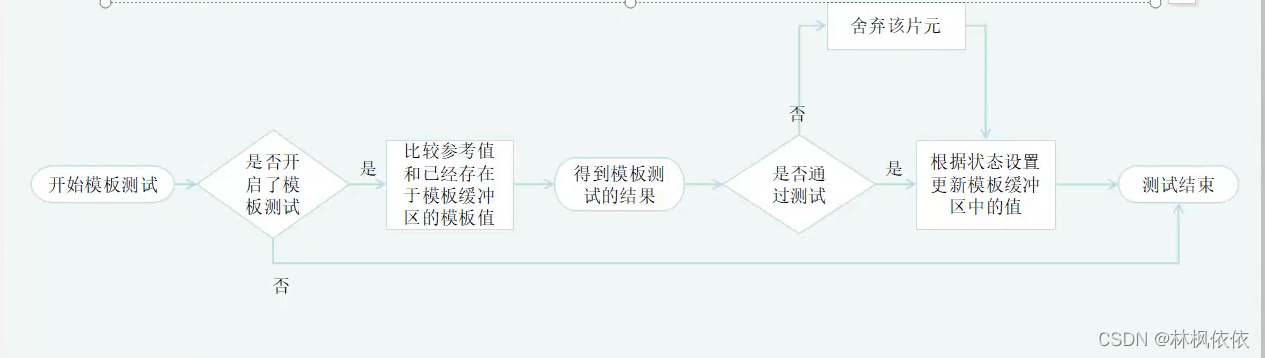
模板测试:与之相关的是模板缓冲(Stencil Buffer)。模板缓冲、颜色缓冲、深度缓冲几乎是一类东西。如果开启了模板测试,GPU首先读取(使用读取掩码)模板缓冲区中该片元位置的模板值,然后将该值和读取(使用读取掩码)到的参考值进行比较,这个比较函数可以由开发者指定,例如小于等于舍弃该片元,或者大于等于舍弃该片元。如果这个片元没有通过测试,那么该片元就会被舍弃。不管一个片元有没有通过模板测试,我们都可以根据模板测试和之后的深度测试结果来修改模板缓冲区,这个操作也是由开发者指定的。模板测试通常用于限制渲染区域,或者渲染阴影,轮廓渲染等。
深度测试:如果开启了深度测试,GPU会把该片元的深度值和已经存在于深度缓冲中的深度值进行比较。这个比较函数也是可以由开发者设置的,例如小于时舍弃该片元,或者大于时舍弃该片元。通常这个比较函数是小于等于,即:如果这个片元的深度大于等于当前深度缓冲区中的值,那么就舍弃它。这是因为我们总想只显示出离摄像机最近的物体,而那些被其他物体遮挡的就不需要出现在屏幕上。和模板测试不同的是:如果一个片元没有通过深度测试,它就没有权利更改深度缓冲区的值。如果一个片元通过了测试,那么开发者可以指定是否要用这个片元的深度值覆盖所有的深度值。
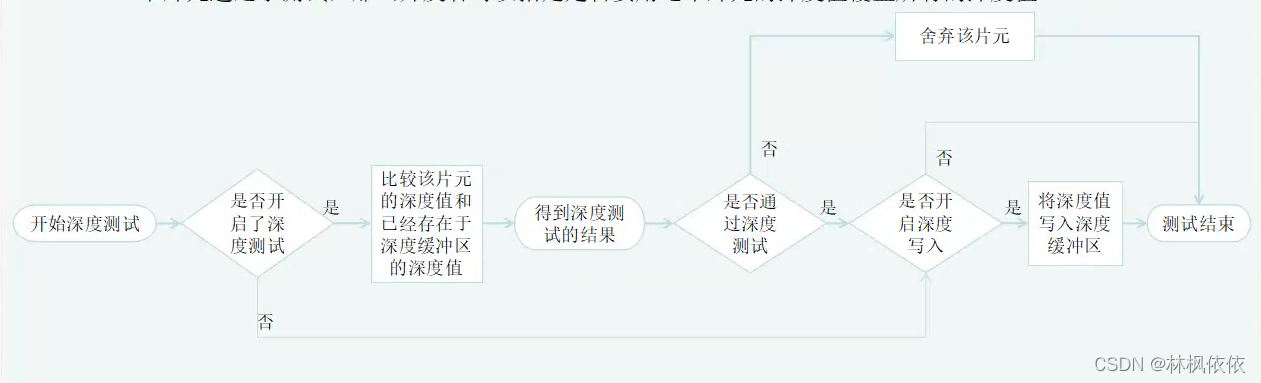
合并混合:合并,渲染过程是一个物体接着一个物体画到屏幕上,而每个像素的颜色信息被储存在一个名为颜色缓冲的地方。因此,当我们执行渲染时,颜色缓冲中 往往已经有了上次渲染之后的颜色结果,那么,我们使用本次渲染得到的颜色 完全覆盖掉之前的结果? 还是进行其他处理?就是合并需要解决的问题。
对于不透明物体,开发者可以关闭混合(Blend)操作,这样片元着色器计算得到的颜色值就会覆盖掉颜色缓冲区中的像素值。但对于半透明物体,就需要混合操作 来让这个物体看起来是透明的。
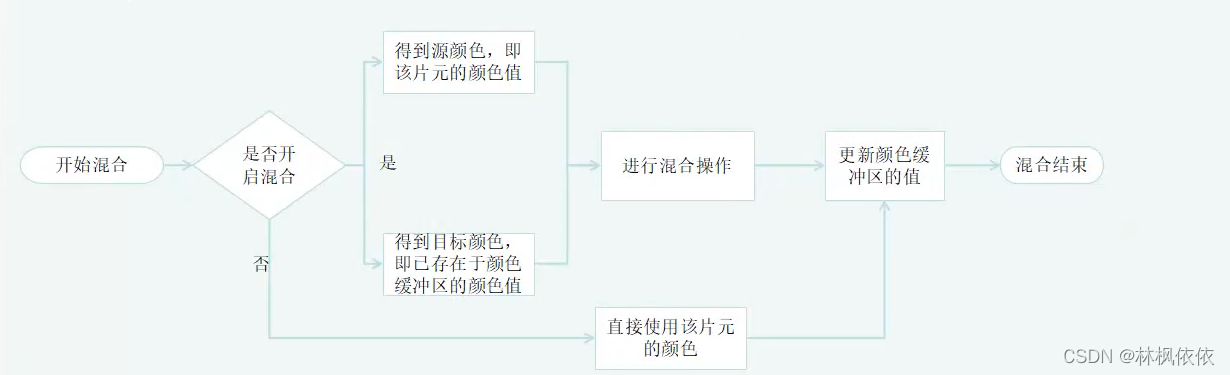
各种测试总结:
各种测试的顺序并不是唯一的,虽然从逻辑上来说这些测试是在片元着色器之后进行的,但对于大多数GPU来说,会尽可能在执行片元着色器之前进行这些测试。因为当你在片元着色器进行了大量的计算及设置,最后测试没通过,可以说是计算成本全都浪费了。作为一个想充分提高速度的GPU,肯定是希望尽可能早的指定哪些片元会被舍弃,对这些片元就不再需要在使用片元着色器来计算它们的颜色。Unity的渲染流水中,深度测试就是在片元着色器之前。
但是如果将这些测试提前的话,其检验结果可能会与片元着色器中的一些操作冲突。例如片元着色器在进行透明度测试,而这个片元没有通过透明度测试,我们会在着色器中调用API(clip)函数来手动将其舍弃。这就导致GPU无法提前执行各种测试。因此如果片元着色器中的操作和提前测试发生冲突就会禁用提前测试。这样性能上就会下降,也是透明度测试导致性能下降的原因。
当模型图元经过层层计算及测试后,就会显示到屏幕上。我们的屏幕显示的就是颜色缓冲区中的颜色值。但是为了避免我们看到正在光栅化的图元,GPU会使用双重缓冲策略。对场景的渲染时发生在幕后的,即在后置缓冲中,一旦场景已经被渲染到后置缓冲中,GPU就会交换后置缓冲区和前置缓冲的内容,前置缓冲区就是显示在屏幕上的图像。由此,保证我们看到的图像是连续的。
注意:这里的流水线名、顺序,在不同资料上看到可能是不一样的。一个原因是由于图像编程接口的实现不尽相同,另一个是GPU底层可能做一些优化等等。
附加内容:
1.CPU与GPU如何并行工作?
我们之前看到的是一个流水线式的模式,而如果需要CPU和GPU并行工作,就需要使用命令缓冲区(Command Buffer)。
命令缓冲区包含了一个缓冲队列,由CPU向其中添加命令,而由GPU从中读取命令,添加和读取过程是相互独立的。命令缓冲区使得CPU和GPU可以相互独立工作。当CPU需要渲染一些对象时,它就可以从命令队列中取出一个命令并执行。
命令缓冲区有很多种类,DrawCall就是一种,其他命令还有改变渲染状态等。
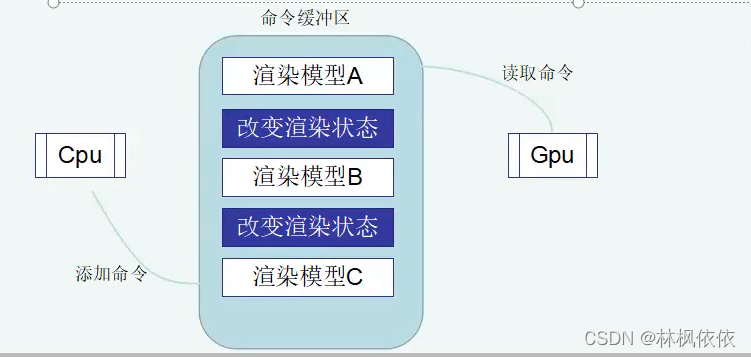
2.什么是固定管线渲染?
固定函数的流水线(Fixed-Function Pipeline),简称固定管线,通常是指在较旧的GPU上实现的渲染流水线。这种流水线只给开发者提供一些配置操作,但开发者没有对流水线阶段的完全控制权。
在Unity中目前的固定管线Shader都会自动编译顶点片元Shader。
3.什么是Shader?
GPU流水线上一些可高度编程的阶段,而由 着色器编译出来的最终代码是会在GPU上运行的。有一些特定类型的着色器,如:顶点着色器、片元着色器等。依靠着色器我们可以控制流水线中的渲染细节,例如用顶点着色器来进行顶点变换及传递数据,用片元着色器来进行逐像素渲染。
Unity Shader的基础:ShaderLab
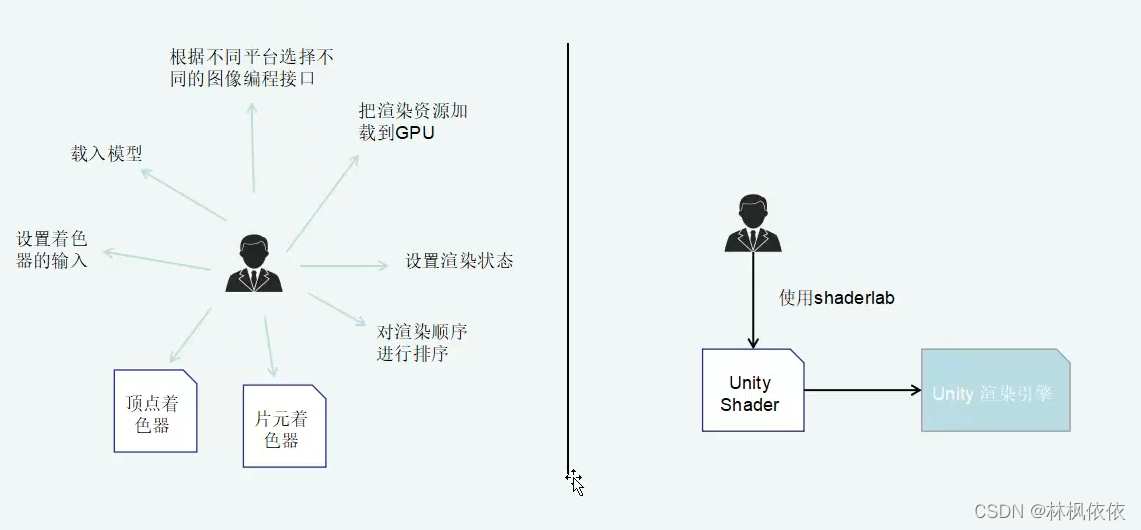
UnityShader的属性:
在这里我们创建一个片元着色器(Unlit Shader):
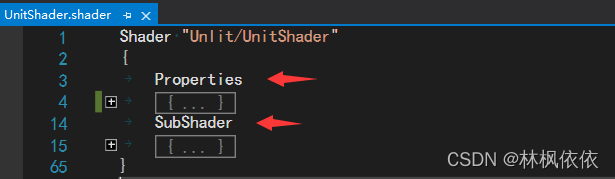
写入Properties属性块:
Properties
{
_Int("Int",int)=2
_Float("Float",float) =1.5
_Range("Range",range(0.0,2.0)) =1.0
_Color("Color",Color) = (1,1,1,1)
_Vector("Vector",Vector) = (1,4,3,8)
_MainTex("Texture", 2D) = "white" {}
_Cube("Cube",Cube) = "white"{}
_3D("3D",3D) = "black"{}
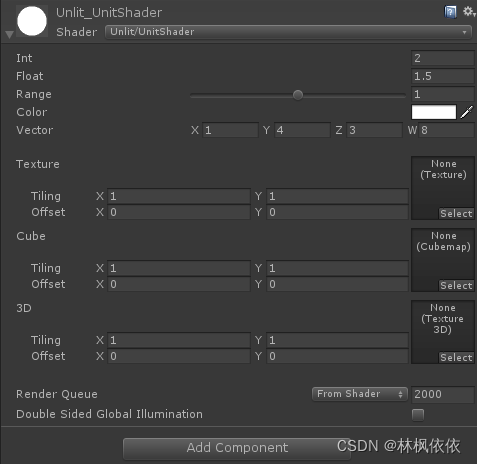
}此时,Shader对应的材质球下 会呈现出属性值:
SubShader:
版权声明
本文为[林枫依依]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_41603955/article/details/124298724
边栏推荐
- CVPR 2022 优质论文分享
- Introduction to dynamic programming of leetcode learning plan day3 (198213740)
- PHP function
- Basic concepts of website construction and management
- JS regular détermine si le nom de domaine ou le chemin de port IP est correct
- 实现缺省页面
- Basic greedy summary
- fatal error: torch/extension. h: No such file or directory
- 使用 Bitnami PostgreSQL Docker 镜像快速设置流复制集群
- Fastjon2 here he is, the performance is significantly improved, and he can fight for another ten years
猜你喜欢
MySQL集群模式與應用場景

Treatment of idempotency
cadence SPB17. 4 - Active Class and Subclass
MySQL Cluster Mode and application scenario
时序模型:门控循环单元网络(GRU)

Do we media make money now? After reading this article, you will understand
JVM - Chapter 2 - class loader subsystem

Load Balancer
Why disable foreign key constraints
KNN, kmeans and GMM
随机推荐
Upgrade MySQL 5.1 to 5.611
Spark 算子之交集、并集、差集
Treatment of idempotency
一刷312-简单重复set-剑指 Offer 03. 数组中重复的数字(e)
Basic concepts of website construction and management
Go language, array, pointer, structure
How can poor areas without networks have money to build networks?
时序模型:长短期记忆网络(LSTM)
【第5节 if和for】
Cookie&Session
Go语言切片,范围,集合
Why is IP direct connection prohibited in large-scale Internet
提取不重复的整数
js正則判斷域名或者IP的端口路徑是否正確
Load Balancer
Why disable foreign key constraints
[split of recursive number] n points K, split of limited range
Upgrade MySQL 5.1 to 5.69
Open source project recommendation: 3D point cloud processing software paraview, based on QT and VTK
Codejock Suite Pro v20. three