当前位置:网站首页>HTTP缓存机制详解
HTTP缓存机制详解
2022-08-11 05:23:00 【想要成为程序媛的DUDUfine】
一. 前言
在庞大的网络系统中,整个互联网干的事情实质上就是用户请求获取内容,而服务器响应返回用户内容。
而在整个互联网中,每时每刻都在发生以亿计量的网络请求,产生了大量的网络资源消耗。如何降低网络资源消耗,快速响应用户体验,HTTP的缓存是Web性能优化的重要手段。
了解和利用好HTTP缓存机制对于帮助我们更好地利用缓存来优化我们的应用、提升用户体验有着至关重要的作用。
接下来我们就围绕着HTTP缓存的进行详细的介绍。
二. 缓存的介绍
什么是缓存?
缓存是一种保存资源副本并在下次请求直接使用该副本的技术。
而Web缓存是可以按照规则自动保存文档副本的HTTP设备。当Web请求抵达缓存时,如果本地有“已缓存的”副本,就由本地存储设备返回这个文档,而不需要到原始服务器中获取。
为什么要使用缓存?
网络请求速度会受到服务器的性能、网络的带宽、网络条件、以及网络链路的距离等的影响。
使用缓存可以:
- 降低了对原始服务器的要求。缓存设备可以更快地响应用户,同时避免服务器过载的出现。
- 减少网络上冗余的数据传输,节省网络费用。
- 缓解了网络瓶颈的问题。不需要更多的带宽就能够更快地加载页面。
- 降低了距离时延,因为请求链路距离会更短,距离短传输速度会比较快。
1. 减少冗余的数据传输
当很多客户端访问一个热点页面时,服务器会多次将同一份文档返回给不同客户端,一些相同的字节会在网络中重复传输。
这些冗余的数据传输会消耗网络带宽,降低传输速度,加重 Web 服务器的负载。
通过缓存,就可以保留第一次服务器响应的副本,后继请求就可以由缓存的副本来应对了,这样可以减少那些流入 / 流出原始服务器的、被浪费掉了的重复流量。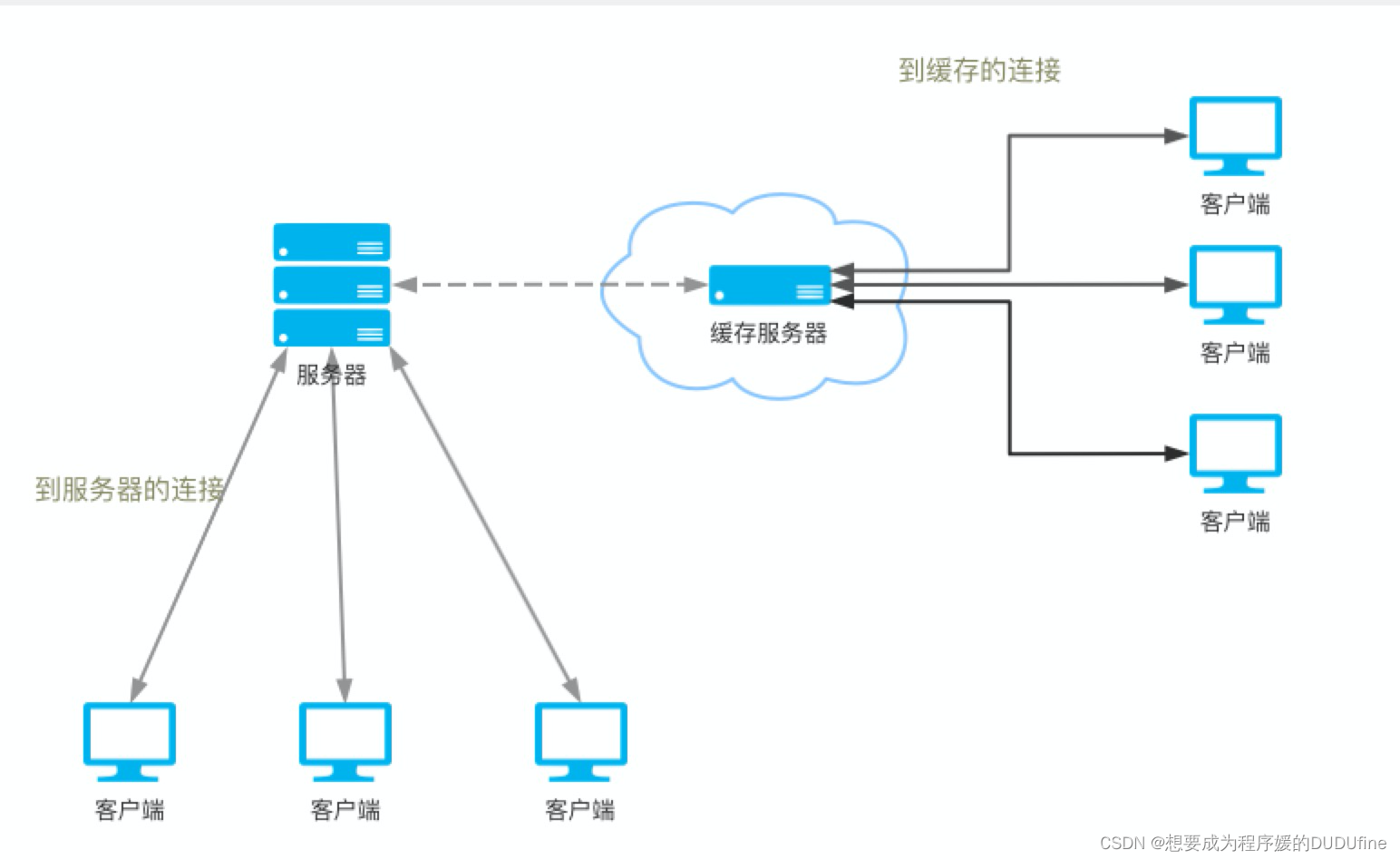
2. 缓解带宽瓶颈
缓存可以缓解网络的瓶颈问题。很多网络为本地网络客户端提供的带宽比为远程服务器提供的带宽要宽。客户端会以路径上最慢的网速访问服务器。如果客户端从一个快速局域网的缓存中得到了一份副本,那么性能就被提高了——尤其是要传输比较大的文件时。
3. 破坏瞬间拥塞
缓存在处理瞬间拥塞(Flash Crowds) 起到很大的作用。
当网络出现突发事件时(比如爆炸性新闻,或者某个名人事件),很多人会几乎同时去访问一个 Web 文档时,这个时候就会出现瞬间拥塞。由此造成的过多流量峰值可能会使网络和 Web 服务器产生灾难性的崩溃。
比如新浪就经常由于某明星事件出现瞬间拥塞,导致服务器奔溃。
这时候缓存就可以分担到服务器请求的压力,减弱瞬间拥塞带来的后果。
4. 降低距离时延
即使带宽不是问题,距离也可能成为问题。在请求链路上每台网络路由器都会增加请求的时延。即使客户端和服务器之间没有太多的路由器,请求传输的过程是需要耗费时间的。
通过缓存,可以将文件传输距离从数千公里里缩短为数十米。
就像货物配送到深圳,从深圳的仓库发货和北京发货,距离远的当然到达的时间就会比较久。
但是当我们把资源缓存在网络链路中离用户比较近的节点,那就相当于用户附近配置了一个仓库,从离用户最近的节点发货,就可以更快地把货物送到,用户体验就会更好了。
三. 缓存有效性
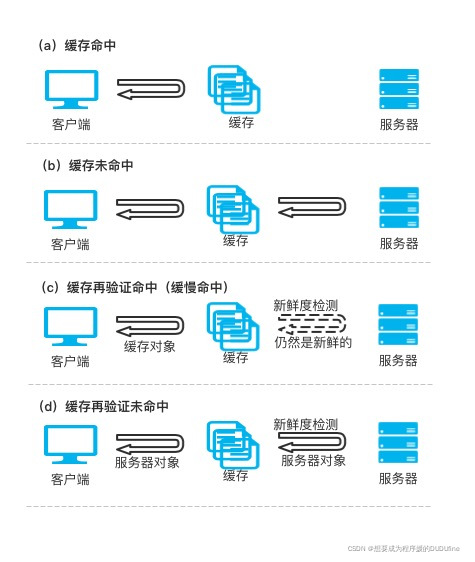
命中和未命中的
由上面的介绍,我们知道了缓存的好处了,但是缓存无法保存Web的所有文档,即使有,文档也会发生变化,很多缓存也不能及时地进行更新。所以缓存无法为所有的请求提供服务。
当已有的副本为到达缓存的请求提供服务,称为缓存命中(cache hit),
如果到达缓存的请求没有副本可用,而被转发给原始服务器,被称为缓存未命中(cache miss)
再验证
原始服务器的内容可能会发生变化,缓存要不时对其进行检测,看看它们保存的副本是否仍是服务器上最新的副本。这些 “新鲜度检测” ,也被称为 HTTP 再验证(revalidation)。
为了可以有效进行再验证,HTTP定义了一些规则来快速检测出内容是否是最新的,缓存可以在任意时刻,以任意的频率对副本进行再验证。
但是验证的过程是需要时间和耗费带宽的,所以大部分缓存只有在客户端发起请求,并且副本旧得足以需要检测的时候,才会对副本进行再验证。
后面我们会解释 HTTP 的新鲜度检测规则。
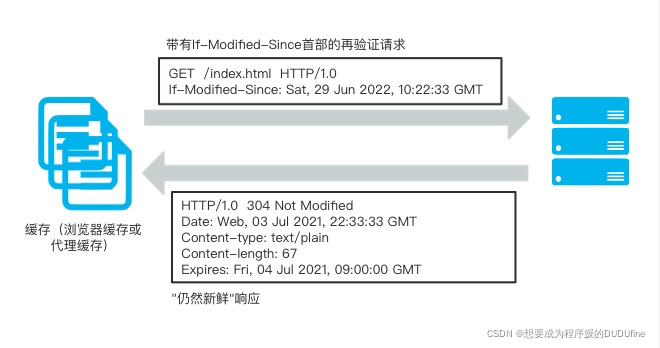
当缓存缓存对缓存的副本进行再验证时,会向原始服务器发送一个小的再验证请求。
如果内容没有变化,服务器会以一个小的 304 Not Modified 进行响应。
只要缓存知道副本仍然有效,就会再次将副本标识为暂时新鲜的,并将副本提供给客户端,这被称作 再验证命中(revalidate hit)或 缓慢命中 (slow hit)。
因为这种方式需要与原始服务器进行核对,所以会比单纯的缓存命中要慢,但又因为它没有从服务器中获取对象数据,所以要比缓存未命中快一些。
再验证会有三种情况:
1.再验证命中
如果服务器对象未被修改,服务器会向客户端发送一个小的 HTTP 304 Not Modified 响应。
2.再验证未命中
如果服务器对象与已缓存副本不同,服务器向客户端发送一条普通的、带有完整内容的 HTTP 200 OK 响应。
3.对象被删除
如果服务器对象已经被删除了,服务器就回送一个 404 Not Found 响应,缓存也会将其副本删除。
命中率
由缓存提供服务的请求所占的比例被称为缓存命中率(cache hit rate),有时也被称为文档命中率(document hit rate)。
缓存的管理者希望缓存命中率接近 100%,而实际得到的命中率则与缓存的大小、缓存数据的变化、如何配置缓存、用户的喜好有关,所以命中率很难预测。但对现在中等规模的 Web 缓存来说,有40% 的命中率是比较合理的。即使是中等规模的缓存,提供常见文档也可以显著地提高性能、减少流量了。
字节命中率
由于文档并不全是同一尺寸的,所以文档命中率并不能说明一切。比如有些大型对象被访问的次数可能比较少,但由于尺寸的原因,对整个数据流量的贡献却更大。因此,有些人更愿意使用字节命中率(byte hit rate)作为度量值(尤其那些按流量字节付费的人!)。
字节命中率表示的是缓存提供的字节在传输的所有字节中所占的比例。通过这种度量方式,可以得知节省流量的程度。
文档命中率和字节命中率都对缓存性能的评估很重要的。
文档命中率说明阻止了多少通往外部网络的 Web 事务。事务有一个通常都很大的固定时间成分(比如,建立一条到服务器的 TCP 连接),提高文档命中率对降低整体延迟(时延)很有好处。
字节命中率说明阻止了多少字节传向因特网。提高字节命中率对节省带宽很有利
区分响应来自缓存还是服务器
不幸的是,HTTP 没有为用户提供一种手段来区分响应是缓存命中的,还是访问原始服务器得到的,因为这两种情况下,响应码都是 200 OK,并且响应有主体部分。
客户端可以通过三个响应头来区分是缓存还是服务器返回:
- Via 首部。有些商业代理缓存会在 Via 首部附加一些额外信息来描述缓存中发生的情况。
- Date 首部。指的是服务器响应生成的时间。将响应中 Date 首部的值与当前时间进行比较,如果响应中的日期值比较早,通常就可以认为是来自缓存的响应。
- Age 首部。客户端也可以通过 Age 首部来检测缓存的响应,指的是代理服务器对于请求资源的已缓存时间, 单位为秒。
四. 缓存拓扑结构
私有缓存与公有缓存
缓存可以是单个用户专用的,也可以是数千名用户共享的。
把缓存的服务范围进行分类,可以分为私有缓存与公有缓存。
私有缓存
私有缓存(private cache)也被称为专用缓存,包含了单个用户最常用的页面。
私有缓存不需要很大的处理能力或存储空间,这样它的成本就能比较低。
Web 浏览器中有内建的私有缓存——大多数浏览器都会将常用文档缓存在你个人电脑的磁盘和内存中,并且允许用户去配置缓存的大小和各种设置。还可以去看看浏览器的缓存中有些什么内容。
公有代理缓存
公有缓存被称为缓存代理服务器(caching proxy server),或者被称为代理缓存(proxy cache),包含了一个群体的常用页面。代理缓存会从缓存服务器本地提供文档,或者代表用户与服务器进行联系。公有缓存会接受来自多个用户的访问,所以通过它可以更好地减少冗余流量。
代理缓存可以通过指定手工代理,或者通过代理自动配置文件,将你的浏览器配置为使用代理缓存。还可以通过使用拦截代理在不配置浏览器的情况下,强制 HTTP 请求经过缓存传输。
层级结构和网状结构
层级结构
层次化的**缓存结构(hierarchy)**在实际使用中发挥了很大作用。在层级结构中,低级的缓存中未命中的请求会被导向上一级的父缓存(parent cache),由它来为剩下的那些“提炼过的”流量提供服务。
下图显示了一个两级的缓存层次结构。基本思想是在靠近客户端的地方使用小型廉价缓存,而更高层次中,则逐步采用更大、功能更强的缓存来装载多用户共享的文档。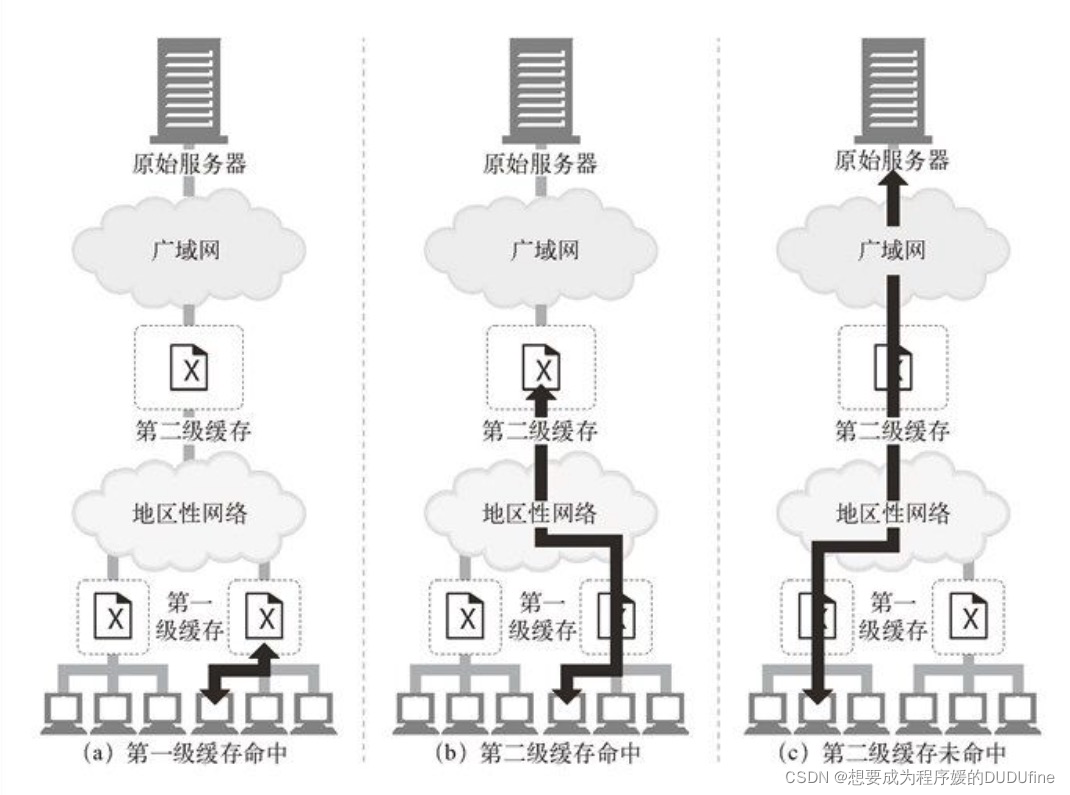
在缓存层次结构很深的情况下,请求可能要穿过很长链路的缓存,但每经过一层代理都会添加一些性能损耗,链路越长,性能损耗会变得越明显。
网状缓存
实际上网络结构会构建更为复杂的网状结构的缓存(cache mesh),而不是简单的缓存层次结构。
网状缓存中的代理缓存之间会以更加复杂的方式进行对话,做出动态的缓存通信决策,决定与哪个父缓存进行对话,或者决定彻底绕开缓存,直接连接原始服务器。这种会决定选择何种路由对内容进行访问、管理和传送的代理缓存,可将其称为内容路由器(content router)。
网状缓存中为内容路由设计的缓存主要功能有:
- 前往父缓存之前,在本地缓存中搜索已缓存的副本。
- 根据 URL 在父缓存或原始服务器之间进行动态选择。
- 根据 URL 动态地选择一个特定的父缓存。
- 允许其他缓存对其缓存的部分内容进行访问,但不允许因特网流量通过它们的缓存。
五. 缓存的处理步骤
现代的商业化代理缓存相当的复杂。这些缓存构建得非常高效,可以支持 HTTP 和其他一些技术的各种高级特性。但除了一些微妙的细节之外,Web 缓存的基本工作原理大多很简单。对一条 HTTP GET 报文的基本缓存处理过程包括 7 个步骤: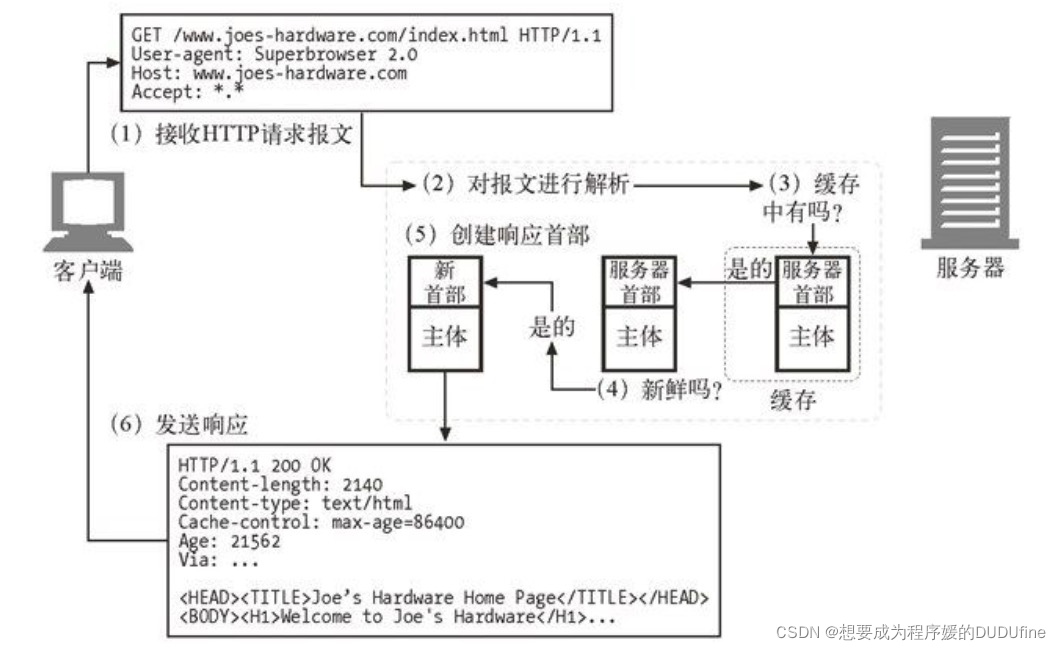
1.接收——缓存从网络中读取抵达的请求报文。
检测网络连接上的活动,读取请求数据。(高性能的缓存会同时从多条输入连接上读取数据,在整条报文抵达之前开始对事务进行处理。)
2.** 解析**——缓存对报文进行解析,提取出 URL 和各种首部。缓存将请求报文解析为片断,将首部的各个部分放入易于操作的数据结构中,这样就更容易处理首部字段并修改它们了。
3.查询——缓存获取了 URL,查找本地副本。本地副本可能存储在内存、本地磁盘,甚至附近的另一台计算机中。(专业级的缓存会使用快速算法来确定本地缓存中是否有某个对象。如果本地没有这个文档,它可以根据情形和配置,到原始服务器或父代理中去取,或者返回一条错误信息。)
已缓存对象中包含了服务器响应主体和原始服务器响应首部,这样就会在缓存命中时返回正确的服务器首部。已缓存对象中还包含了一些元数据(metadata),用来记录对象在缓存中停留了多长时间,以及它被用过多少次等。
4.新鲜度检测——缓存查看已缓存副本是否足够新鲜,如果不是,就询问服务器是否有任何更新。
HTTP 通过缓存将服务器文档的副本保留一段时间。在这段时间里,都认为文档是“新鲜的”,缓存可以在不联系服务器的情况下,直接提供该文档。但一旦已缓存副本停留的时间太长,超过了文档的新鲜度限值(freshness limit),就认为对象“过时”了,在提供该文档之前,缓存要再次与服务器进行确认,以查看文档是否发生了变化。客户端发送给缓存的所有请求首部自身都可以强制缓存进行再验证,或者完全避免验证,这使得事情变得更加复杂了。
HTTP 有一组非常复杂的新鲜度检测规则,缓存产品支持的大量配置选项,以及与非 HTTP 新鲜度标准进行互通的需要则使问题变得更加严重了。
后面我们会介绍新鲜度的计算问题。
5.创建响应——缓存会用新的首部和已缓存的主体来构建一条响应报文。
缓存将已缓存的服务器响应首部作为响应首部的起点。然后缓存对这些基础首部进行了修改和扩充。以便与客户端的要求相匹配。比如,服务器返回的可能是一条 HTTP/1.0 响应(甚至是 HTTP/0.9 响应),而客户端期待的是一条 HTTP/1.1 响应,在这种情况下,缓存必须对首部进行相应的转换。缓存还会向其中 插入新鲜度信息(Cache-Control、Age 以及 Expires 首部),而且通常会包含一个 Via 首部来说明请求是由一个代理缓存提供的。
注意,缓存不应该调整 Date 首部。Date 首部表示的是原始服务器最初产生这个对象的日期。
6.** 发送**——缓存通过网络将响应发回给客户端。
缓存处理好响应首部后,就将响应回送给客户端。
7.日志——缓存可选地创建一个日志文件条目来描述这个事务。
大多数缓存都会保存日志文件以及与缓存的使用有关的一些统计数据。比如更新缓存命中和未命中数目的统计数据(以及其他相关的度量值),记录请求类型、URL 和所发生事件的日志。
缓存处理流程图: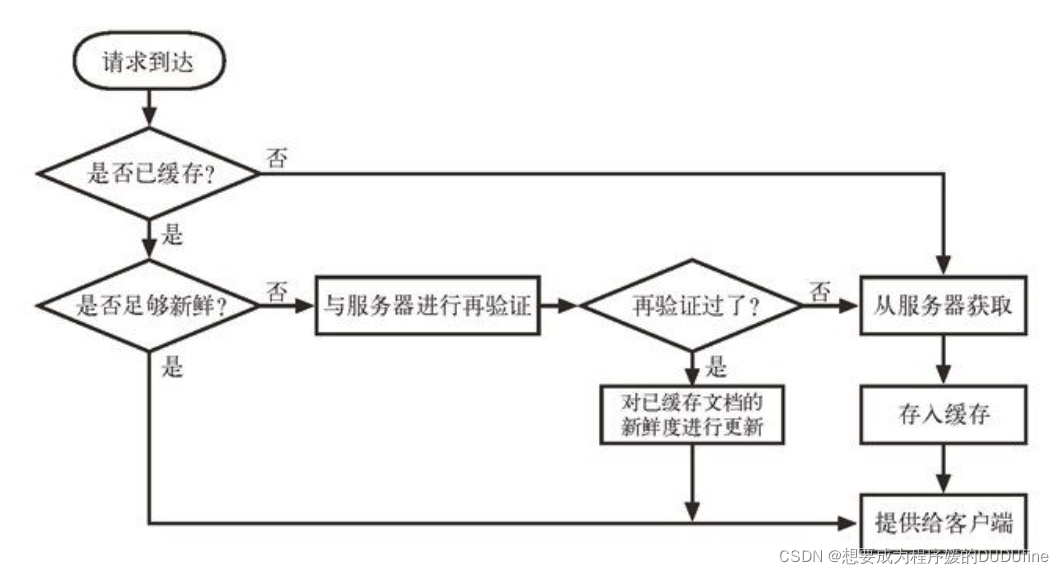
六.新鲜度设置和校验
服务器的文档会随着时间发生变化,要使缓存有效,缓存服务器上的数据也需要与服务器数据保持一致。
缓存正确工作包括了:
- “足够新鲜”的已缓存副本;
- 与服务器再验证后,确认仍然新鲜的已缓存副本;
- 如果需要与之进行再验证的原始服务器出故障了,就返回一条错误报文
如果原始的服务不可访问,但缓存需要进行再验证,那么缓存就必须返回一条错误或一条用来描述通信故障的警告报文。否则,缓存自己移除服务器上的页面未来可能会在网络缓存中存留任意长的时间。 - 附有警告信息说明内容可能不正确的已缓存副本
HTTP 有一些简单的机制可以在不要求服务器记住有哪些缓存拥有其文档副本的情况下,保持已缓存数据与服务器数据之间充分一致。HTTP 将这些简单的机制称为文档过期(document expiration)和服务器再验证(server revalidation)。
缓存有效期设置
服务器用 Expires首部(HTTP/1.0+)或 Cache-Control: max-age首部(HTTP/1.1) 响应首部来指定文档过期日期,同时还会带有响应主体。
原始服务器通过HTTP设置向每个文档附加了一个“过期日期”。在缓存的文档过期之前,缓存不需要和服务器确认,可以随意使用这些副本,除非客户端请求中包含有阻止提供已缓存或未验证资源的首部。
但一旦已缓存文档过期,缓存就必须与服务器进行核对,询问文档是否被修改过,如果被修改过,就要获取一份新鲜(带有新的过期日期)的副本。
服务器可以通过 HTTP 定义的几种方式来指定在文档过期之前可以将其缓存多长时间。按照优先级递减的顺序,服务器可以:
- 附加一个 Cache-Control: no-store 首部到响应中去;
- 附加一个 Cache-Control: no-cache 首部到响应中去;
- 附加一个 Cache-Control: must-revalidate 首部到响应中去;
- 附加一个 Cache-Control: max-age 首部到响应中去;
- 附加一个 Expires 日期首部到响应中去;
- 不附加过期信息,让缓存确定自己的过期日期。
Cache-Control头部
no-store 和 no-cache 首部
no-store 首部限制对象缓存, no-cache 首部可以防止缓存提供未经证实的已缓存对象:
Pragma: no-cache
Cache-Control: no-store
Cache-Control: no-cache
标识为 no-store 的响应会禁止缓存对响应进行复制。缓存通常会像非缓存代理服务器一样,向客户端转发一条 no-store 响应,然后删除对象。
标识为 no-cache 的响应实际上是可以存储在本地缓存区中的。只是在与原始服务器进行新鲜度再验证之前,缓存不能将其提供给客户端使用。
HTTP/1.1 中提供 Pragma: no-cache 首部 是为了兼容于 HTTP/1.0+。除了与只理解 Pragma: no-cache 的 HTTP/1.0 应用程序进行交互时,HTTP 1.1 应用程序都应该使用 Cache-Control: no-cache。
从技术上来讲,Pragma:no-cache首部只能用于HTTP请求,但在实际中,它作为拓展首部已被广泛地用于HTTP请求和响应之中。
max-age 响应首部
Cache-Control: max-age 首部表示的是从服务器将文档传来之时起,可以认为此文档处于新鲜状态的秒数。还有一个 s-maxage 首部(注意 maxage 的中间没有连字符),其行为与 max-age 类似,但仅适用于共享(公有)缓存:
Cache-Control: max-age=3600
Cache-Control: s-maxage=3600
服务器可以请求缓存不要缓存文档,或者将最大使用期设置为零,从而在每次访问的时候都会和服务器确认:
Cache-Control: max-age=0
Cache-Control: s-maxage=0
must-revalidate 响应首部
有时候为了提高性能,可以配置缓存提供一些陈旧(过期)的对象。如果原始服务器希望缓存严格遵守过期信息,可以在原始响应中附加一个 Cache-Control: must-revalidate 首部。告诉缓存严格遵守过期信息,一旦资源过期(比如已经超过max-age),在成功向原始服务器验证之前,缓存不能用该资源响应后续请求。
Cache-Control: must-revalidate
如果在缓存进行 must-revalidate 新鲜度检查时,原始服务器不可用,缓存就必须返回一条 504 Gateway Timeout 错误。
Expries
Expries: 首部表示的是文档的失效时间。
和Cache-Control: max-age 首部所做的事情本质上是一样的,但是它指定的是实际的过期日期而不是秒数,因为服务器的时钟都不同步,或者不正确,最好还是用剩余秒数,所以更倾向于使用比较新的 Cache-Control 首部。
Expires: Fri, 05 Jul 2002, 05:00:00 GMT
️注意:有些服务器还会回送一个 Expires: 0 响应首部,试图将文档置于永远过期的状态,但这种语法是非法的,可能给某些软件带来问题。
Expires VS Cache-Control: max-age:

响应报文Expires 首部和 Cache-Control 首部:
新鲜度验证
当缓存文档到了过期时间,缓存就需要和服务器进行核对服务器文档是否发生了变化,这种情况被称为“服务器再验证。
当时已缓存文档过期了并不意味着它和原始服务器上当前的最新文档不一样,所以:
- 再验证显示内容发生了变化,缓存会获取一份新的文档副本,将旧文档替换掉,然后将文档发送给客户端。
- 再验证显示内容没有发生变化,服务器只返回新的首部,包括一个新的过期日期,并且再更新缓存中的首部。
这样,缓存就不需要为每条请求验证文档的有效性——只有在文档过期时它才需要与服务器进行再验证。
用条件方法进行再验证
HTTP 定义了 5 个条件请求首部。对缓存再验证来说最有用的 2 个首部是 If-Modified-Since 和 If-None-Match。所有的条件首部都以前缀“If-”开头。下表列出了在缓存再验证中使用的条件请求首部。
其他条件首部包括IF-Unmodified-Since(在进行部分文件的传输时,获取文件的其余部分之前要确保文件未发生变化,此时这个首部是非常有用的)、IF-Range(支持对不完整文档的缓存)和IF-Match(用于与Web服务器打交道时的并发控制)
If-Modified-Since:Date再验证
最常见的缓存再验证首部是 If-Modified-Since。
If-Modified-Since 首部可以与 Last-Modified 服务器响应首部配合工作。原始服务器会将最后的修改日期附加到所提供的文档上去。当缓存要对已缓存文档进行再验证时,就会包含一个 If-Modified-Since 首部,其中携带有最后修改已缓存副本的日期:
If-Modified-Since: <cached last-modified date>
再验证请求才会指示服务器执行请求:
- 如果在指定日期后内容被修改了,最后的修改日期就会有所不同,原始服务器就会回送新的文档。If-Modified-Since 条件就为真,通常 GET 就会成功执行。携带新首部的新文档会被返回给缓存,其中新首部还包含了一个新的过期日期。
- 如果自指定日期后,缓存的最后修改日期与服务器文档当前的最后修改日期相符,服务器会向客户端返回一个小的 304 Not Modified 响应报文,为了提高效率,不会返回文档的主体,并在响应头重返回需要在源端更新的首部。比如, Content-Type 首部通常不会被修改,所以通常不需要发送。一般会发送一个新的过期日期。
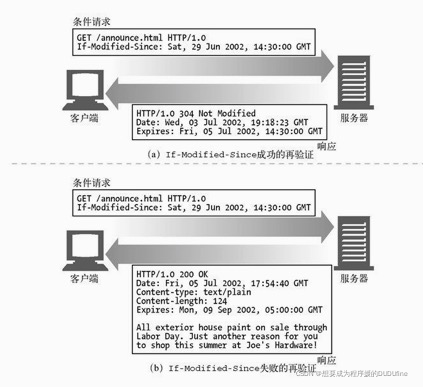
注意,有些 Web 服务器并没有将 If-Modified-Since 作为真正的日期来进行比对。相反,它们在 IMS 日期和最后修改日期之间进行了字符串匹配。这样得到的语义就是“如果最后的修改不是在这个确定的日期进行的”,而不是“如果在这个日期之后没有被修改过”。将最后修改日期作为某种序列号使用时,这种替代语义能够很好地识别出缓存是否过期,但这会妨碍客户端将 If-Modified-Since 首部用于真正基于时间的一些目的。
If-None-Match:实体标签再验证
有些情况下仅使用最后修改日期进行再验证是不够的,因为:
- 有些文档可能会被周期性地重写(比如,部署时一些内容没有变的静态文件)。尽管内容没有变化,但修改日期会发生变化。
- 有些文档可能被修改了,但所做修改并不重要,不需要让世界范围内的缓存都重装数据(比如对拼写或注释的修改)。
- 有些服务器无法准确地判定其页面的最后修改日期。
- 有些服务器提供的文档会在亚秒间隙发生变化(比如,实时监视器),对这些服务器来说,以一秒为粒度的修改日期可能就不够用了。
为了解决这些问题,用户可以在HTTP中使用实体标签(ETag)的作为“版本标识符”进行比较。实体标签是附加到文档上的任意标签(引用字符串)。它们可能包含了文档的序列号或版本名,或者是文档内容的校验和及其他指纹信息。
当发布者对文档进行修改时,可以修改文档的实体标签来说明这个新的版本。这样,如果实体标签被修改了,缓存就可以用 If-None-Match 条件首部来GET 文档的新副本了。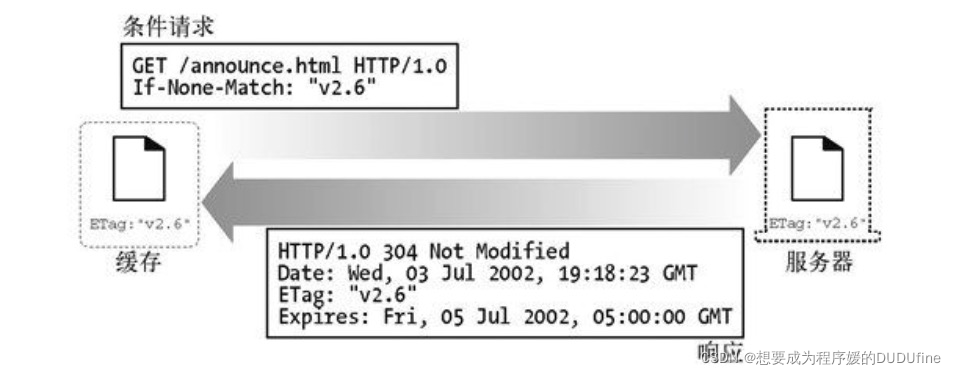
缓存中有一个实体标签为 v2.6 的文档。它会与原始服务器进行再验证,如果标签 v2.6 不再匹配,就会请求一个新对象。在图 中,标签仍然与之匹配,因此会返回一条 304 Not Modified 响应。
如果服务器上的实体标签已经发生了变化(可能变成了 v3.0),服务器会在一个 200 OK 响应中返回新的内容以及相应的新 Etag。
可以在 If-None-Match 首部包含几个实体标签,告诉服务器,缓存中已经存在带有这些实体标签的对象副本:
If-None-Match: "v2.6"
If-None-Match: "v2.4","v2.5","v2.6"
If-None-Match: "foobar","A34FAC0095","Profiles in Courage"

什么时候应该使用实体标签和最近修改日期
如果服务器回送了一个实体标签,HTTP/1.1 客户端就必须使用实体标签验证器。如果服务器只回送了一个 Last-Modified 值,客户端就可以使用 If-Modified-Since 验证。如果实体标签和最后修改日期都提供了,客户端就应该使用这两种再验证方案,这样 HTTP/1.0 和 HTTP/1.1 缓存就都可以正确响应了。
除非 HTTP/1.1 原始服务器无法生成实体标签验证器,否则就应该发送一个出去,如果使用弱实体标签有优势的话,发送的可能就是个弱实体标签,而不是强实体标签。而且,最好同时发送一个最近修改值。
如果 HTTP/1.1 缓存或服务器收到的请求既带有 If-Modified-Since,又带有实体标签条件首部,那么只有这两个条件都满足时,才能返回 304 Not Modified 响应。
强弱验证器
缓存可以用实体标签来判断,与服务器相比,已缓存版本是不是最新的(与使用最近修改日期的方式很像)。从这个角度来看,实体标签和最近修改日期都是缓存验证器(cache validator)。
有时,服务器希望在对文档进行一些非实质性或不重要的修改时,不要使所有的已缓存副本都失效。
HTTP/1.1 支持“弱验证器”,如果只对内容进行了少量修改,就允许服务器声明那是“足够好”的等价体。
只要内容发生了变化,强验证器就会变化。弱验证器允许对一些内容进行修改,但内容的主要含义发生变化时,通常它还是会变化的。有些操作不能用弱验证器来实现(比如有条件地获取部分内容),所以,服务器会用前缀“W/”来标识弱验证器。
ETag: W/"v2.6"
If-None-Match: W/"v2.6”
不管相关的实体值以何种方式发生了变化,强实体标签都要发生变化。而相关实体在语义上发生了比较重要的变化时,弱实体标签也应该发生变化。
注意,原始服务器一定不能为两个不同的实体重用一个特定的强实体标签值,或者为两个语义不同的实体重用一个特定的弱实体标签值。缓存条目可能会留存任意长的时间,与其过期时间无关,有人可能希望当缓存验证条目时,绝对不会再次使用在过去某一时刻获得的验证器,这种愿望可能不太现实。
通过 HTTP-EQUIV 控制HTML缓存
HTTP 服务器响应首部用于回送文档的到期信息以及缓存控制信息。Web 服务器与配置文件进行交互,为所提供的文档分配正确的 Cache-Control 首部。
为了让作者在无需与 Web 服务器的配置文件进行交互的情况下,能够更容易地为所提供的 HTML 文档分配 HTTP 首部信息,HTML 2.0 定义了 标签。这个可选的标签位于 HTML 文档的顶部,定义了应该与文档有所关联的 HTTP 首部。这里有一个 标签设置的例子,它将 HTML 文档标记为非缓冲的:
<HTML>
<HEAD>
<TITLE>My Document</TITLE>
<META HTTP-EQUIV="Cache-control" CONTENT="no-cache">
</HEAD>
...
最初,HTTP-EQUIV 标签是给 Web 服务器使用的。如 HTML RFC 1866 所述,Web 服务器应该为 HTML 解析 标签,并将规定的首部插入 HTTP 响应中:
HTTP 服务器可以用此信息来处理文档。特别是,它可以在为请求此文档的报文所发送的响应中包含一个首部字段:首部名称是从 HTTP-EQUIV 属性值中获取的,首部值是从 CONTENT 属性值中获取的。
不幸的是,支持这个可选特性会增加服务器的额外负载,这些值也只是静态的,而且它只支持 HTML,不支持很多其他的文件类型,所以很少有 Web 服务器和代理支持此特性。
但是,有些浏览器确实会解析并在 HTML 内容中使用 HTTP-EQUIV 标签,像对待真的 HTTP 首部那样来处理嵌入式首部。这样的效果并不好,因为支持 HTTP-EQUIV 标签的 HTML 浏览器使用的 Cache-control 规则可能会与拦截代理缓存所用的规则有所不同。这样会使缓存的过期处理行为发生混乱。
总之, 标签并不是控制文档缓存特性的好方法。通过配置正确的服务器发出HTTP 首部,是传送文档缓存控制请求的唯一可靠方法。
客户端的新鲜度限制
Web 浏览器都有** Refresh**(刷新)或** Reload**(重载)按钮,可以强制对浏览器或代理缓存中可能过期的内容进行刷新。Refresh 按钮会在GET请求头中附加了Cache-Control 首部,这个请求会强制进行再验证,或者无条件地从服务器获取文档。Refresh 的确切行为取决于特定的浏览器、文档以及拦截缓存的配置。
客户端可以用 Cache-Control 请求首部来强化或放松对过期时间的限制。有些应用程序对文档的新鲜度要求很高(比如人工刷新按钮),对这些应用程序来说,客户端可以用 Cache-Control 首部使过期时间更严格。另一方面,作为提高性能、可靠性或开支的一种折衷方式,客户端可能会放松新鲜度要求。
试探性过期
如果响应中没有 Cache-Control: max-age 首部,也没有 Expires 首部,缓存可以计算出一个试探性最大使用期。
可以使用任意算法,但如果得到的最大使用期大于 24 小时,就应该向响应首部添加一个 Heuristic Expiration Warning(试探性过期警告)首部。(但实际上很少有浏览器会为用户提供这种警告信息。)
LM-Factor 算法是一种很常用的试探性过期算法,如果文档中包含了最后修改日期,就可以使用这种算法。LM-Factor 算法将最后修改日期作为依据,来估计文档有多么易变。算法的逻辑如下所示。
- 如果已缓存文档最后一次修改发生在很久以前,它可能会是一份稳定的文档,过期时间可以比较久。
- 如果已缓存文挡最近被修改过,就说明它很可能会频繁地发生变化,缓存有效期应该比较短。
通常会为试探性新鲜周期设置上限,这样它就不会变得太大了。比较保守的站点会将这个值设置为一天或一周。
如果最后修改日期也没有的话,缓存就没什么信息可利用了。缓存就只能分配一哦胱很短的新鲜期,比如一小时、一天,或者为0,强制缓存在每次使用都需要去服务器验证。
因为很多原始服务器仍然不会产生 Expires 和 max-age 首部,所以试探性新鲜度的使用可能比你想象的要常见的多。因此选择缓存过期的默认时间时要特别小心!
注意事项
文档过期系统并不是一个完美的系统。如果发布者不小心分配了一个很久之后的过期日期,在文档过期之前,她要对文档做的任何修改都不一定能显示在所有缓存中。
文档过期采用了“生存时间”技术,这种技术用于很多的因特网协议,比如DNS中。与HTTP一样,如果发布了一个很久之后才到时的过期日期,然后发现需要进行修改,DNS就会遇到麻烦。但是,与DNS不同的是,HTTP为客户端提供了一些覆盖和强制加载机制
因此,很多发布者都不会使用很长的过期日期。而且,很多发布者甚至都不使用过期日期,这样缓存就很难确定文档会在多长时间内保持新鲜了。
边栏推荐
- 浙江大学软件学院2020年保研上机真题练习
- 解决Glide图片缓存问题,同一url换图片不起作用问题
- 用正则验证文件名是否合法
- mAPH——Waymo数据集
- 梅科尔工作室-Pr第二次培训笔记(基本剪辑操作和导出)
- 梅科尔工作室-HarmonyOS应用开发第四次培训
- 恶劣天气 3D 目标检测数据集收集
- TAMNet:A loss-balanced multi-task model for simultaneous detection and segmentation
- Waymo数据集使用介绍(waymo-open-dataset)
- Rethinking LiDAR Object Detection in adverse weather conditions
猜你喜欢




随机推荐
梅科尔工作室-Pr第一次培训笔记(安装及项目创建)
CNN-based Point Cloud De-Noising
GBase 8s与Oracle锁对比
GBase 8s共享内存中的常驻内存段
Realize data exchange between kernel and userspace through character device virtual file system (passed based on kernel 5.8 test)
OSI TCP/IP学习笔记
关于修改挂载到宿主机上的mysql配置文件不生效这件事
架构设计杂谈
Maykle Studio - Second Training in HarmonyOS App Development
微信小程序canvas画图,保存页面为海报
梅科尔工作室-深度学习第二讲 BP神经网络
Reconstruction and Synthesis of Lidar Point Clouds of Spray
Waymo数据集使用介绍(waymo-open-dataset)
SQL注入
梅科尔工作室-华为云ModelArts第一次培训
>>数据管理:读书笔记|第一章 数据管理
XSS跨站脚本攻击详解以及复现gallerycms字符长度限制短域名绕过
Severe Weather 3D Object Detection Dataset Collection
梅科尔工作室-DjangoWeb 应用框架+MySQL数据库第三次培训
第七届集美大学程序设计竞赛(个人赛)题解