当前位置:网站首页>Modify the test case name generated by DDT
Modify the test case name generated by DDT
2022-04-23 16:40:00 【Sink the wine cup and fleeting time】
modify ddt Name of generated test case
modify ddt Name of generated test case , First of all, understand ddt The logic of the generated test case name

ddt The logic of the generated test case name
Take this article as an example :DDT+Excel Conduct interface test

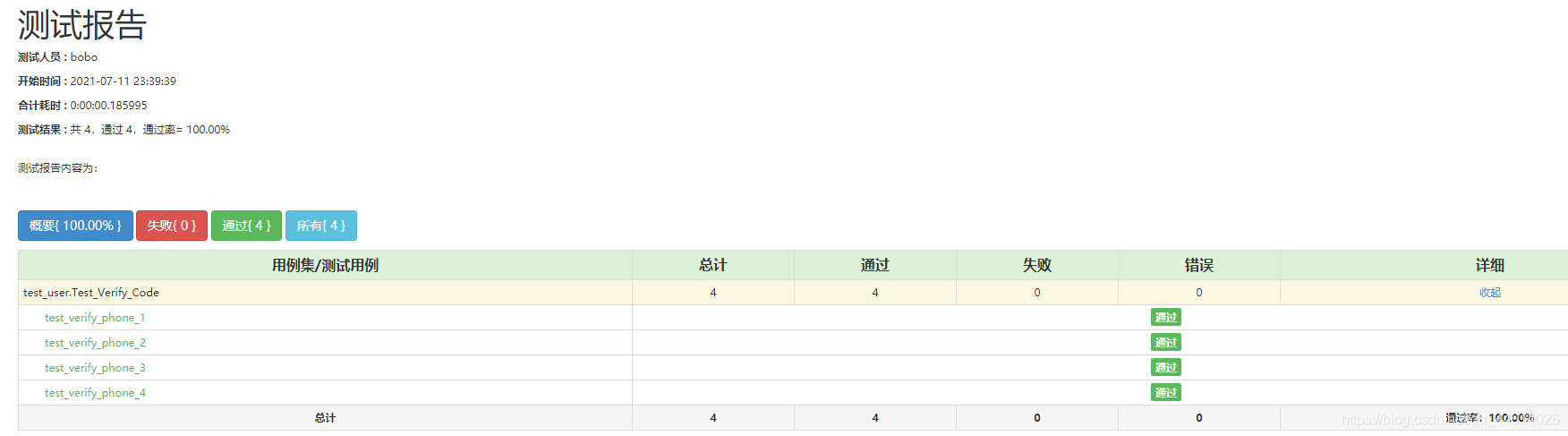
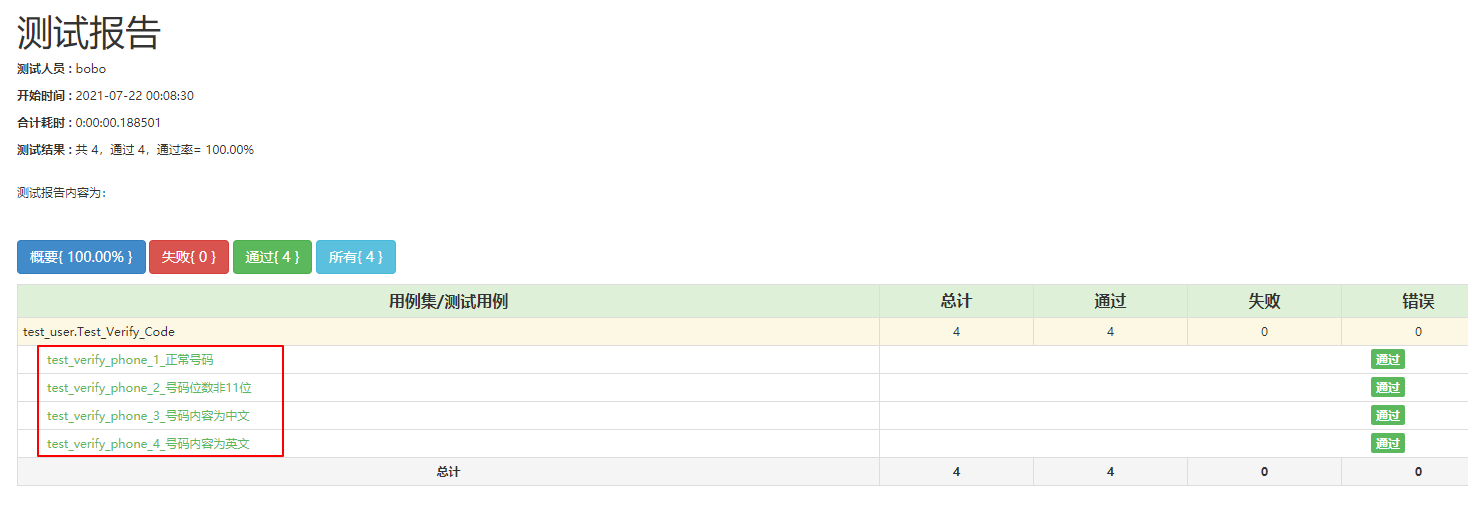
adopt ddt When verifying multiple sets of data test scenarios , Generated test report , According to the name of the test case test_verify_phone, Automatically add a number after the test case name , Such as test_verify_phone_1、test_verify_phone_2…
These numbers correspond to the test data one by one
The test case py file
@ddt.ddt
class Test_Verify_Code(unittest.TestCase):
def setUp(self) -> None:
pass
def tearDown(self) -> None:
pass
@ddt.data(*test_data)
def test_verify_phone(self,test_data):
res = HTTPHandler().visit(test_data["url"],test_data["method"],json=test_data["phonenum"])
self.assertEqual(res["code"],test_data["excepted"])
Move the mouse cursor to @ddt.data(*test_data) Of data It's about , Hold down Ctrl, Click on data It's about , View the content of the source code
Number of test data obtained
The source code file
def data(*values):
""" Method decorator to add to your test methods. Should be added to methods of instances of ``unittest.TestCase``. """
global index_len
index_len = len(str(len(values)))
return idata(values)
There is one data function , By obtaining the length of the test data ( Number ), Number of test data obtained .
stay index_len = len(str(len(values))) This line breaks , And then through DEBUG The way , Execute test case py file
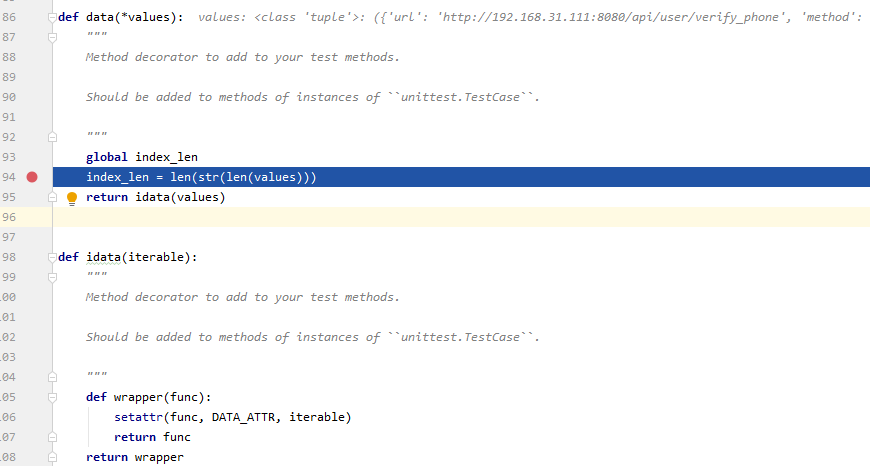
there values, It's actually test data , This is a tuple Tuple type data , There are 4 strip dict Dictionary type data
Of course , It works , Mainly the following one idata function
What this function does , Is the number of test cases generated , adopt ddt How many sets of data have been verified , How many test cases will there be
This is a return function , This function is more interesting , It's rich in content , Specific logic , A: don't get , If you are interested , You can continue to break points in key steps , Step by step debugging , View the data trend
Generated test case name
The source code file
def mk_test_name(name, value, index=0, name_fmt=TestNameFormat.DEFAULT):
index = "{0:0{1}}".format(index + 1, index_len)
if name_fmt is TestNameFormat.INDEX_ONLY or not is_trivial(value):
return "{0}_{1}".format(name, index)
try:
value = str(value)
except UnicodeEncodeError:
# fallback for python2
value = value.encode('ascii', 'backslashreplace')
test_name = "{0}_{1}_{2}".format(name, index, value)
return re.sub(r'\W|^(?=\d)', '_', test_name)
There is one mk_test_name function , The function is to : adopt ddt Generate the corresponding test case name when verifying multiple groups of data test scenarios .
index=0, At first it was 0;index + 1, Conduct +1 Handle ;
"test_name ={0}_{1}".format(name, index), This line specifies the format of the returned test case name . If you are interested , You can also make a breakpoint in this line ,DEBUG debugged
ddt Name of generated test case
Go back to the test case file , Move the mouse cursor to @ddt.ddt It's about , Hold down Ctrl, Click on the second ddt It's about , View the content of the source code
The source code file
def ddt(arg=None, **kwargs):
fmt_test_name = kwargs.get("testNameFormat", TestNameFormat.DEFAULT)
def wrapper(cls):
for name, func in list(cls.__dict__.items()):
if hasattr(func, DATA_ATTR):
for i, v in enumerate(getattr(func, DATA_ATTR)):
test_name = mk_test_name(name,getattr(v, "__name__", v),i,fmt_test_name)
test_data_docstring = _get_test_data_docstring(func, v)
if hasattr(func, UNPACK_ATTR):
if isinstance(v, tuple) or isinstance(v, list):
add_test(cls,test_name,test_data_docstring,func,*v)
else:
# unpack dictionary
add_test(cls,test_name,test_data_docstring,func,**v)
else:
add_test(cls, test_name, test_data_docstring, func, v)
delattr(cls, name)
elif hasattr(func, FILE_ATTR):
file_attr = getattr(func, FILE_ATTR)
process_file_data(cls, name, func, file_attr)
delattr(cls, name)
return cls
This is the most critical part
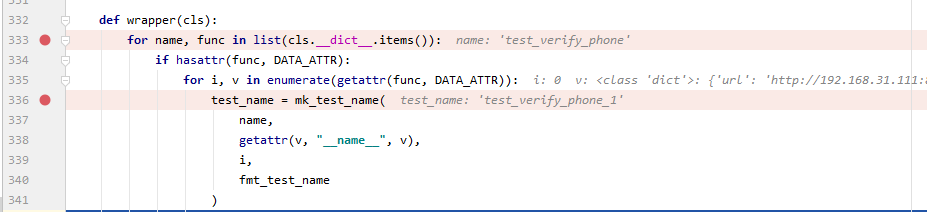
Break the point in these two lines , Debug step by step , You can find name ad locum , It's actually the name of the test case test_verify_phone,test_name Here we call mk_test_name function , therefore , stay test_verify_phone The number is added after , Now test_name = test_verify_phone_1
ddt The logic of the generated test case name , That's it . So pass ddt Test scenarios for validation , The corresponding number will be added after the test case name .
modify ddt Name of generated test case
However , This situation , Sometimes , I don't know which test scenario this test case corresponds to .
Suppose at this time , The leader said it was troublesome to read the log , I want you to describe the contents of this test report clearly , He wants to know which scene passed , Which failed , Let you change the title of the test case , What scenario does this test case test , So that he can understand at a glance .

Although I scolded him dozens of times in my heart , But in the end you have to do what he wants

In the above debugging process , You can find v This variable , It refers to the content of each set of test data , therefore , Just in each set of test data , Add the description , Then splice it to the name of the generated test case
from excel Read data , It is generally stored in the form of dictionary or list .
Judge , If the test data is list List the type , Then take the content of the first element in the list ; If the test data is dict Dictionary type , Take it from this dictionary case_name Value
therefore , modify ddt Name of generated test case , It is not difficult to
stay test_name = mk_test_name(name,getattr(v, "__name__", v),i,fmt_test_name) Just add a few lines of code
if isinstance(v, list):
test_name = mk_test_name(name, v[0], i)
elif isinstance(v, dict):
test_name = mk_test_name(name, v['case_name'], i)
Of course , We can be more rigorous , If the data read , None of them are dictionaries 、 Type of list , An exception is thrown at this time , But it doesn't affect the original ddt The function of , You can modify :
def ddt(arg=None, **kwargs):
fmt_test_name = kwargs.get("testNameFormat", TestNameFormat.DEFAULT)
def wrapper(cls):
for name, func in list(cls.__dict__.items()):
if hasattr(func, DATA_ATTR):
for i, v in enumerate(getattr(func, DATA_ATTR)):
try:
if isinstance(v, list):
test_name = mk_test_name(name, v[0], i)
elif isinstance(v, dict):
test_name = mk_test_name(name, v['case_name'], i)
except Exception as e:
test_name = mk_test_name(name,getattr(v, "__name__", v),i,fmt_test_name)
logging.exception(e)
test_data_docstring = _get_test_data_docstring(func, v)
if hasattr(func, UNPACK_ATTR):
if isinstance(v, tuple) or isinstance(v, list):
add_test(cls,test_name,test_data_docstring,func,*v)
else:
# unpack dictionary
add_test(cls,test_name,test_data_docstring,func,**v)
else:
add_test(cls, test_name, test_data_docstring, func, v)
delattr(cls, name)
elif hasattr(func, FILE_ATTR):
file_attr = getattr(func, FILE_ATTR)
process_file_data(cls, name, func, file_attr)
delattr(cls, name)
return cls
Not recommended in ddt This py Directly change the source code in the file , If this directly modifies , Can cause ddt The scenario that only fits this test case , If the data content of other test cases is not like this , An error may be reported
find ddt This py Directory of files ( Be in commonly python environment variable Under the site-packages Under the table of contents ), Make a copy of it , Put... Under the project path Common Under the table of contents , Then on Common Under the table of contents ddt.py File modification
In the test case py Under the document , modify ddt How to import :from Common import ddt such , The use of ddt function , It is the function that conforms to a test case scenario
Generate a report
版权声明
本文为[Sink the wine cup and fleeting time]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231402128466.html
边栏推荐
- Real time operation of vim editor
- Deepinv20 installation MariaDB
- Day 9 static abstract class interface
- Hypermotion cloud migration helped China Unicom. Qingyun completed the cloud project of a central enterprise and accelerated the cloud process of the group's core business system
- 欣旺达:HEV和BEV超快充拳头产品大规模出货
- What is homebrew? And use
- 各大框架都在使用的Unsafe类,到底有多神奇?
- 漫画:什么是IaaS、PaaS、SaaS?
- UWA Pipeline 功能详解|可视化配置自动测试
- Pytorch: the pit between train mode and eval mode
猜你喜欢
Take according to the actual situation, classify and summarize once every three levels, and see the figure to know the demand
![Oak-d raspberry pie cloud project [with detailed code]](/img/03/2d464d42614cd65877c645b60047ae.png)
Oak-d raspberry pie cloud project [with detailed code]
详解牛客----手套
VMware Workstation cannot connect to the virtual machine. The system cannot find the specified file
Solution of garbled code on idea console

Questions about disaster recovery? Click here

如何建立 TikTok用户信任并拉动粉丝增长
Loggie source code analysis source file module backbone analysis
MySql主从复制
Gartner 发布新兴技术研究:深入洞悉元宇宙
随机推荐
七朋元视界可信元宇宙社交体系满足多元化的消费以及社交需求
File system read and write performance test practice
阿里研发三面,面试官一套组合拳让我当场懵逼
昆腾全双工数字无线收发芯片KT1605/KT1606/KT1607/KT1608适用对讲机方案
Government cloud migration practice: Beiming digital division used hypermotion cloud migration products to implement the cloud migration project for a government unit, and completed the migration of n
Sort by character occurrence frequency 451
G008-hwy-cc-estor-04 Huawei Dorado V6 storage simulator configuration
How to choose the wireless gooseneck anchor microphone and handheld microphone scheme
On the value, breaking and harvest of NFT project
浅谈 NFT项目的价值、破发、收割之争
Download and install mongodb
RecyclerView advanced use - to realize drag and drop function of imitation Alipay menu edit page
5分钟NLP:Text-To-Text Transfer Transformer (T5)统一的文本到文本任务模型
文件系统读写性能测试实战
JSP learning 2
New project of OMNeT learning
Solution of garbled code on idea console
Creation of RAID disk array and RAID5
JMeter setting environment variable supports direct startup by entering JMeter in any terminal directory
The font of the soft cell changes color